


reft: une approche révolutionnaire des LLMS de réglage fin
reft (représentation finetuning), introduit dans le papier de May 2024 de Stanford, propose une méthode révolutionnaire pour des modèles de grande langue (LLM) efficacement affinés. Son potentiel a été immédiatement apparente, en outre mis en évidence par les bœufs.AI en juillet 2024 Expérimentation Fine-Tuning Llama3 (8b) sur un seul GPU NVIDIA A10 en seulement 14 minutes.
Contrairement aux méthodes existantes de réglage des paramètres (PEFT) comme LORA, qui modifient les poids du modèle ou l'entrée, Reft exploite la méthode d'intervention interchange distribuée (DII). DII projette des intégres dans un sous-espace à moindre dimension, permettant un réglage fin via ce sous-espace.
Cet article passe d'abord en revue les algorithmes PEFT populaires (LORA, réglage rapide, réglage du préfixe), puis explique DII, avant de plonger dans Reft et ses résultats expérimentaux.

Le visage étreint offre un aperçu complet des techniques de PEFT. Résumons brièvement les méthodes clés:
LORA (adaptation de faible rang): introduit en 2021, la simplicité et la généralisabilité de Lora en ont fait une technique de tête pour les LLM et les modèles de diffusion de réglage fin. Au lieu d'ajuster tous les poids de couche, LORA ajoute des matrices de bas rang, réduisant considérablement les paramètres d'entraînement (souvent moins de 0,3%), accélérant l'entraînement et minimisant l'utilisation de la mémoire du GPU.

Tunage rapide: Cette méthode utilise des "invites soft" - des intérêts spécifiques à la tâche approuvés - comme préfixes, permettant une prédiction efficace de plusieurs tâches sans dupliquer le modèle pour chaque tâche.
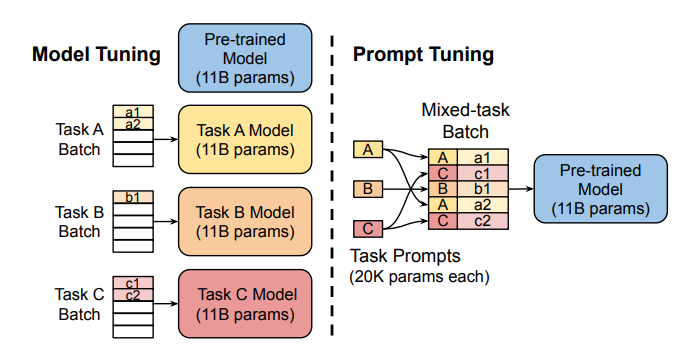
Préfixe Tuning (P-Tuning V2): Adjustant les limites du réglage rapide à l'échelle, le réglage du préfixe ajoute des intérêts invites formables à diverses couches, permettant un apprentissage spécifique à la tâche à différents niveaux.
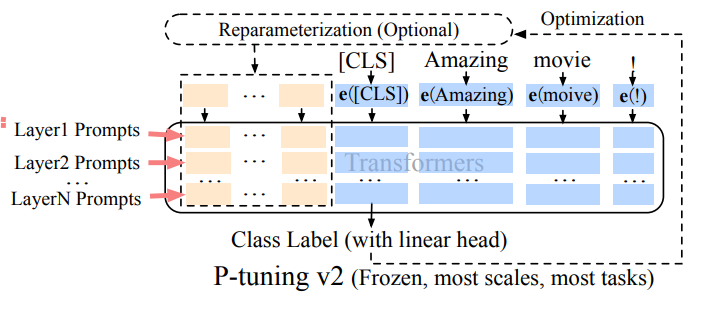
La robustesse et l'efficacité de Lora en font la méthode PEFT la plus utilisée pour les LLM. Une comparaison empirique détaillée peut être trouvée dans cet article .
DII est enraciné dans l'abstraction causale, un cadre utilisant une intervention entre un modèle de haut niveau (causal) et un modèle de bas niveau (réseau neuronal) pour évaluer l'alignement. DII projette les deux modèles en sous-espaces via des projections orthogonales, créant un modèle intervenu via des opérations de rotation. Un exemple visuel détaillé est disponible ici .
Le processus DII peut être représenté mathématiquement comme:
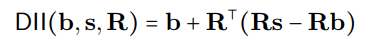
où R représente les projections orthogonales, et la recherche d'alignement distribuée (DAS) optimise le sous-espace pour maximiser la probabilité des sorties contrefactuelles attendues après l'intervention.
Reft intervient dans la représentation cachée du modèle dans un espace de dimension inférieure. L'illustration ci-dessous montre l'intervention (PHI) appliquée à la couche L et à la position P:
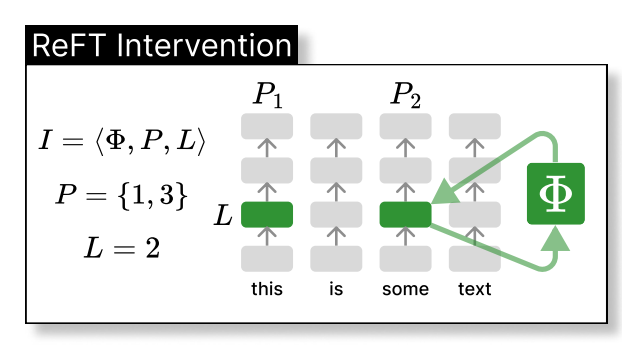
Loreft (sous-espace linéaire de faible rang Reft) présente une source projetée apprise:
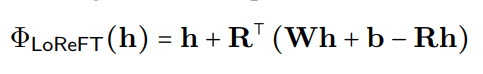
où h est la représentation cachée, et Rs édite h dans l'espace de faible dimension étendue par R. L'intégration de Loreft dans une couche de réseau neuronal est illustrée ci-dessous:
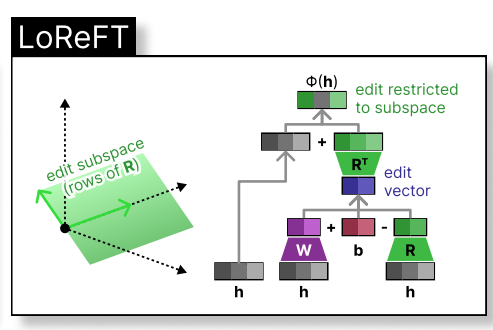
Pendant le réglage fin LLM, les paramètres LLM restent congelés et seuls les paramètres de projection (phi={R, W, b}) sont formés.
Le papier Reft original présente des expériences comparatives contre le réglage complet du réglage fin (FT), la LORA et le réglage du préfixe sur divers repères. Les techniques Reft surpassent constamment les méthodes existantes, réduisant les paramètres d'au moins 90% tout en atteignant des performances supérieures.

L'attrait de Reft découle de ses performances supérieures avec les modèles de famille lama à travers divers repères et sa mise à la terre dans l'abstraction causale, qui facilite l'interprétabilité du modèle. Reft démontre qu'un sous-espace linéaire réparti entre les neurones peut contrôler efficacement de nombreuses tâches, offrant des informations précieuses sur les LLM.
(Remarque: veuillez remplacer les espaces réservés à crochet //m.sbmmt.com/link/6c11cb78b7bbb5c22d5f5271b5494381 par les liens réels avec les documents de recherche.)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 CSS au-delà de l'affichage...
CSS au-delà de l'affichage...
 Quelle est la limite de transfert d'Alipay ?
Quelle est la limite de transfert d'Alipay ?
 Comment utiliser le survol en CSS
Comment utiliser le survol en CSS
 La différence entre indexof et include
La différence entre indexof et include
 MySQL change le mot de passe root
MySQL change le mot de passe root
 Programmation en langage de haut niveau
Programmation en langage de haut niveau
 Adresse de téléchargement du site officiel de l'application Yiou Exchange
Adresse de téléchargement du site officiel de l'application Yiou Exchange
 Comment afficher deux divs côte à côte
Comment afficher deux divs côte à côte








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



