


As the technical analysis of Sora unfolds, the importance of AI infrastructure becomes increasingly prominent.
A new paper from Byte and Peking University attracted attention at this time:
The article disclosed that the Wanka cluster built by Byte can be used in ## Complete the training of GPT-3 scale model (175B) within #1.75 days.
MegaScale, which aims to solve the problems faced when training large models on the Wanka cluster. efficiency and stability challenges.
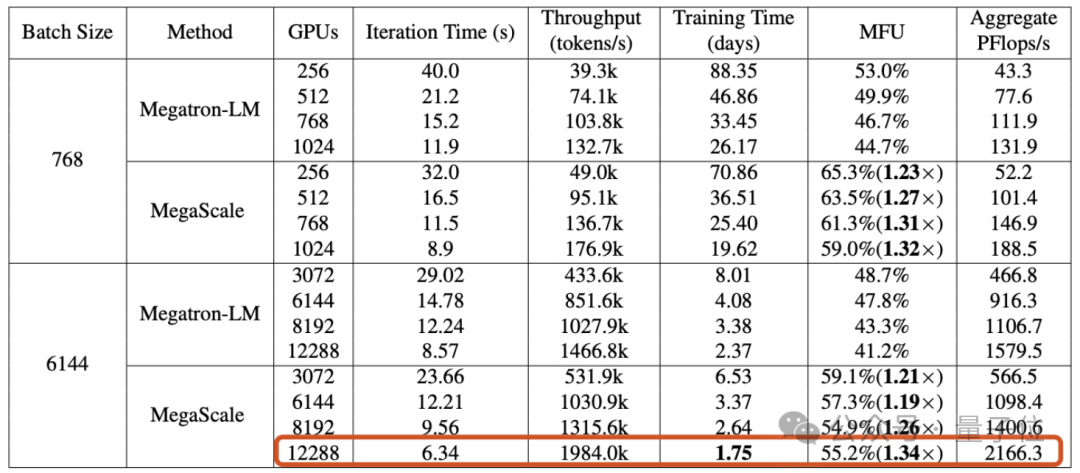
When training a 175 billion parameter large language model on 12288 GPUs, MegaScale achieved a computing power utilization of 55.2%(MFU) , which is 1.34 times that of NVIDIA Megatron-LM.
The paper also revealed that as of September 2023, Byte has established an Ampere architecture GPU(A100/A800) cluster with more than 10,000 cards, and is currently building a large-scale Hopper architecture (H100/H800)Cluster.
Production system suitable for Wanka clusterIn the era of large models, the importance of GPU no longer needs elaboration. But the training of large models cannot be started directly when the number of cards is full - when the scale of the GPU cluster reaches the "10,000" level, how to achieveefficiency and stability# The training of ## is itself a challenging engineering problem.
 The first challenge: efficiency.
The first challenge: efficiency.
Training a large language model is not a simple parallel task. The model needs to be distributed among multiple GPUs, and these GPUs require frequent communication to jointly advance the training process. In addition to communication, factors such as operator optimization, data preprocessing and GPU memory consumption all have an impact on computing power utilization
(MFU), an indicator that measures training efficiency.
MFU is the ratio of actual throughput to theoretical maximum throughput.The second challenge: stability.
We know that training large language models often takes a very long time, which also means that failures and delays during the training process are not uncommon.
The cost of failure is high, so how to shorten the fault recovery time becomes particularly important.
In order to address these challenges, ByteDance researchers built MegaScale and have deployed it in Byte's data center to support the training of various large models.
MegaScale is improved on the basis of NVIDIA Megatron-LM.
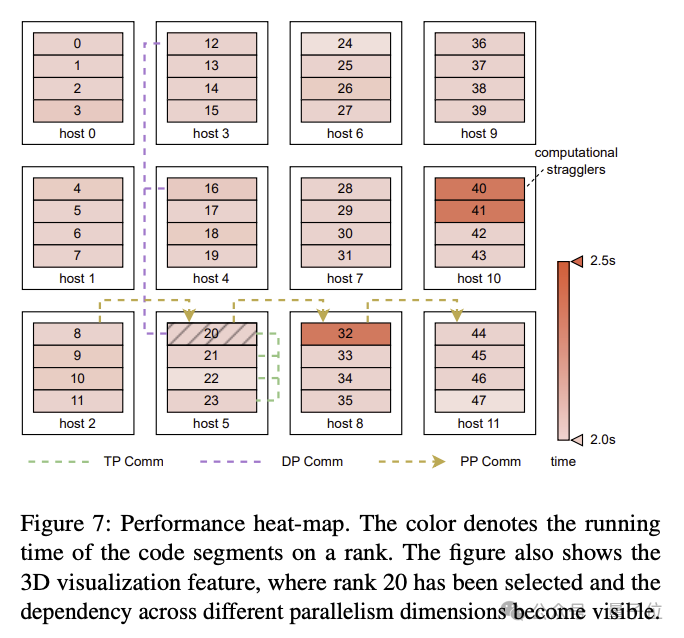
 # Specific improvements include the co-design of algorithms and system components, optimization of communication and computational overlap, operator optimization, data pipeline optimization, and network performance Tuning, etc.:
# Specific improvements include the co-design of algorithms and system components, optimization of communication and computational overlap, operator optimization, data pipeline optimization, and network performance Tuning, etc.:
The paper mentioned that MegaScale can automatically detect and repair more than 90% of software and hardware failures.
Experimental results show that MegaScale achieved 55.2% MFU when training a 175B large language model on 12288 GPUs, which is the Megatrion-LM algorithm 1.34 times the power utilization rate.
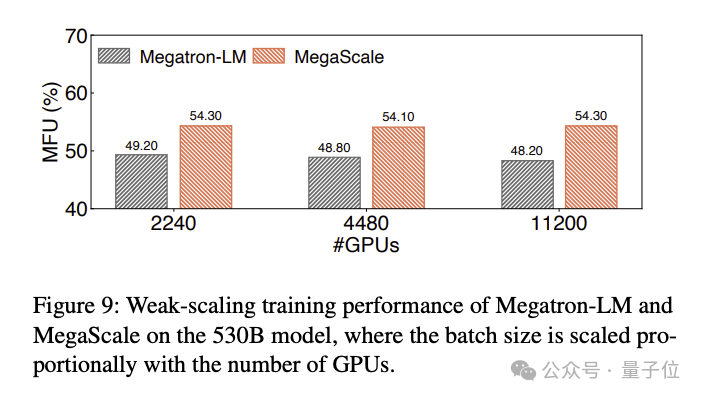
The MFU comparison results of training a 530B large language model are as follows:
Just after this technical paper triggered a discussion Recently, new news has also come out about the byte-based Sora product:
Jiangying's Sora-like AI video tool has launched an invitation-only beta test.

#It seems that the foundation has been laid, so are you looking forward to Byte's large model products?
Paper address: https://arxiv.org/abs/2402.15627
The above is the detailed content of The technical details of the Byte Wanka cluster are disclosed: GPT-3 training was completed in 2 days, and the computing power utilization exceeded NVIDIA Megatron-LM. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



