


Linked list is a commonly used data structure for organizing ordered data. It connects a series of data nodes into a data chain through pointers, and is an important implementation method of linear tables. Compared to arrays, linked lists are more dynamic. When building a linked list, there is no need to know the total amount of data in advance, space can be randomly allocated, and data can be efficiently inserted or deleted at any location in the linked list in real time. The main overhead of linked lists is the sequentiality of access and the space loss of organizing the chain.
Usually, the linked list data structure should contain at least two fields: data field and pointer field. The data field is used to store data, and the pointer field is used to establish contact with the next node. According to the organization of the pointer field and the connection form between each node, the linked list can be divided into various types such as single linked list, double linked list, circular linked list and so on. The following are schematic diagrams of these common linked list types:
Singly linked list is the simplest type of linked list. Its characteristic is that there is only one pointer field pointing to the subsequent node (next). Therefore, the singly linked list can only be traversed from beginning to end (usually NULL null pointer). .
By designing the two pointer fields of the predecessor and the successor, the double linked list can be traversed from two directions, which is what distinguishes it from the singly linked list. If the dependency relationship between the predecessor and successor is disrupted, a "binary tree" can be formed; if the predecessor of the first node points to the tail node of the linked list, and the successor of the tail node points to the first node (as shown in the dotted line in Figure 2), a circular linked list is formed. ; If more pointer fields are designed, various complex tree-like data structures can be formed.
The characteristic of a circular linked list is that the successor of the tail node points to the first node. The schematic diagram of a double circular linked list has been given before. Its characteristic is that starting from any node and in either direction, any data in the linked list can be found. If the predecessor pointer is removed, it is a single circular linked list.
A large number of linked list structures are used in the Linux kernel to organize data, including device lists and data organization in various functional modules. Most of these linked lists use a quite wonderful linked list data structure implemented in [include/linux/list.h]. The subsequent sections of this article will introduce the organization and use of this data structure in detail through examples.
Although the 2.6 kernel is used as the basis for explanation here, in fact the linked list structure in the 2.4 kernel is no different from that in 2.6. The difference is that 2.6 expands two linked list data structures: read copy update of the linked list (rcu) and HASH linked list (hlist). Both extensions are based on the most basic list structure. Therefore, this article mainly introduces the basic linked list structure, and then briefly introduces rcu and hlist.
The definition of the linked list data structure is very simple (excerpted from [include/linux/list.h], all the following codes, unless otherwise stated, are taken from this file):
struct list_head {
struct list_head *next, *prev;
};
The list_head structure contains two pointers prev and next pointing to the list_head structure. It can be seen that the kernel's linked list has the function of a double linked list. In fact, it is usually organized into a double circular linked list.
Different from the double-linked list structure model introduced in the first section, the list_head here has no data field. In the Linux kernel linked list, instead of containing data in the linked list structure, the linked list nodes are contained in the data structure.
In data structure textbooks, the classic definition of a linked list is usually like this (taking a singly linked list as an example):
struct list_node {
struct list_node *next;
ElemType data;
};
Because of ElemType, each data item type needs to define its own linked list structure. Experienced C programmers should know that the standard template library uses C Template, which uses templates to abstract linked list operation interfaces that are independent of data item types.
在Linux内核链表中,需要用链表组织起来的数据通常会包含一个struct list_head成员,例如在[include/linux/netfilter.h]中定义了一个nf_sockopt_ops结构来描述Netfilter为某一协议族准备的getsockopt/setsockopt接口,其中就有一个(struct list_head list)成员,各个协议族的nf_sockopt_ops结构都通过这个list成员组织在一个链表中,表头是定义在[net/core/netfilter.c]中的nf_sockopts(struct list_head)。从下图中我们可以看到,这种通用的链表结构避免了为每个数据项类型定义自己的链表的麻烦。Linux的简捷实用、不求完美和标准的风格,在这里体现得相当充分。

实际上Linux只定义了链表节点,并没有专门定义链表头,那么一个链表结构是如何建立起来的呢?让我们来看看LIST_HEAD()这个宏:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
当我们用LIST_HEAD(nf_sockopts)声明一个名为nf_sockopts的链表头时,它的next、prev指针都初始化为指向自己,这样,我们就有了一个空链表,因为Linux用头指针的next是否指向自己来判断链表是否为空:
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
除了用LIST_HEAD()宏在声明的时候初始化一个链表以外,Linux还提供了一个INIT_LIST_HEAD宏用于运行时初始化链表:
#define INIT_LIST_HEAD(ptr) do { /
(ptr)->next = (ptr); (ptr)->prev = (ptr); /
} while (0)
我们用INIT_LIST_HEAD(&nf_sockopts)来使用它。
a) 插入
对链表的插入操作有两种:在表头插入和在表尾插入。Linux为此提供了两个接口:
static inline void list_add(struct list_head *new, struct list_head *head); static inline void list_add_tail(struct list_head *new, struct list_head *head);
因为Linux链表是循环表,且表头的next、prev分别指向链表中的第一个和最末一个节点,所以,list_add和list_add_tail的区别并不大,实际上,Linux分别用
__list_add(new, head, head->next);
和
__list_add(new, head->prev, head);
来实现两个接口,可见,在表头插入是插入在head之后,而在表尾插入是插入在head->prev之后。
假设有一个新nf_sockopt_ops结构变量new_sockopt需要添加到nf_sockopts链表头,我们应当这样操作:
list_add(&new_sockopt.list, &nf_sockopts);
从这里我们看出,nf_sockopts链表中记录的并不是new_sockopt的地址,而是其中的list元素的地址。如何通过链表访问到new_sockopt呢?下面会有详细介绍。
b) 删除
static inline void list_del(struct list_head *entry);
当我们需要删除nf_sockopts链表中添加的new_sockopt项时,我们这么操作:
list_del(&new_sockopt.list);
被剔除下来的new_sockopt.list,prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问–对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障。与之相对应,list_del_init()函数将节点从链表中解下来之后,调用LIST_INIT_HEAD()将节点置为空链状态。
c) 搬移
Linux提供了将原本属于一个链表的节点移动到另一个链表的操作,并根据插入到新链表的位置分为两类:
static inline void list_move(struct list_head *list, struct list_head *head); static inline void list_move_tail(struct list_head *list, struct list_head *head);
例如list_move(&new_sockopt.list,&nf_sockopts)会把new_sockopt从它所在的链表上删除,并将其再链入nf_sockopts的表头。
d) 合并
除了针对节点的插入、删除操作,Linux链表还提供了整个链表的插入功能:
static inline void list_splice(struct list_head *list, struct list_head *head);
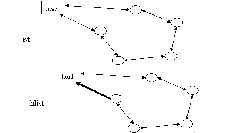
假设当前有两个链表,表头分别是list1和list2(都是struct list_head变量),当调用list_splice(&list1,&list2)时,只要list1非空,list1链表的内容将被挂接在list2链表上,位于list2和list2.next(原list2表的第一个节点)之间。新list2链表将以原list1表的第一个节点为首节点,而尾节点不变。如图(虚箭头为next指针):
图4 链表合并list_splice(&list1,&list2)

当list1被挂接到list2之后,作为原表头指针的list1的next、prev仍然指向原来的节点,为了避免引起混乱,Linux提供了一个list_splice_init()函数:
static inline void list_splice_init(struct list_head *list, struct list_head *head);
该函数在将list合并到head链表的基础上,调用INIT_LIST_HEAD(list)将list设置为空链。
遍历是链表最经常的操作之一,为了方便核心应用遍历链表,Linux链表将遍历操作抽象成几个宏。在介绍遍历宏之前,我们先看看如何从链表中访问到我们真正需要的数据项。
a) 由链表节点到数据项变量
我们知道,Linux链表中仅保存了数据项结构中list_head成员变量的地址,那么我们如何通过这个list_head成员访问到作为它的所有者的节点数据呢?Linux为此提供了一个list_entry(ptr,type,member)宏,其中ptr是指向该数据中list_head成员的指针,也就是存储在链表中的地址值,type是数据项的类型,member则是数据项类型定义中list_head成员的变量名,例如,我们要访问nf_sockopts链表中首个nf_sockopt_ops变量,则如此调用:
list_entry(nf_sockopts->next, struct nf_sockopt_ops, list);
这里”list”正是nf_sockopt_ops结构中定义的用于链表操作的节点成员变量名。
list_entry的使用相当简单,相比之下,它的实现则有一些难懂:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
container_of宏定义在[include/linux/kernel.h]中:
#define container_of(ptr, type, member) ({ /
const typeof( ((type *)0)->member ) *__mptr = (ptr); /
(type *)( (char *)__mptr - offsetof(type,member) );})
offsetof宏定义在[include/linux/stddef.h]中:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
size_t最终定义为unsigned int(i386)。
这里使用的是一个利用编译器技术的小技巧,即先求得结构成员在与结构中的偏移量,然后根据成员变量的地址反过来得出属主结构变量的地址。
container_of()和offsetof()并不仅用于链表操作,这里最有趣的地方是((type *)0)->member,它将0地址强制”转换”为type结构的指针,再访问到type结构中的member成员。在container_of宏中,它用来给typeof()提供参数(typeof()是gcc的扩展,和sizeof()类似),以获得member成员的数据类型;在offsetof()中,这个member成员的地址实际上就是type数据结构中member成员相对于结构变量的偏移量。
如果这么说还不好理解的话,不妨看看下面这张图:
图5 offsetof()宏的原理

对于给定一个结构,offsetof(type,member)是一个常量,list_entry()正是利用这个不变的偏移量来求得链表数据项的变量地址。
b) 遍历宏
在[net/core/netfilter.c]的nf_register_sockopt()函数中有这么一段话:
……
struct list_head *i;
……
list_for_each(i, &nf_sockopts) {
struct nf_sockopt_ops *ops = (struct nf_sockopt_ops *)i;
……
}
……
函数首先定义一个(struct list_head *)指针变量i,然后调用list_for_each(i,&nf_sockopts)进行遍历。在[include/linux/list.h]中,list_for_each()宏是这么定义的:
#define list_for_each(pos, head) / for (pos = (head)->next, prefetch(pos->next); pos != (head); / pos = pos->next, prefetch(pos->next))
它实际上是一个for循环,利用传入的pos作为循环变量,从表头head开始,逐项向后(next方向)移动pos,直至又回到head(prefetch()可以不考虑,用于预取以提高遍历速度)。
那么在nf_register_sockopt()中实际上就是遍历nf_sockopts链表。为什么能直接将获得的list_head成员变量地址当成struct nf_sockopt_ops数据项变量的地址呢?我们注意到在struct nf_sockopt_ops结构中,list是其中的第一项成员,因此,它的地址也就是结构变量的地址。更规范的获得数据变量地址的用法应该是:
struct nf_sockopt_ops *ops = list_entry(i, struct nf_sockopt_ops, list);
大多数情况下,遍历链表的时候都需要获得链表节点数据项,也就是说list_for_each()和list_entry()总是同时使用。对此Linux给出了一个list_for_each_entry()宏:
#define list_for_each_entry(pos, head, member) ……
与list_for_each()不同,这里的pos是数据项结构指针类型,而不是(struct list_head *)。nf_register_sockopt()函数可以利用这个宏而设计得更简单:
……
struct nf_sockopt_ops *ops;
list_for_each_entry(ops,&nf_sockopts,list){
……
}
……
某些应用需要反向遍历链表,Linux提供了list_for_each_prev()和list_for_each_entry_reverse()来完成这一操作,使用方法和上面介绍的list_for_each()、list_for_each_entry()完全相同。
如果遍历不是从链表头开始,而是从已知的某个节点pos开始,则可以使用list_for_each_entry_continue(pos,head,member)。有时还会出现这种需求,即经过一系列计算后,如果pos有值,则从pos开始遍历,如果没有,则从链表头开始,为此,Linux专门提供了一个list_prepare_entry(pos,head,member)宏,将它的返回值作为list_for_each_entry_continue()的pos参数,就可以满足这一要求。
在并发执行的环境下,链表操作通常都应该考虑同步安全性问题,为了方便,Linux将这一操作留给应用自己处理。Linux链表自己考虑的安全性主要有两个方面:
a) list_empty()判断
The basic list_empty() only determines whether the linked list is empty based on whether the next of the head pointer points to itself. The Linux linked list provides a list_empty_careful() macro, which simultaneously determines the next and prev of the head pointer. Only when both are Returns true only when pointing to itself. This is mainly to cope with the situation where next and prev are inconsistent due to another CPU processing the same linked list. However, the code comments also admit that this security guarantee capability is limited: unless the linked list operation of other CPUs is only list_del_init(), security cannot be guaranteed, that is, lock protection is still required.
b) Node deletion during traversal
Several macros for linked list traversal were introduced earlier. They all achieve the purpose of traversal by moving the pos pointer. But if the traversal operation includes deleting the node pointed to by the pos pointer, the movement of the pos pointer will be interrupted, because list_del(pos) will set the next and prev of pos to the special values of LIST_POSITION2 and LIST_POSITION1.
Of course, the caller can cache the next pointer himself to make the traversal operation coherent, but for the sake of programming consistency, Linux linked lists still provide two "_safe" interfaces corresponding to basic traversal operations: list_for_each_safe(pos, n , head), list_for_each_entry_safe(pos, n, head, member), they require the caller to provide an additional pointer n of the same type as pos, and temporarily store the address of the next node of pos in the for loop to avoid possible errors due to the pos node being released. Broken chain caused.
Figure 6 list and hlist
The Linux linked list designer who strives for excellence (because list.h is not signed, so it is probably Linus Torvalds) believes that the double-headed (next, prev) double-linked list is "too wasteful" for the HASH table, so he created a separate A set of hlist data structures for HASH table applications is designed - a single-pointer header double circular linked list. As can be seen from the above figure, the hlist header only has a pointer to the first node and no pointer to the tail node. In this way Storing headers in a potentially massive HASH table can reduce space consumption by half.
Because the data structures of the header and the node are different, if the insertion operation occurs between the header and the first node, the previous method will not work: the first pointer of the header must be modified to point to the newly inserted node, but you cannot use something like list_add() such a unified description. For this reason, the prev of the hlist node is no longer a pointer to the previous node, but a pointer to next (first for the header) in the previous node (possibly the header) (struct list_head **pprev), thus The operation of inserting at the head of the table can access and modify the next (or first) pointer of the predecessor node through the consistent "*(node->pprev)".
There is also a series of macros ending in "_rcu" in the Linux linked list function interface, which correspond to many of the functions introduced above. RCU (Read-Copy Update) is a new technology introduced in the 2.5/2.6 kernel that improves synchronization performance by delaying write operations.
We know that there are far more data reading operations than writing operations in the system, and the performance of the rwlock mechanism will decrease rapidly as the number of processors increases in the SMP environment (see Reference 4). In response to this application background, Paul E. McKenney of the IBM Linux Technology Center proposed the "read copy update" technology and applied it to the Linux kernel. The core of RCU technology is that the write operation is divided into two steps: write and update, allowing read operations to be accessed at any time without blocking. When the system has a write operation, the update action is delayed until all read operations on the data are completed. The RCU function in Linux linked list is only a small part of Linux RCU. The implementation analysis of RCU is beyond the scope of this article. Interested readers can refer to the reference materials of this article; and the use of RCU linked list and the use of basic linked list basically the same.
The program in the attachment has no practical effect except that it can output files in forward and reverse directions. It is only used to demonstrate the use of Linux linked lists.
For simplicity, the example uses a user mode program template. If you need to run it, you can use the following command to compile:
gcc -D__KERNEL__ -I/usr/src/linux-2.6.7/include pfile.c -o pfile
因为内核链表限制在内核态使用,但实际上对于数据结构本身而言并非只能在核态运行,因此,在笔者的编译中使用”-D__KERNEL__”开关”欺骗”编译器。
The above is the detailed content of Detailed analysis of Linux kernel linked list. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



