

 Technology peripherals
AI
How LLMs Work: Pre-Training to Post-Training, Neural Networks, Hallucinations, and Inference
Technology peripherals
AI
How LLMs Work: Pre-Training to Post-Training, Neural Networks, Hallucinations, and Inference
How LLMs Work: Pre-Training to Post-Training, Neural Networks, Hallucinations, and Inference

Unveiling the Magic Behind Large Language Models (LLMs): A Two-Part Exploration
Large Language Models (LLMs) often appear magical, but their inner workings are surprisingly systematic. This two-part series demystifies LLMs, explaining their construction, training, and refinement into the AI systems we use today. Inspired by Andrej Karpathy's insightful (and lengthy!) YouTube video, this condensed version provides the core concepts in a more accessible format. While Karpathy's video is highly recommended (800,000 views in just 10 days!), this 10-minute read distills the key takeaways from the first 1.5 hours.
Part 1: From Raw Data to Base Model
LLM development involves two crucial phases: pre-training and post-training.
1. Pre-training: Teaching the Language
Before generating text, an LLM must learn language structure. This computationally intensive pre-training process involves several steps:
- Data Acquisition and Preprocessing: Massive, diverse datasets are gathered, often including sources like Common Crawl (250 billion web pages). However, raw data requires cleaning to remove spam, duplicates, and low-quality content. Services like FineWeb offer preprocessed versions available on Hugging Face.
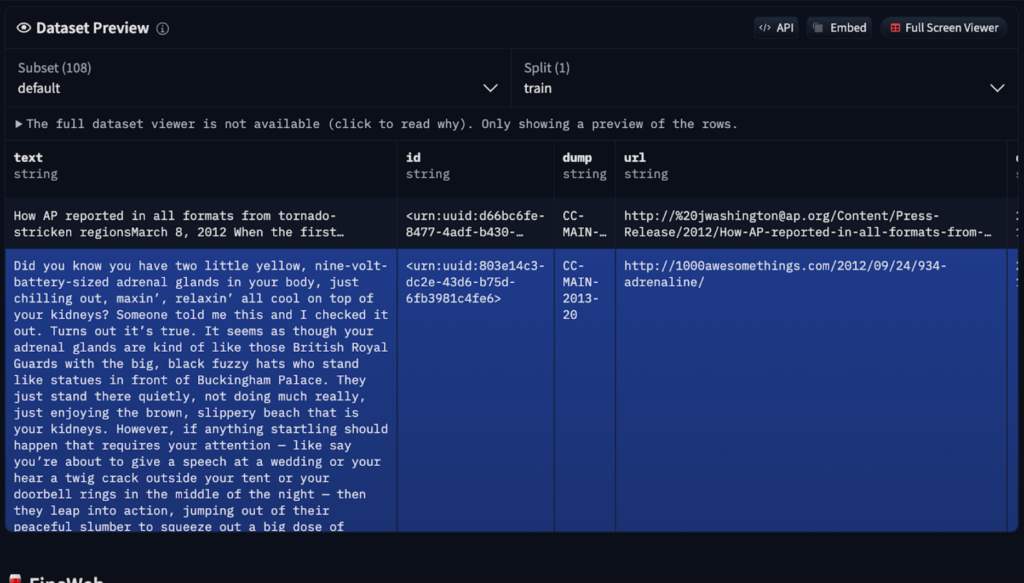
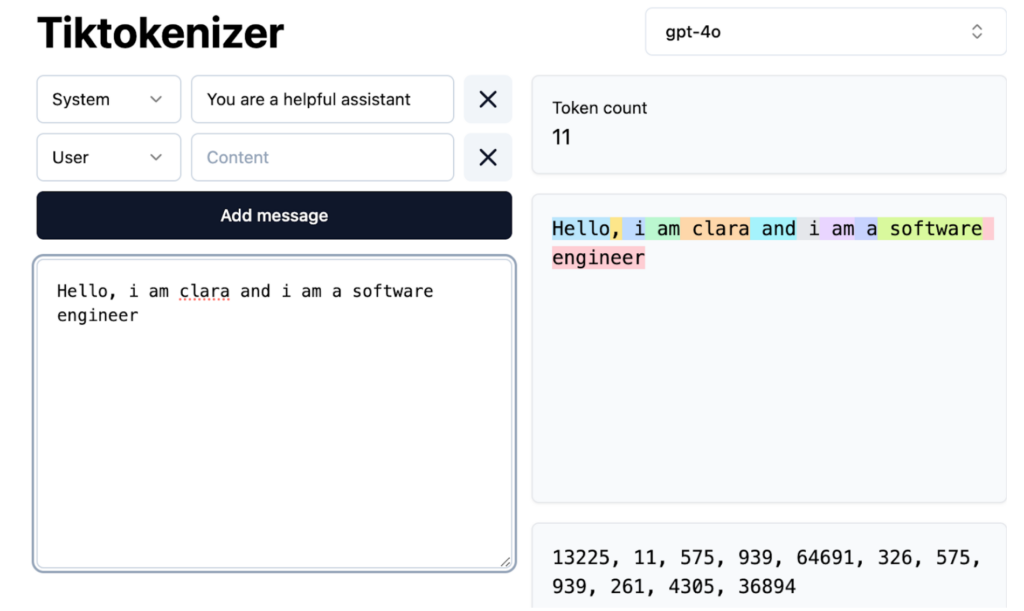
- Tokenization: Text is converted into numerical tokens (words, subwords, or characters) for neural network processing. GPT-4, for example, utilizes 100,277 unique tokens. Tools like Tiktokenizer visualize this process.
- Neural Network Training: The neural network learns to predict the next token in a sequence based on context. This involves billions of iterations, adjusting parameters (weights) via backpropagation to improve prediction accuracy. The network's architecture dictates how input tokens are processed to generate outputs.
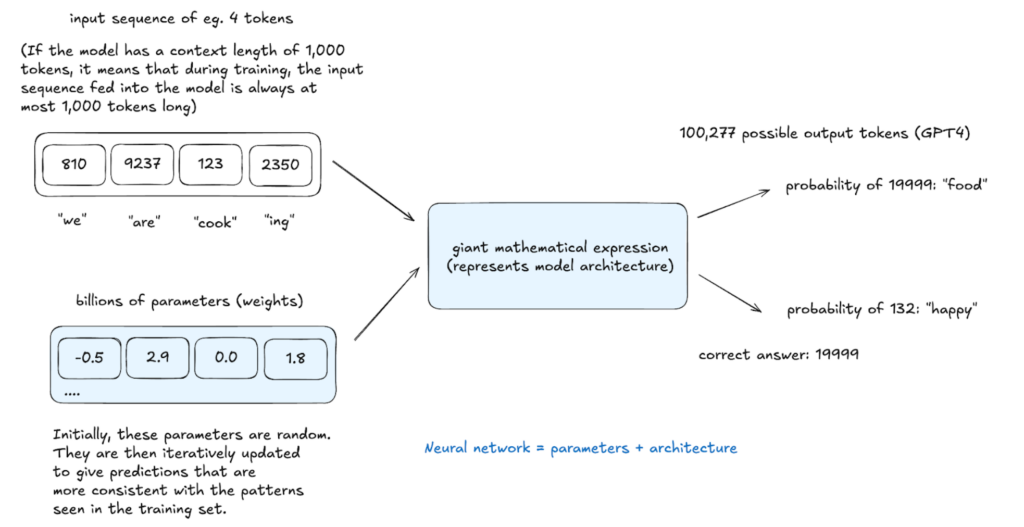
The resulting base model understands word relationships and statistical patterns but lacks real-world task optimization. It functions like an advanced autocomplete, predicting based on probability but with limited instruction-following capabilities. In-context learning, using examples within prompts, can be employed, but further training is necessary.
2. Post-training: Refining for Practical Use
Base models are refined through post-training using smaller, specialized datasets. This isn't explicit programming but rather implicit instruction through structured examples.
Post-training methods include:
- Instruction/Conversation Fine-tuning: Teaches the model to follow instructions, engage in conversations, adhere to safety guidelines, and refuse harmful requests (e.g., InstructGPT).
- Domain-Specific Fine-tuning: Adapts the model for specific fields (medicine, law, programming).
Special tokens are introduced to delineate user input and AI responses.
Inference: Generating Text
Inference, performed at any stage, evaluates model learning. The model assigns probabilities to potential next tokens and samples from this distribution, creating text not explicitly in the training data but statistically consistent with it. This stochastic process allows for varied outputs from the same input.
Hallucinations: Addressing False Information
Hallucinations, where LLMs generate false information, arise from their probabilistic nature. They don't "know" facts but predict likely word sequences. Mitigation strategies include:
- "I don't know" Training: Explicitly training the model to recognize knowledge gaps through self-interrogation and automated question generation.
- Web Search Integration: Extending knowledge by accessing external search tools, incorporating results into the model's context window.
LLMs access knowledge through vague recollections (patterns from pre-training) and working memory (information in the context window). System prompts can establish a consistent model identity.
Conclusion (Part 1)
This part explored the foundational aspects of LLM development. Part 2 will delve into reinforcement learning and examine cutting-edge models. Your questions and suggestions are welcome!
The above is the detailed content of How LLMs Work: Pre-Training to Post-Training, Neural Networks, Hallucinations, and Inference. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 o1 vs GPT-4o: Is OpenAI's New Model Better Than GPT-4o?
Mar 16, 2025 am 11:47 AM
o1 vs GPT-4o: Is OpenAI's New Model Better Than GPT-4o?
Mar 16, 2025 am 11:47 AM
OpenAI's o1: A 12-Day Gift Spree Begins with Their Most Powerful Model Yet December's arrival brings a global slowdown, snowflakes in some parts of the world, but OpenAI is just getting started. Sam Altman and his team are launching a 12-day gift ex
 Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google DeepMind's GenCast: A Revolutionary AI for Weather Forecasting Weather forecasting has undergone a dramatic transformation, moving from rudimentary observations to sophisticated AI-powered predictions. Google DeepMind's GenCast, a groundbreak
 Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
The article discusses AI models surpassing ChatGPT, like LaMDA, LLaMA, and Grok, highlighting their advantages in accuracy, understanding, and industry impact.(159 characters)
