


En développement commercial, nous sommes souvent confrontés au problème de la prévention des demandes répétées. Lorsque la réponse du serveur à une requête implique une modification des données ou un changement de statut, cela peut causer de graves dommages. Les conséquences de demandes répétées sont particulièrement graves dans les systèmes de transaction, la protection des droits après-vente et les systèmes de paiement.
La gigue dans les opérations de premier plan, les opérations rapides, la communication réseau ou la réponse lente du back-end augmenteront la probabilité d'un traitement répété dans le back-end. Pour prendre des mesures pour éviter le rebond des opérations frontales et empêcher les opérations rapides, nous pensons d'abord à une couche de contrôle sur le front-end. Lorsque le frontal déclenche une opération, une interface de confirmation peut apparaître, ou l'entrée peut être désactivée et le compte à rebours, etc. ne sera pas détaillé ici. Cependant, les restrictions du front-end ne peuvent résoudre qu'une petite partie des problèmes et ne sont pas suffisamment approfondies. Les mesures anti-duplication du back-end sont indispensables et obligatoires.
Dans l'implémentation de l'interface, nous exigeons souvent que l'interface réponde à l'idempotence pour garantir qu'une seule des requêtes répétées est valide.
L'interface de la classe de requête est presque toujours idempotente, mais lorsqu'elle inclut l'insertion de données et la mise à jour des données multi-modules, il sera plus difficile d'atteindre l'idempotence, en particulier les exigences d'idempotence en cas de concurrence élevée. Par exemple, les rappels front-end et en arrière-plan des paiements tiers, les rappels par lots de paiements tiers, la lenteur de la logique métier (telle que les utilisateurs soumettant des demandes de remboursement, les commerçants acceptant de retourner/rembourser, etc.) ou les environnements réseau lents sont très fréquents. scénarios de risque pour un traitement répété.
Voici un exemple "d'utilisateur soumettant une demande de remboursement" pour illustrer l'effet de la méthode de traitement anti-duplication essayée. Nous avons essayé trois méthodes de traitement anti-duplication back-end :
Cette méthode est simple et intuitive et est interrogée depuis la base de données Refund. les détails (y compris le statut) peuvent souvent également être utilisés dans une logique ultérieure, sans dépenser de travail supplémentaire spécifiquement pour traiter les demandes répétées.
Ce type de logique de vérification après interrogation du statut est présent dans tous les traitements de logique métier contenant le statut depuis la mise en ligne du code et est essentiel. Cependant, l'effet du traitement anti-duplication n'est pas bon : avant d'ajouter la soumission anti-duplication sur le front-end, le nombre moyen était de 25 par semaine ; après l'optimisation du front-end, il est tombé à 7 par semaine ; Ce nombre représente 3% du nombre total de demandes de remboursement, une proportion qui reste encore inacceptable.
Théoriquement, tant qu'une requête termine l'opération de requête avant que l'état des données ne soit mis à jour, un traitement répété de la logique métier se produira. Comme indiqué ci-dessous. L'orientation de l'optimisation consiste à réduire le temps de traitement métier entre la requête et la mise à jour, ce qui peut réduire l'impact de la simultanéité de la période d'intervalle. Dans le cas extrême, si les requêtes et les mises à jour deviennent des opérations atomiques, notre problème actuel n’existera pas.
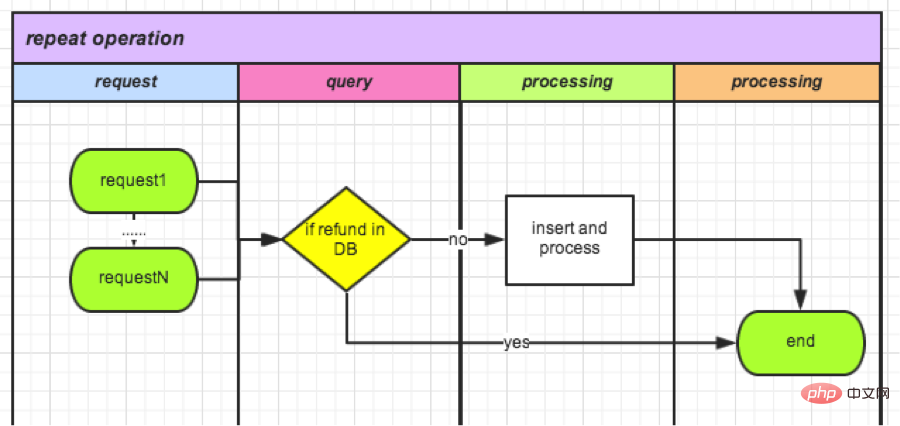
La requête de stockage Redis est légère et rapide. Lorsque la demande arrive, elle peut d'abord être enregistrée dans le cache. Les demandes entrantes ultérieures seront vérifiées à chaque fois. L'ensemble du processus est terminé et le cache est vidé. Prenons l'exemple du remboursement :
Par rapport à 1), la base de données est remplacée par un cache qui répond plus rapidement. Mais il ne s’agit toujours pas d’une opération atomique. Il y a encore un intervalle de temps entre l'insertion et la lecture du cache. Dans les cas extrêmes, il existe encore des opérations répétées. Une fois cette méthode optimisée, l’opération sera répétée une fois par semaine.
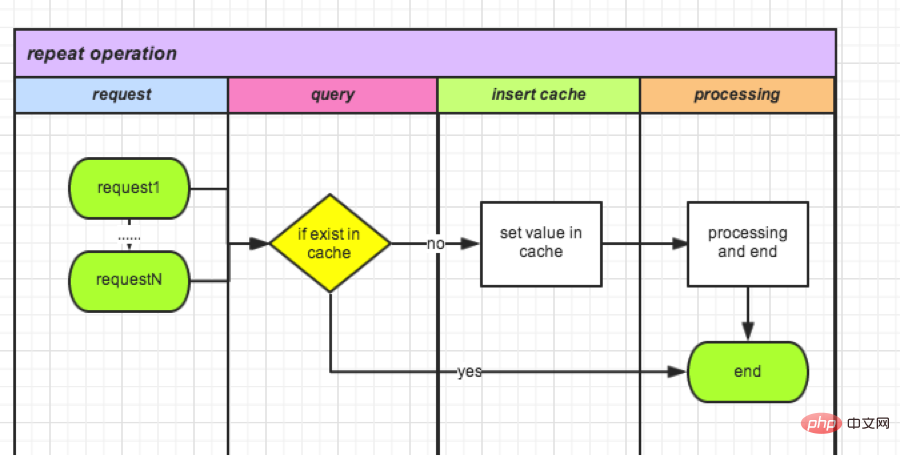
nécessite des opérations atomiques, donc l'index unique de la base de données vient à l'esprit. Créez une nouvelle table TradeLock :
CREATE TABLE `TradeLock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `type` int(11) NOT NULL COMMENT '锁类型', `lockId` int(11) NOT NULL DEFAULT '0' COMMENT '业务ID', `status` int(11) NOT NULL DEFAULT '0' COMMENT '锁状态', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='Trade锁机制';
● Chaque fois qu'une demande arrive, insérez des données dans la table :
成功,则可以继续操作(相当于获取锁); 失败,则说明有操作在进行。
● Une fois l'opération terminée, supprimez cet enregistrement. (Équivaut à déverrouiller le verrou).
Il est désormais en ligne, en attendant les statistiques des données la semaine prochaine.
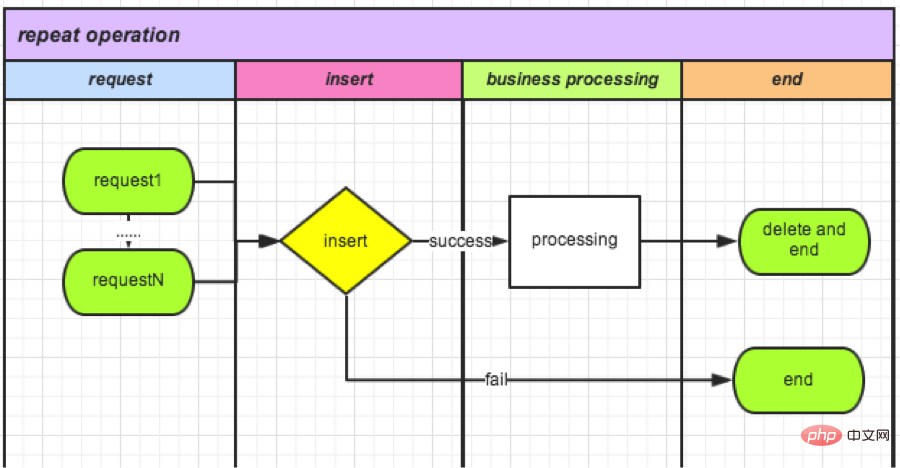
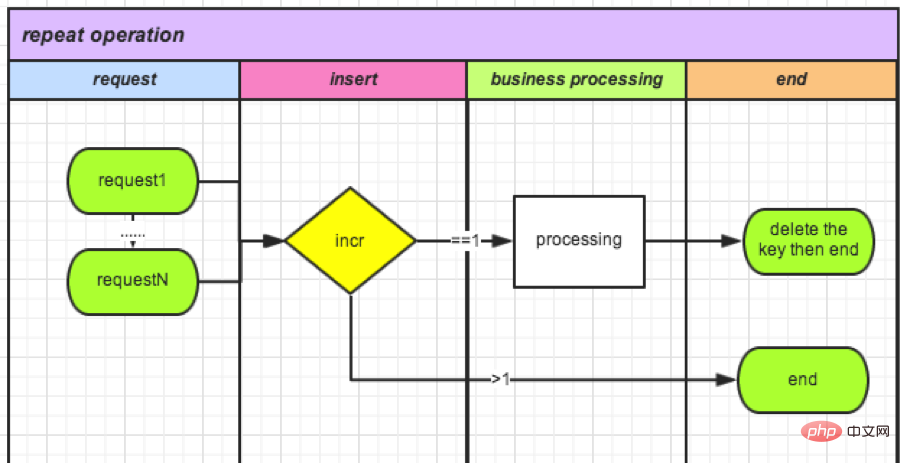
Étant donné que les opérations de base de données sont relativement gourmandes en performances, nous avons appris que les compteurs Redis sont également des opérations atomiques. Utilisez les compteurs de manière décisive. Cela peut non seulement améliorer les performances, mais également éliminer le besoin de stockage et augmenter le pic de qps.
Prenons comme exemple le remboursement de la commande :
● Chaque fois qu'une demande arrive, un nouveau compteur avec orderId comme clé est créé, puis +1.
如果>1(不能获得锁): 说明有操作在进行,删除。 如果=1(获得锁): 可以操作。
● Fin de l'opération (supprimer le verrouillage) : Supprimez ce compteur.
要了解计数器,可以参考:http://www.redis.cn/commands/incr.html
PHP语言自身没有提供进程互斥和锁定机制。因此才有了我们上面的尝试。网上也有文件锁机制,但是考虑到我们的分布式部署,建议还是用缓存。在大并发的情况下,程序各种情况的发生。特别是涉及到金额操作,不能有一分一毫的差距。所以在大并发要互斥的情况下可以考虑3、4两种方案。
爱迪生尝试了1600多种材料选择了钨丝发明了灯泡,实践出真知。遇到问题,和问题斗争,最后解决问题是一个最大提升自我的过程,不但加宽自己的知识广度,更加深了自己的技能深度。达到目标之后的成就感更是不言而喻。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



