


A comprehensive understanding of 3D scenes is crucial in autonomous driving, and recent 3D semantic occupancy prediction models have successfully addressed the challenge of describing real-world objects with different shapes and categories. However, existing 3D occupancy prediction methods rely heavily on panoramic camera images, which makes them susceptible to changes in lighting and weather conditions. By integrating the capabilities of additional sensors such as lidar and surround-view radar, our framework improves the accuracy and robustness of occupancy prediction, resulting in top performance on the nuScenes benchmark. Furthermore, extensive experiments on the nuScene dataset, including challenging nighttime and rainy scenes, confirm the superior performance of our sensor fusion strategy across various sensing ranges.
Paper link: https://arxiv.org/pdf/2403.01644.pdf
Paper name: OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction
The main contributions of this paper are summarized as follows:
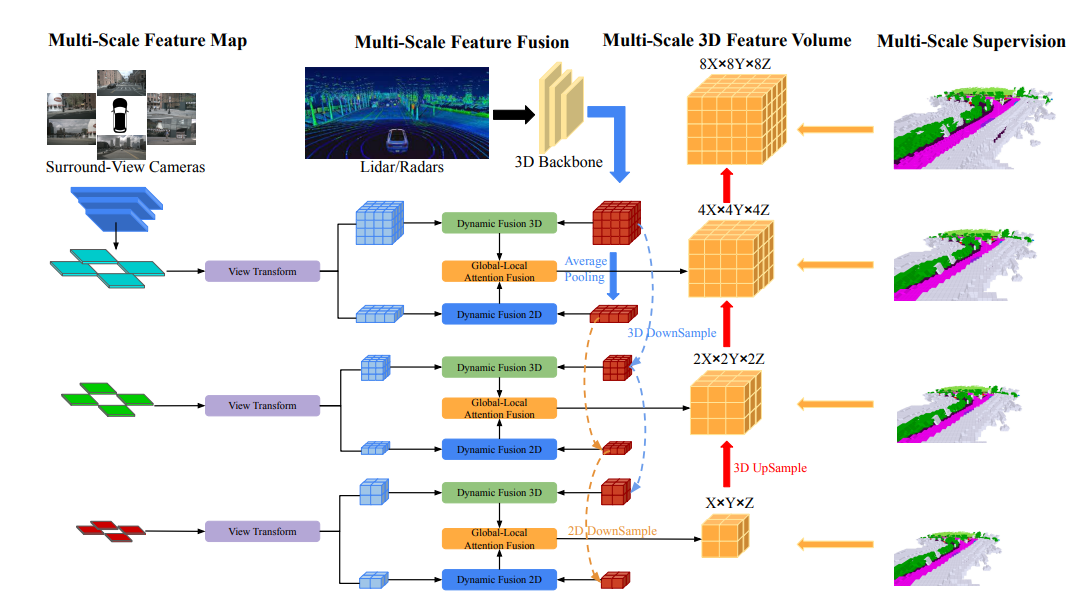
The overall architecture of OccFusion is as follows. First, surround view images are input into a 2D backbone to extract multi-scale features. Subsequently, view transformation is performed at each scale to obtain global BEV features and local 3D feature volume at each level. The 3D point clouds generated by lidar and surround radar are also input into the 3D backbone to generate multi-scale local 3D feature quantities and global BEV features. Dynamic fusion 3D/2D modules at each level combine the capabilities of cameras and lidar/radar. After this, the merged global BEV features and local 3D feature volume at each level are fed into the global-local attention fusion to generate the final 3D volume at each scale. Finally, the 3D volume at each level is upsampled and skip-connected with a multi-scale supervision mechanism.
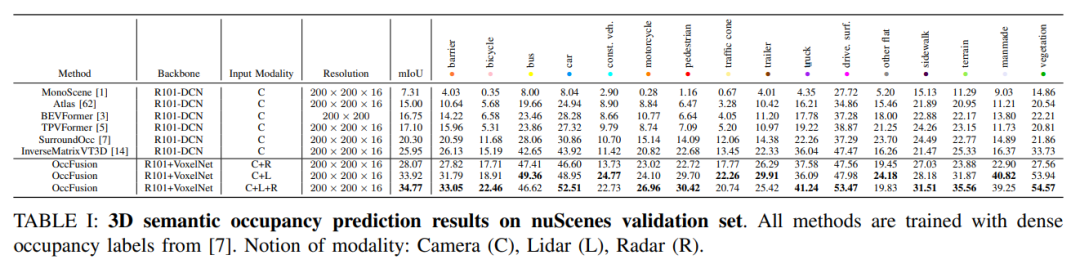
On the nuScenes validation set, various methods based on dense occupancy label training are demonstrated in 3D semantics Results in occupancy forecasts. These methods involve different modal concepts including camera (C), lidar (L) and radar (R).
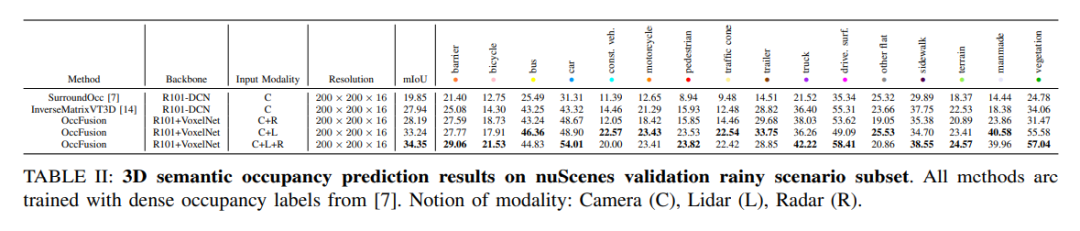
On the rainy scene subset of the nuScenes dataset, we predict 3D semantic occupancy and use dense occupancy labels for training. In this experiment, we considered data from different modalities such as camera (C), lidar (L), radar (R), etc. The fusion of these modes can help us better understand and predict rainy scenes, providing an important reference for the development of autonomous driving systems.
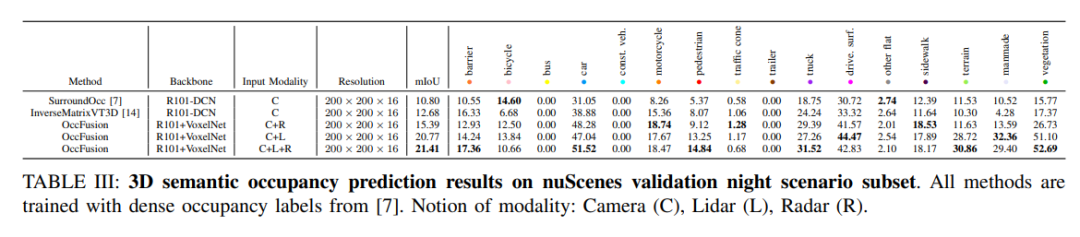
#nuScenes validates 3D semantic occupancy prediction results for a subset of nighttime scenes. All methods are trained using dense occupancy labels. Modal concepts: camera (C), lidar (L), radar (R).
Performance change trend. (a) Performance change trend of the entire nuScenes validation set, (b) nuScenes validation night scene subset, and (c) nuScene validation performance change trend of the rainy scene subset.
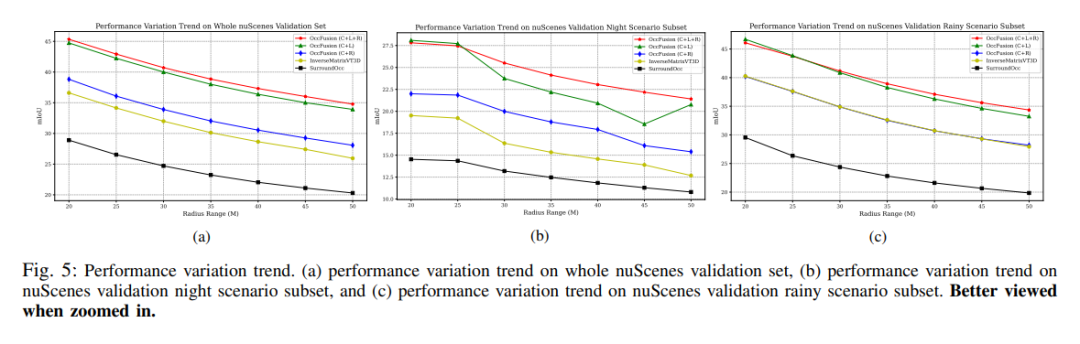
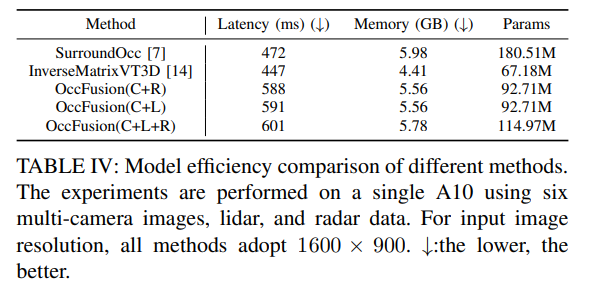
Table 4: Comparison of model efficiency of different methods. Experiments were conducted on an A10 using six multi-camera images, lidar and radar data. For input image resolution, 1600×900 is used for all methods. ↓:The lower the better.
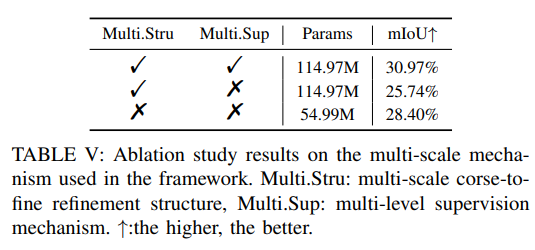
More ablation experiments:


The above is the detailed content of OccFusion: A simple and effective multi-sensor fusion framework for Occ (Performance SOTA). For more information, please follow other related articles on the PHP Chinese website!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



