


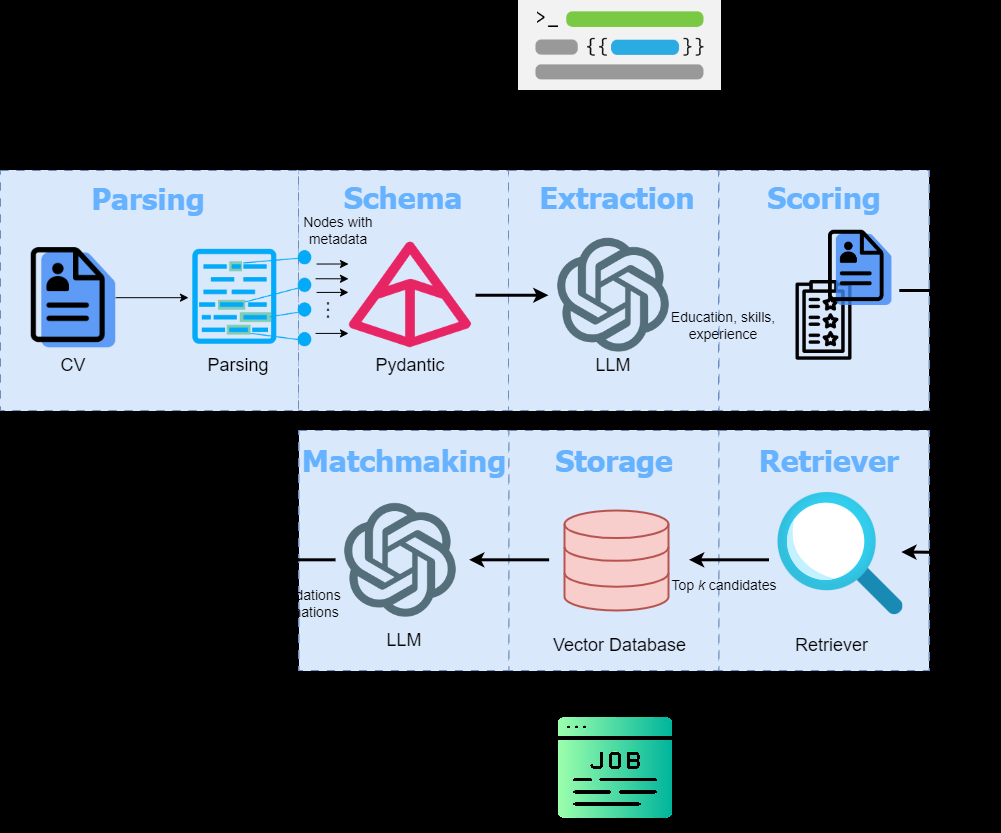
Cet article explore l'utilisation de modèles de grande langue (LLMS) pour l'extraction d'informations à partir de CV des chercheurs d'emploi et de recommander des travaux appropriés. Il exploite le llamaparse pour l'analyse des documents et le pydance pour l'extraction et la validation des données structurées, minimisant les hallucinations LLM. Le processus implique: l'extraction d'informations clés (éducation, compétences, expérience), des compétences de notation basées sur leur importance dans le CV, la création d'une base de données de vecteurs d'emploi, la récupération des principaux matchs d'emploi basés sur la similitude sémantique et la génération de recommandations avec des explications utilisant un LLM.
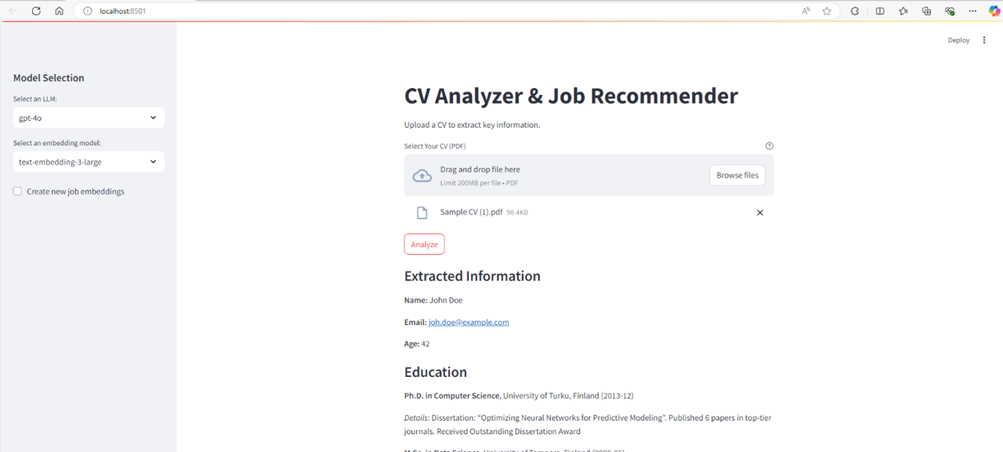
Une application Streamlit permet aux utilisateurs de télécharger un CV (PDF), SELECT LLMS (Openai's gpt-4o ou alternatives open-source) et les modèles d'intégration. L'application extrait ensuite le profil du candidat, calcule les scores de compétences (affichés comme une note d'étoile) et fournit des recommandations d'emploi les plus élevées. Le code utilise l'API d'Openai pour le modèle d'intégration gpt-4o LLM et text-embedding-3-large, mais offre une flexibilité pour utiliser des alternatives open source avec un GPU compatible Cuda.
L'article détaille les modèles pydantiques pour l'extraction structurée des données, présentant leur utilisation dans la validation de la sortie LLM et la cohérence des données. Il explique le processus de création d'une base de données de vecteur d'emploi à partir d'un ensemble de données JSON organisé (sample_jobs.json) et d'utiliser la similitude du cosinus avec les compétences de score en fonction de leur pertinence sémantique au sein du CV. Les recommandations d'emplois finales sont générées à l'aide d'une approche de génération (RAG) (RAG) de récupération, combinant les informations de profil extraites avec des descriptions de travail pertinentes de la base de données vectorielle.
L'application Streamlit affiche les informations sur le profil extrait (nom, e-mail, âge, éducation, compétences, expérience) et les meilleurs matchs d'emploi, y compris les détails de l'entreprise, les descriptions de poste, l'emplacement, le type d'emploi, la gamme de salaire (si disponible), l'URL et une brève explication du match. Les scores de compétences sont représentés visuellement à l'aide d'un système d'évaluation des étoiles.
L'article conclut en suggérant des domaines pour l'amélioration et l'expansion, notamment: l'amélioration du pipeline d'ingestion de base de données de l'emploi, en élargissant les informations de profil extraites de CVS, en affinant la méthode de score des compétences, en prolongeant l'application pour faire correspondre les publicités avec les profils des candidats, les tests L'application avec divers formats CV et fournissant des recommandations d'amélioration et de mise à jour CV. Le code complet est disponible sur GitHub. L'auteur encourage les lecteurs à applaudir, à les commenter et à les suivre sur Medium et LinkedIn.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 CSS au-delà de l'affichage...
CSS au-delà de l'affichage...
 Quelle est la limite de transfert d'Alipay ?
Quelle est la limite de transfert d'Alipay ?
 Comment utiliser le survol en CSS
Comment utiliser le survol en CSS
 La différence entre indexof et include
La différence entre indexof et include
 MySQL change le mot de passe root
MySQL change le mot de passe root
 Programmation en langage de haut niveau
Programmation en langage de haut niveau
 Adresse de téléchargement du site officiel de l'application Yiou Exchange
Adresse de téléchargement du site officiel de l'application Yiou Exchange
 Comment afficher deux divs côte à côte
Comment afficher deux divs côte à côte








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



