

 Technology peripherals
AI
LLMs for Coding in 2024: Price, Performance, and the Battle for the Best
Technology peripherals
AI
LLMs for Coding in 2024: Price, Performance, and the Battle for the Best
LLMs for Coding in 2024: Price, Performance, and the Battle for the Best

The rapidly evolving landscape of Large Language Models (LLMs) for coding presents developers with a wealth of choices. This analysis compares top LLMs accessible via public APIs, focusing on their coding prowess as measured by benchmarks like HumanEval and real-world Elo scores. Whether you're building personal projects or integrating AI into your workflow, understanding these models' strengths and weaknesses is crucial for informed decision-making.
The Challenges of LLM Comparison:
Direct comparison is difficult due to frequent model updates (even minor ones significantly impact performance), the inherent stochasticity of LLMs leading to inconsistent results, and potential biases in benchmark design and reporting. This analysis represents a best-effort comparison based on currently available data.
Evaluation Metrics: HumanEval and Elo Scores:
This analysis utilizes two key metrics:
- HumanEval: A benchmark assessing code correctness and functionality based on given requirements. It measures code completion and problem-solving abilities.
- Elo Scores (Chatbot Arena - coding only): Derived from head-to-head LLM comparisons judged by humans. Higher Elo scores indicate superior relative performance. A 100-point difference suggests a ~64% win rate for the higher-rated model.
Performance Overview:

OpenAI's models consistently top both HumanEval and Elo rankings, showcasing superior coding capabilities. The o1-mini model surprisingly outperforms the larger o1 model in both metrics. Other companies' best models show comparable performance, though trailing OpenAI.

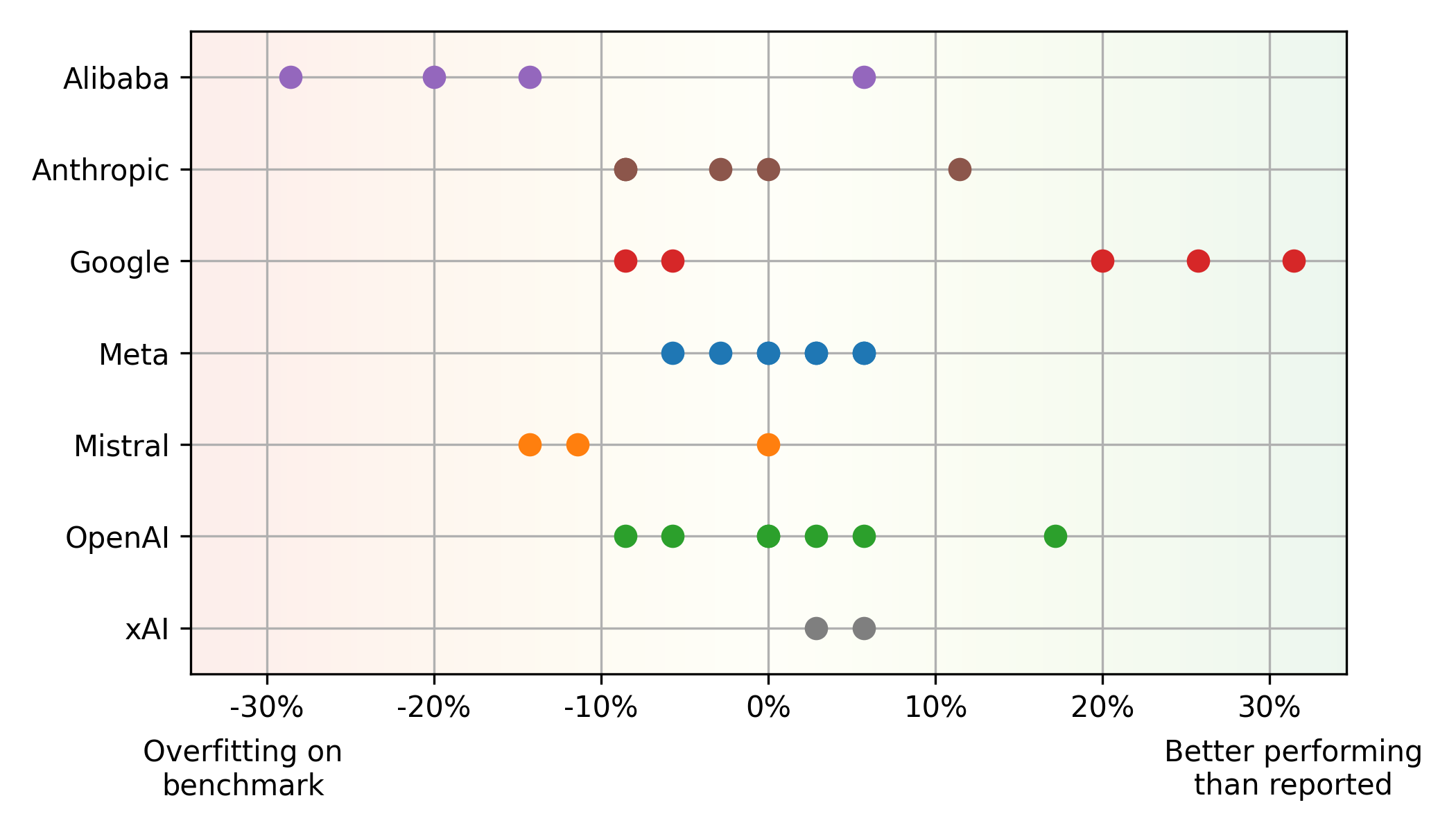
Benchmark vs. Real-World Performance Discrepancies:

A significant mismatch exists between HumanEval and Elo scores. Some models, like Mistral's Mistral Large, perform better on HumanEval than in real-world usage (potential overfitting), while others, such as Google's Gemini 1.5 Pro, show the opposite trend (underestimation in benchmarks). This highlights the limitations of relying solely on benchmarks. Alibaba and Mistral models often overfit benchmarks, while Google's models appear underrated due to their emphasis on fair evaluation. Meta models demonstrate a consistent balance between benchmark and real-world performance.
Balancing Performance and Price:


The Pareto front (optimal balance of performance and price) primarily features OpenAI (high performance) and Google (value for money) models. Meta's open-source Llama models, priced based on cloud provider averages, also show competitive value.
Additional Insights:



LLMs consistently improve in performance and decrease in cost. Proprietary models maintain dominance, although open-source models are catching up. Even minor updates significantly affect performance and/or pricing.
Conclusion:
The coding LLM landscape is dynamic. Developers should regularly assess the latest models, considering both performance and cost. Understanding the limitations of benchmarks and prioritizing diverse evaluation metrics is crucial for making informed choices. This analysis provides a snapshot of the current state, and continuous monitoring is essential to stay ahead in this rapidly evolving field.
The above is the detailed content of LLMs for Coding in 2024: Price, Performance, and the Battle for the Best. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 AI Investor Stuck At A Standstill? 3 Strategic Paths To Buy, Build, Or Partner With AI Vendors
Jul 02, 2025 am 11:13 AM
AI Investor Stuck At A Standstill? 3 Strategic Paths To Buy, Build, Or Partner With AI Vendors
Jul 02, 2025 am 11:13 AM
Investing is booming, but capital alone isn’t enough. With valuations rising and distinctiveness fading, investors in AI-focused venture funds must make a key decision: Buy, build, or partner to gain an edge? Here’s how to evaluate each option—and pr
 AGI And AI Superintelligence Are Going To Sharply Hit The Human Ceiling Assumption Barrier
Jul 04, 2025 am 11:10 AM
AGI And AI Superintelligence Are Going To Sharply Hit The Human Ceiling Assumption Barrier
Jul 04, 2025 am 11:10 AM
Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including identifying and explaining various impactful AI complexities (see the link here). Heading Toward AGI And
 Build Your First LLM Application: A Beginner's Tutorial
Jun 24, 2025 am 10:13 AM
Build Your First LLM Application: A Beginner's Tutorial
Jun 24, 2025 am 10:13 AM
Have you ever tried to build your own Large Language Model (LLM) application? Ever wondered how people are making their own LLM application to increase their productivity? LLM applications have proven to be useful in every aspect
 Kimi K2: The Most Powerful Open-Source Agentic Model
Jul 12, 2025 am 09:16 AM
Kimi K2: The Most Powerful Open-Source Agentic Model
Jul 12, 2025 am 09:16 AM
Remember the flood of open-source Chinese models that disrupted the GenAI industry earlier this year? While DeepSeek took most of the headlines, Kimi K1.5 was one of the prominent names in the list. And the model was quite cool.
 AMD Keeps Building Momentum In AI, With Plenty Of Work Still To Do
Jun 28, 2025 am 11:15 AM
AMD Keeps Building Momentum In AI, With Plenty Of Work Still To Do
Jun 28, 2025 am 11:15 AM
Overall, I think the event was important for showing how AMD is moving the ball down the field for customers and developers. Under Su, AMD’s M.O. is to have clear, ambitious plans and execute against them. Her “say/do” ratio is high. The company does
 Future Forecasting A Massive Intelligence Explosion On The Path From AI To AGI
Jul 02, 2025 am 11:19 AM
Future Forecasting A Massive Intelligence Explosion On The Path From AI To AGI
Jul 02, 2025 am 11:19 AM
Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including identifying and explaining various impactful AI complexities (see the link here). For those readers who h
 Chain Of Thought For Reasoning Models Might Not Work Out Long-Term
Jul 02, 2025 am 11:18 AM
Chain Of Thought For Reasoning Models Might Not Work Out Long-Term
Jul 02, 2025 am 11:18 AM
For example, if you ask a model a question like: “what does (X) person do at (X) company?” you may see a reasoning chain that looks something like this, assuming the system knows how to retrieve the necessary information:Locating details about the co
 Grok 4 vs Claude 4: Which is Better?
Jul 12, 2025 am 09:37 AM
Grok 4 vs Claude 4: Which is Better?
Jul 12, 2025 am 09:37 AM
By mid-2025, the AI “arms race” is heating up, and xAI and Anthropic have both released their flagship models, Grok 4 and Claude 4. These two models are at opposite ends of the design philosophy and deployment platform, yet they
