


Divide and Conquer (pide&Conquer), RéférenceAlgorithme Big data : Tri de 500 millions de données
Triez ce total.txt avec 500 000 000 de lignes La taille du fichier est de 4,6 Go.
Triez et écrivez dans un nouveau sous-fichier chaque fois que 10 000 lignes sont lues (ici nous utilisons tri rapide).
#!/usr/bin/python2.7
import time
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def quick_sort(lst):
if len(lst) < 2:
return lst
pivot = lst[0]
left = [ ele for ele in lst[1:] if ele < pivot ]
right = [ ele for ele in lst[1:] if ele >= pivot ]
return quick_sort(left) + [pivot,] + quick_sort(right)
def split_bfile(bfile):
count = 0
nums = []
for line in readline_by_yield(bfile):
num = int(line)
if num not in nums:
nums.append(num)
if 10000 == len(nums):
nums = quick_sort(nums)
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write('\n'.join([ str(i) for i in nums ]))
nums[:] = []
count += 1
print count
now = time.time()
split_bfile('total.txt')
run_t = time.time()-now
print 'Runtime : {}'.format(run_t)générera 50 000 petits fichiers, chaque petit fichier mesure environ 96 Ko.
Lors de l'exécution du programme, l'utilisation de la mémoire a été de 5424 Ko environ

Il a fallu 94146 secondes pour terminer le fractionnement de l'ensemble du fichier.
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
import os
import time
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行,即当前文件最小值
nums = []
tmp_nums = []
for fd in fds:
num = int(fd.readline())
tmp_nums.append(num)
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
count = 0
while 1:
val = min(tmp_nums)
nums.append(val)
idx = tmp_nums.index(val)
next = fds[idx].readline()
# 文件读完了
if not next:
del fds[idx]
del tmp_nums[idx]
else:
tmp_nums[idx] = int(next)
# 暂存区保存1000个数,一次性写入硬盘,然后清空继续读。
if 1000 == len(nums):
with open('final_sorted.txt','a') as wf:
wf.write('\n'.join([ str(i) for i in nums ]) + '\n')
nums[:] = []
if 499999999 == count:
break
count += 1
with open('runtime.txt','w') as wf:
wf.write('Runtime : {}'.format(time.time()-now)), l'utilisation de la mémoire a été d'environ 240M
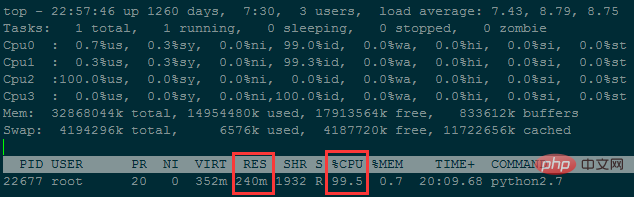

Il a fallu environ 38 heures pour fusionner moins de 50 millions de lignes de données. .
Bien que l'utilisation de la mémoire soit réduite, la complexité temporelle est trop élevée ; L'utilisation de la mémoire peut être encore réduite en réduisant le nombre de fichiers (le nombre de lignes stockées dans chaque petit fichier augmente).
# 方法一:手动计算
In [62]: ip
Out[62]: '10.3.81.150'
In [63]: ip.split('.')[::-1]
Out[63]: ['150', '81', '3', '10']
In [64]: [ '{}-{}'.format(idx,num) for idx,num in enumerate(ip.split('.')[::-1]) ]
Out[64]: ['0-150', '1-81', '2-3', '3-10']
In [65]: [256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])]
Out[65]: [150, 20736, 196608, 167772160]
In [66]: sum([256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])])
Out[66]: 167989654
In [67]:
# 方法二:使用C扩展库来计算
In [71]: import socket,struct
In [72]: socket.inet_aton(ip)
Out[72]: b'\n\x03Q\x96'
In [73]: struct.unpack("!I", socket.inet_aton(ip))
# !表示使用网络字节顺序解析, 后面的I表示unsigned int, 对应Python里的integer or long
Out[73]: (167989654,)
In [74]: struct.unpack("!I", socket.inet_aton(ip))[0]
Out[74]: 167989654
In [75]: socket.inet_ntoa(struct.pack("!I", 167989654))
Out[75]: '10.3.81.150'
In [76]:Idée de base : lisez les gros fichiers de manière itérative, divisez les gros fichiers en plusieurs petits fichiers et enfin fusionnez ces petits fichiers.
Règles de fractionnement :
Lisez les fichiers volumineux de manière itérative et conservez un dictionnaire en mémoire. La clé est une chaîne et la valeur est le nombre d'occurrences de la chaîne
Lorsque le nombre de types de chaînes conservés dans le dictionnaire. atteint 10 000 (peut être automatiquement lors de la définition), triez le dictionnaire par clé de petit à grand , puis écrivez-le dans un petit fichier, chaque ligne est la valeur clé
Ensuite, effacez le dictionnaire et continuez à lire jusqu'au gros fichier ; est terminé.
Règles de fusion :
Obtenez d'abord les descripteurs de fichiers de tous les petits fichiers, puis lisez la première ligne (c'est-à-dire la chaîne avec la plus petite valeur ascii de chaque petite chaîne de fichier) pour comparaison.
Trouvez la chaîne avec la plus petite valeur ascii. S'il y a des doublons, additionnez le nombre d'occurrences, puis stockez la chaîne actuelle et le nombre total de fois dans une liste en mémoire.
Déplacez ensuite le pointeur de lecture du fichier où se trouve la plus petite chaîne vers le bas, c'est-à-dire lisez une autre ligne du petit fichier correspondant pour le prochain tour de comparaison.
Lorsque le nombre de listes en mémoire atteint 10 000, le contenu de la liste est immédiatement écrit dans un fichier final et stocké sur le disque dur. En même temps, effacez la liste pour des comparaisons ultérieures.
Jusqu'à ce que tous les petits fichiers aient été lus, le fichier final est un gros fichier trié par ordre croissant en fonction de la valeur ascii de la chaîne. Le contenu de chaque ligne est le nombre de répétitions de la chaîne t,
itération finale. à lire Pour ce fichier final, trouvez simplement celui qui comporte le plus de répétitions.
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def split_bfile(bfile):
count = 0
d = {}
for line in readline_by_yield(bfile):
line = line.strip()
if line not in d:
d[line] = 0
d[line] += 1
if 10000 == len(d):
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write(text.strip())
d.clear()
count += 1
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile_end.txt','w') as wf:
wf.write(text.strip())
split_bfile('bigfile.txt')import os
import json
import time
import traceback
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行
tmp_strings = []
tmp_count = []
for fd in fds:
line = fd.readline()
string,count = line.strip().split('\t')
tmp_strings.append(string)
tmp_count.append(int(count))
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
result = []
need2del = []
while True:
min_str = min(tmp_strings)
str_idx = [i for i,v in enumerate(tmp_strings) if v==min_str]
str_count = sum([ int(tmp_count[idx]) for idx in str_idx ])
result.append('{}\t{}\n'.format(min_str,str_count))
for idx in str_idx:
next = fds[idx].readline() # IndexError: list index out of range
# 文件读完了
if not next:
need2del.append(idx)
else:
next_string,next_count = next.strip().split('\t')
tmp_strings[idx] = next_string
tmp_count[idx] = next_count
# 暂存区保存10000个记录,一次性写入硬盘,然后清空继续读。
if 10000 == len(result):
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []
# 注意: 文件读完需要删除文件描述符的时候, 需要逆序删除
need2del.reverse()
for idx in need2del:
del fds[idx]
del tmp_strings[idx]
del tmp_count[idx]
need2del[:] = []
if 0 == len(fds):
break
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []Analyse des résultats de fusion :
| 分割时内存中维护的字典大小 | 分割的小文件个数 | 归并时需维护的文件描述符个数 | 归并时内存占用 | 归并耗时 | |
| 第一次 | 10000 | 9000 | 9000 ~ 0 | 200M | 归并速度慢,暂未统计完成时间 |
| 第二次 | 100000 | 900 | 900 ~ 0 | 27M | 归并速度快,只需2572秒 |
3. Trouvez la chaîne avec le plus d'occurrences et son numéro
import time
def read_line(filepath):
with open(filepath,'r') as rf:
for line in rf:
yield line
start_ts = time.time()
max_str = None
max_count = 0
for line in read_line('merged.txt'):
string,count = line.strip().split('\t')
if int(count) > max_count:
max_count = int(count)
max_str = string
print(max_str,max_count)
print('Runtime {}'.format(time.time()-start_ts))Le fichier fusionné a un total de 9999788 lignes et sa taille. est de 256 Mo ; la recherche a pris 27 secondes et a occupé 6 480 Ko de mémoire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment créer un lien symbolique
Comment créer un lien symbolique
 Méthode d'enregistrement du compte Google
Méthode d'enregistrement du compte Google
 paramètres des variables d'environnement Java
paramètres des variables d'environnement Java
 Que faire si Chrome ne peut pas charger les plugins
Que faire si Chrome ne peut pas charger les plugins
 Comment récupérer l'historique du navigateur sur un ordinateur
Comment récupérer l'historique du navigateur sur un ordinateur
 supprimer le dossier sous Linux
supprimer le dossier sous Linux
 commande utilisateur du commutateur Linux
commande utilisateur du commutateur Linux
 Classement des dix principaux échanges de devises numériques
Classement des dix principaux échanges de devises numériques








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



