La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Ce travail a été parrainé par le membre IEEE du National Key Laboratory. d'intelligence cognitive réalisé par l'équipe de Chen Enhong et le laboratoire Arche de Noé de Huawei. L’équipe du professeur Chen Enhong est profondément engagée dans les domaines de l’exploration de données et de l’apprentissage automatique et a publié de nombreux articles dans des revues et conférences de premier plan. Les articles de Google Scholar ont été cités plus de 20 000 fois. Le Noah's Ark Laboratory est le laboratoire de Huawei engagé dans la recherche fondamentale sur l'intelligence artificielle. Il adhère au concept d'importance égale accordée à la recherche théorique et à l'innovation applicative, et s'engage à promouvoir l'innovation et le développement technologiques dans le domaine de l'intelligence artificielle. Lors de la 30e Conférence ACM sur la découverte des connaissances et l'exploration de données (KDD2024) qui s'est tenue à Barcelone, en Espagne, du 25 au 29 août, le professeur Chen Enhong du Laboratoire national clé d'intelligence cognitive de l'Université de la science et de la technologie de Chine, membre de l'IEEE, l'article « Dataset Regeneration for Sequential Recommendation » publié conjointement avec Huawei Noah a remporté le seul prix du meilleur article étudiant dans le volet recherche de la conférence 2024. Les premiers auteurs de l'article sont le professeur Chen Enhong et le professeur Lian Defu du Laboratoire national clé d'intelligence cognitive de l'Université des sciences et technologies de Chine, ainsi que le doctorant Yin Mingjia, co-supervisé par Wang Haote en tant que chercheur associé. Huawei Noah Liu Yong et le chercheur Guo Wei ont également participé aux travaux connexes. C’est la deuxième fois que les étudiants de l’équipe du professeur Chen Enhong remportent ce prix depuis sa création en 2004.

- Lien papier : https://arxiv.org/abs/2405.17795
- Lien code : https://github.com/USTC -StarTeam/DR4SR
Recommandation de séquence Le système (Sequential Recommender, SR) est un élément important des systèmes de recommandation modernes car il vise à capturer les préférences changeantes des utilisateurs. Ces dernières années, les chercheurs ont déployé de nombreux efforts pour améliorer les capacités des systèmes de recommandation de séquences. Ces méthodes suivent généralement un paradigme centré sur le modèle, qui consiste à développer des modèles efficaces basés sur des ensembles de données fixes. Cependant, cette approche néglige souvent les problèmes de qualité potentiels et les défauts des données. Afin de résoudre ces problèmes, les milieux universitaires ont proposé un paradigme centré sur les données, qui se concentre sur l'utilisation de modèles fixes pour générer des ensembles de données de haute qualité. Nous appelons cela le problème de la « reconstruction d’un ensemble de données ». Afin d'obtenir les meilleures données d'entraînement, l'idée clé de l'équipe de recherche est d'apprendre un nouvel ensemble de données contenant explicitement des modèles de transfert d'éléments. Plus précisément, ils ont divisé le processus de modélisation du système de recommandation en deux étapes : extraire les modèles de transfert 〈🎜〉 de l'ensemble de données d'origine et apprendre les préférences de l'utilisateur 〈🎜〉 basées sur 〈🎜〉. Ce processus est difficile car l'apprentissage d'un mappage à partir de  implique deux mappages implicites :
implique deux mappages implicites :  . À cette fin, l'équipe de recherche a exploré la possibilité de développer un ensemble de données qui représente explicitement les modèles de transfert d'éléments dans
. À cette fin, l'équipe de recherche a exploré la possibilité de développer un ensemble de données qui représente explicitement les modèles de transfert d'éléments dans  , ce qui nous permet de séparer explicitement le processus d'apprentissage en deux étapes, où
, ce qui nous permet de séparer explicitement le processus d'apprentissage en deux étapes, où  est relativement plus facile à apprendre. Par conséquent, leur objectif principal est d’apprendre une fonction de mappage efficace pour
est relativement plus facile à apprendre. Par conséquent, leur objectif principal est d’apprendre une fonction de mappage efficace pour  , qui est un mappage un-à-plusieurs. L'équipe de recherche définit ce processus d'apprentissage comme le paradigme de régénération des ensembles de données, comme le montre la figure 1, où « régénération » signifie qu'elles n'introduisent aucune information supplémentaire et s'appuient uniquement sur l'ensemble de données d'origine.
, qui est un mappage un-à-plusieurs. L'équipe de recherche définit ce processus d'apprentissage comme le paradigme de régénération des ensembles de données, comme le montre la figure 1, où « régénération » signifie qu'elles n'introduisent aucune information supplémentaire et s'appuient uniquement sur l'ensemble de données d'origine. 

 Figure 1 Le paradigme central, Dataset Regénération for Sequence Recommendation (DR4SR) , vise à reconstruire l'ensemble de données d'origine en un ensemble de données informatif et généralisable. Plus précisément, l’équipe de recherche a d’abord construit une tâche de pré-formation pour permettre de régénérer l’ensemble de données. Ensuite, ils ont proposé un régénérateur amélioré par la diversité pour modéliser les relations un-à-plusieurs entre les séquences et les modèles au cours du processus de régénération. Enfin, ils proposent une stratégie d’inférence hybride pour trouver un équilibre entre exploration et exploitation afin de générer de nouveaux ensembles de données.
Figure 1 Le paradigme central, Dataset Regénération for Sequence Recommendation (DR4SR) , vise à reconstruire l'ensemble de données d'origine en un ensemble de données informatif et généralisable. Plus précisément, l’équipe de recherche a d’abord construit une tâche de pré-formation pour permettre de régénérer l’ensemble de données. Ensuite, ils ont proposé un régénérateur amélioré par la diversité pour modéliser les relations un-à-plusieurs entre les séquences et les modèles au cours du processus de régénération. Enfin, ils proposent une stratégie d’inférence hybride pour trouver un équilibre entre exploration et exploitation afin de générer de nouveaux ensembles de données. Le processus de reconstruction de l'ensemble de données est général, mais peut ne pas être complètement adapté à un modèle cible spécifique. Pour résoudre ce problème, l'équipe de recherche a proposé DR4SR+, un processus de régénération sensible au modèle qui adapte l'ensemble de données en fonction des caractéristiques du modèle cible. DR4SR+ personnalise la notation et optimise les modèles de l'ensemble de données reconstruit grâce à un problème d'optimisation à deux couches et des techniques de différenciation implicite pour améliorer l'effet de l'ensemble de données.
Dans cette étude, l'équipe de recherche a proposé une analyse de données- Un cadre centré sur la régénération des données pour la recommandation de séquence (DR4SR) vise à reconstruire l'ensemble de données d'origine en un ensemble de données informatif et généralisable, comme le montre la figure 2. Étant donné que le processus de régénération des données est indépendant du modèle cible, l'ensemble de données régénéré ne répond pas nécessairement aux exigences du modèle cible. Par conséquent, l’équipe de recherche a étendu DR4SR dans une version sensible au modèle, à savoir DR4SR+, pour adapter l’ensemble de données régénéré au modèle cible spécifique.
Reconstruction d'ensembles de données indépendantes du modèle Figure 2 pour faciliter la régénération automatique des ensembles de données. Cependant, il y a un manque d'informations de supervision dans l'ensemble de données d'origine pour apprendre le régénérateur d'ensemble de données. Ils doivent donc y parvenir de manière auto-supervisée. À cette fin, ils introduisent une tâche de pré-formation pour guider l’apprentissage du régénérateur amélioré par la diversité. Après avoir terminé la pré-formation, l’équipe de recherche a ensuite utilisé une stratégie d’inférence hybride pour régénérer un nouvel ensemble de données.
Construction de la tâche de pré-formation sur la reconstruction des données :
Figure 3 Ensuite, le régénérateur est nécessaire pour pouvoir régénérer dans le motif correspondant . L'équipe de recherche désigne l'ensemble des données de pré-formation comme

 Régénérateur qui favorise la diversité :
Régénérateur qui favorise la diversité : 

Avec tâches de pré-formation, les équipes de recherche peuvent désormais pré-former un régénérateur d'ensembles de données. Dans cet article, ils adoptent le modèle Transformer comme architecture principale du régénérateur, et sa capacité de génération a été largement vérifiée. Le régénérateur d'ensemble de données se compose de trois modules : un encodeur pour obtenir des représentations de séquence dans l'ensemble de données d'origine, un décodeur pour régénérer les modèles et un module d'amélioration de la diversité pour capturer les relations de mappage un à plusieurs. Ensuite, l'équipe de recherche présentera ces modules séparément.
L'encodeur se compose de plusieurs couches empilées d'auto-attention multi-têtes (MHSA) et de réseau à action directe (FFN). Quant au décodeur, il reproduira les modèles de l'ensemble de données X' en entrée. Le but du décodeur est de reconstruire le motif étant donné la représentation de la séquence générée par l'encodeur. Cependant, plusieurs motifs peuvent être extraits d'une séquence. ., ce qui peut créer des défis lors de l’entraînement. Afin de résoudre ce problème de cartographie un-à-plusieurs, l’équipe de recherche a en outre proposé un module d’amélioration de la diversité. 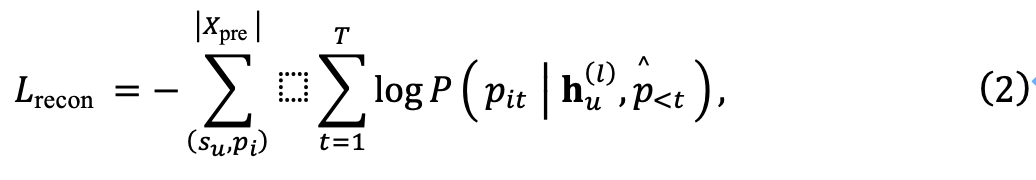
Plus précisément, l'équipe de recherche module de manière adaptative l'influence de la séquence originale en intégrant les informations du modèle cible dans l'étape de décodage. Tout d’abord, ils projettent la mémoire générée par l’encodeur dans
espaces vectoriels différents, soit
. Idéalement, différents modèles de cibles devraient correspondre à différents souvenirs. À cette fin, ils ont également introduit un encodeur Transformer pour encoder le modèle cible et obtenir
. Ils ont compressé en un vecteur de probabilité :
,
sont les probabilités de sélection de la k-ème mémoire. Pour garantir que chaque espace mémoire est entièrement entraîné, nous n'effectuons pas de sélection stricte, mais obtenons plutôt la mémoire finale grâce à une somme pondérée : 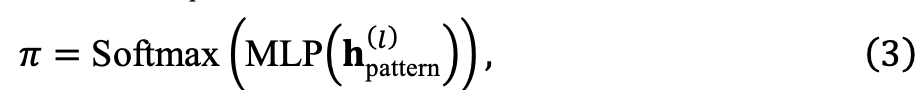
En fin de compte, la mémoire acquise peut être exploitée pour faciliter le processus de décodage et capturer efficacement les relations complexes un-à-plusieurs entre les séquences et les modèles. Régénération de l'ensemble de données sensible au modèleEn raison du processus de régénération précédent et du modèle cible agnostique, de sorte que l'ensemble de données reconstruit peut ne pas être optimal pour un modèle cible spécifique. Par conséquent, ils étendent le processus de régénération des ensembles de données indépendant du modèle à un processus de régénération sensible au modèle. À cette fin, sur la base du régénérateur d'ensemble de données, ils introduisent un personnalisateur d'ensemble de données qui évalue le score de chaque échantillon de données dans l'ensemble de données régénéré. L’équipe de recherche a ensuite optimisé plus efficacement le personnalisateur d’ensemble de données grâce à une différenciation implicite. Personnalisateur d'ensemble de données : L'objectif de l'équipe de recherche est d'entraîner un paramètre basé sur le personnalisateur d'ensemble de données  mis en œuvre par MLP pour évaluer le score de chaque échantillon de données
mis en œuvre par MLP pour évaluer le score de chaque échantillon de données  W pour le modèle cible. Pour garantir la généralité du cadre, l’équipe de recherche a utilisé les scores calculés pour ajuster les poids des pertes d’entraînement, ce qui n’a pas nécessité de modifications supplémentaires du modèle cible. Ils commencent par définir la perte de prédiction de l'élément suivant d'origine :
W pour le modèle cible. Pour garantir la généralité du cadre, l’équipe de recherche a utilisé les scores calculés pour ajuster les poids des pertes d’entraînement, ce qui n’a pas nécessité de modifications supplémentaires du modèle cible. Ils commencent par définir la perte de prédiction de l'élément suivant d'origine : Par la suite, la fonction de perte d'entraînement pour l'ensemble de données personnalisé peut être définie comme :
L'équipe de recherche a comparé les performances de chaque modèle cible avec les variantes « DR4SR » et « DR4SR+ » pour vérifier l'efficacité du cadre proposé. Figure 4
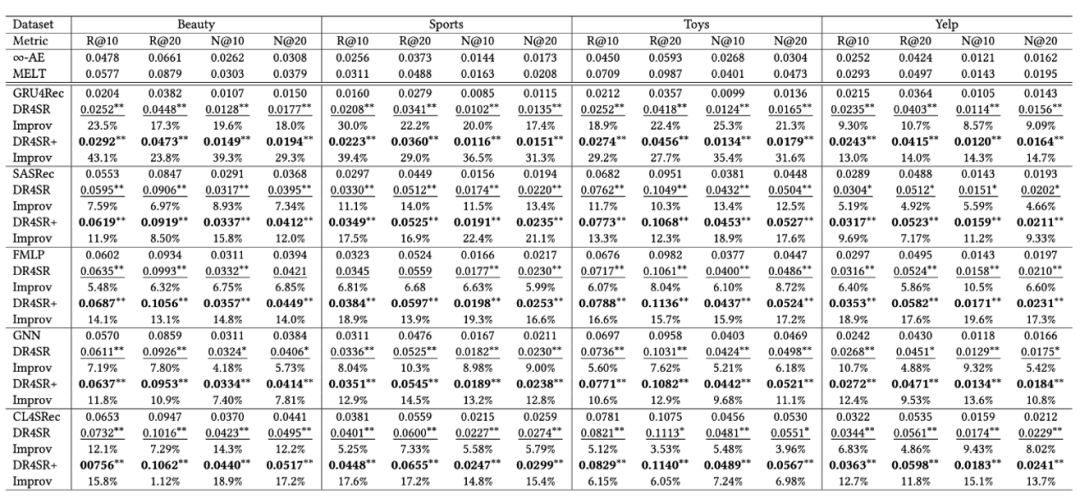
L'image globale présentée dans la figure 4 Performance, les conclusions suivantes peuvent être tirées :DR4SR est capable de reconstruire un ensemble de données informatif et généralement applicable
Différents modèles cibles préfèrent différents ensembles de données
- Le débruitage n'est qu'un sous-ensemble du problème de reconstruction des données
-
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




 . À cette fin, l'équipe de recherche a exploré la possibilité de développer un ensemble de données qui représente explicitement les modèles de transfert d'éléments dans
. À cette fin, l'équipe de recherche a exploré la possibilité de développer un ensemble de données qui représente explicitement les modèles de transfert d'éléments dans 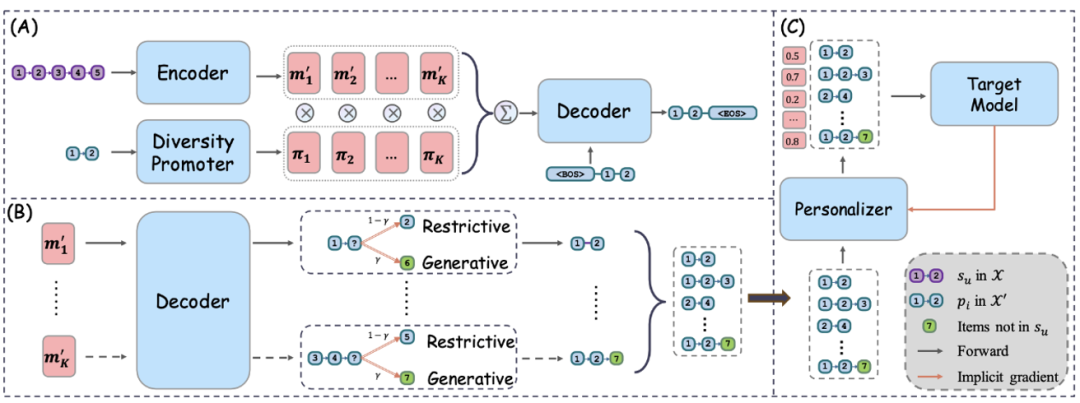



 où
où 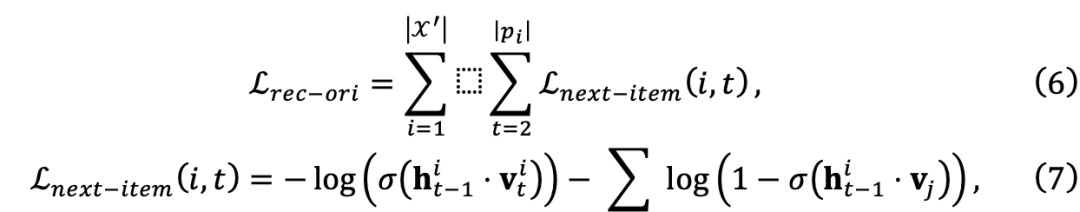
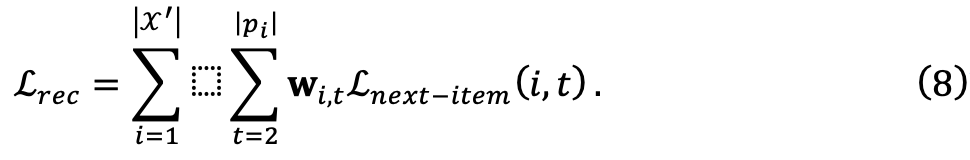
 Quel est le format de fichier mkv ?
Quel est le format de fichier mkv ?
 Utilisation du cordon
Utilisation du cordon
 Java est-il front-end ou back-end ?
Java est-il front-end ou back-end ?
 Pourquoi mon téléphone portable ne peut-il pas passer d'appels mais ne peut pas surfer sur Internet ?
Pourquoi mon téléphone portable ne peut-il pas passer d'appels mais ne peut pas surfer sur Internet ?
 Raisons pour lesquelles le tableau Excel ne peut pas être ouvert
Raisons pour lesquelles le tableau Excel ne peut pas être ouvert
 Comment configurer un VPS sécurisé
Comment configurer un VPS sécurisé
 Comment insérer une vidéo en HTML
Comment insérer une vidéo en HTML
 méthode de mise à niveau Win10
méthode de mise à niveau Win10








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



