


Large language models can perform automatic hint engineering through meta-hints, but their potential may not be fully realized due to the lack of sufficient guidance to guide complex reasoning capabilities in large language models. So how to guide large language models to carry out automatic prompt projects?
Large language models (LLMs) are powerful tools in natural language processing tasks, but finding optimal cues often requires a lot of manual trial and error. Due to the sensitive nature of the model, even after deployment to production, unexpected edge cases may be encountered requiring further manual tuning to improve prompts. Therefore, although LLM has great potential, manual intervention is still required to optimize its performance in practical applications.
These challenges have given rise to the emerging research field of auto-cue engineering. One notable approach in this area is by leveraging LLM's own capabilities. Specifically, this involves using instructions to meta-cue LLM, such as "check the current prompt and sample batch, then generate a new prompt".
While these methods achieve impressive performance, the question that arises is: what kind of meta-hints are suitable for auto-hint engineering?
To answer this question, researchers from the University of Southern California and Microsoft discovered two key observations. First, prompt engineering itself is a complex language task that requires deep reasoning. This means carefully examining the model for errors, determining whether some information is missing or misleading in the current prompt, and finding ways to communicate the task more clearly. Secondly, in LLM, complex reasoning capabilities can be stimulated by guiding the model to think step by step. We can further improve this capability by instructing the model to reflect on its output. These observations provide valuable clues for solving this problem.

Paper address: https://arxiv.org/pdf/2311.05661.pdf
Through the previous observations, the researcher conducted a fine-tuning project, aiming to Establishing a meta-hint provides guidance for LLM to perform hint engineering more efficiently (see Figure 2 below). By reflecting on the limitations of existing methods and incorporating recent advances in complex reasoning prompts, they introduce meta-cue components such as step-by-step reasoning templates and context specifications to explicitly guide LLM's reasoning process in prompt engineering.
Additionally, since hint engineering is closely related to optimization problems, we can borrow some inspiration from common optimization concepts such as batch size, step size, and momentum and introduce them into meta-hints for improvements . We experimented with these components and variants on two mathematical inference datasets, MultiArith and GSM8K, and identified a top-performing combination, which we named PE2.
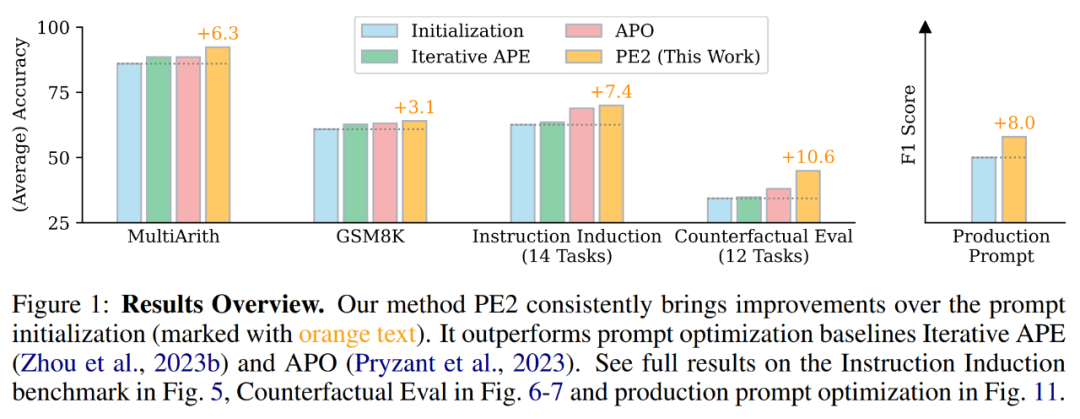
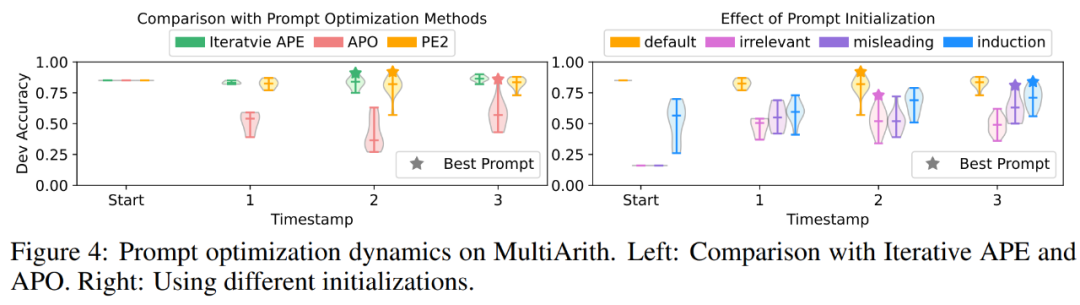
PE2 has made significant progress in empirical performance. When using TEXT-DAVINCI-003 as the task model, PE2-generated prompts improved by 6.3% on MultiArith and 3.1% on GSM8K over the step-by-step thinking prompts of the zero-shot thinking chain. Furthermore, PE2 outperforms the two auto-prompt engineering baselines, namely iterative APE and APO (see Figure 1).
It is worth noting that PE2 performs most effectively on the counterfactual task. Additionally, this study demonstrates the broad applicability of PE2 to optimizing lengthy, real-world prompts.
In reviewing PE2's prompt editing history, researchers found that PE2 consistently provides meaningful prompt editing. It is able to fix incorrect or incomplete hints and make the hints richer by adding additional details, resulting in an ultimate performance improvement (shown in Table 4).
Interestingly, when PE2 does not know addition in octal, it makes its own arithmetic rules from the example: "If both numbers are less than 50, add 2 to the sum. If one of the numbers is 50 or greater, add 22 to the sum." Although this is an imperfect and simple solution, it demonstrates PE2's remarkable ability to reason in counterfactual situations.
Despite these achievements, researchers have also recognized the limitations and failures of PE2. PE2 is also subject to limitations inherent in LLM, such as the plausibility of ignoring given instructions and generating errors (shown in Table 5 below).
Background knowledge
Prompt project
The goal of the prompt project is to find the text prompt p∗ that achieves the best performance on the given data set D when using the given LLM M_task as the task model (as shown in the following formula). More specifically, assume that all data sets can be formatted as text input-output pairs, i.e., D = {(x, y)}. A training set D_train for optimization hints, a D_dev for validation, and a D_test for final evaluation. According to the symbolic representation proposed by the researcher, the prompt engineering problem can be described as:
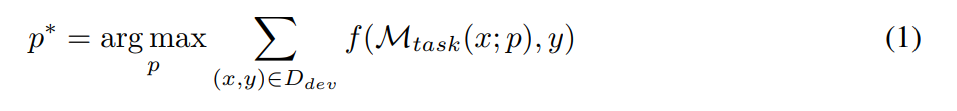
Among them, M_task (x; p) is generated by the model under the condition of given prompt p output, and f is the evaluation function for each example. For example, if the evaluation metric is an exact match, then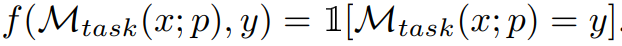
Use LLM for auto-prompt engineering
Auto-prompt given an initial set of prompts Engineers will continually come up with new and possibly better tips. At timestamp t, the prompt engineer gets a prompt p^(t) and expects to write a new prompt p^(t 1). During the generation of a new hint, one can optionally examine a batch of examples B = {(x, y, y′ )}. Here y ′ = M_task (x; p) represents the output generated by the model and y represents the true label. Use p^meta to represent a meta-prompt that guides LLM's M_proposal to propose new proposals. Therefore,
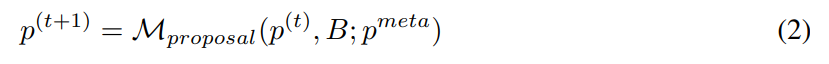
Building a better meta-cue p^meta to improve the quality of the proposed hint p^(t 1) is the main focus of this study.
Building better meta-cues
Just like cues play an important role in the final task performance, the meta-cue p^meta introduced in Equation 2 is in the new Plays an important role in the quality of the prompts presented and the overall quality of the automated prompts project.
Researchers mainly focus on hint engineering of meta-cue p^meta, developed meta-cue components that may help improve the quality of LLM hint engineering, and conducted systematic ablation research on these components.
The researchers designed the basis of these components based on the following two motivations: (1) Provide detailed guidance and background information; (2) Incorporate common optimizer concepts. Next, the researchers describe these elements in more detail and explain the underlying principles. Figure 2 below is a visual representation.
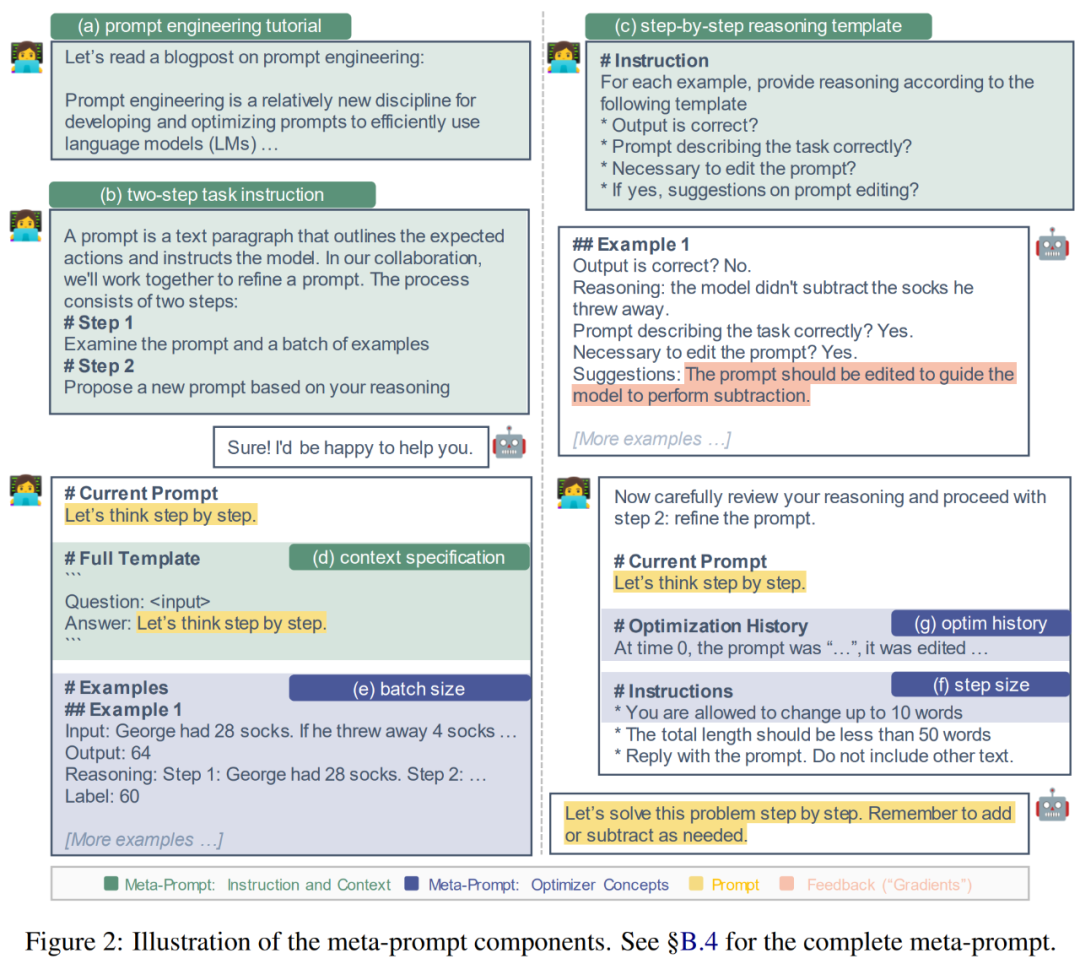
Provide detailed instructions and context. In previous studies, meta-cues either instructed the proposed model to generate a paraphrase of the prompt or contained minimal instructions about examining a batch of examples. Therefore it may be beneficial to add additional instructions and context to meta-cues.
(a) Prompt engineering tutorial. To help LLM better understand the task of prompt engineering, the researchers provide an online tutorial on prompt engineering in Meta-Click.
(b) Two-step task description. The prompt engineering task can be decomposed into two steps, as done by Pryzant et al.: In the first step, the model should examine the current prompt and a batch of examples. In the second step, the model should build an improved prompt. However, in Pryzant et al.'s approach, each step is explained on the fly. Instead, the researchers considered clarifying these two steps in the metacue and conveying expectations upfront.
(c) Step-by-step reasoning template. To encourage the model to carefully examine each example in batch B and reflect on the limitations of the current prompt, we guided the prompt proposal model M_proposal to answer a series of questions. For example: Is the output correct? Does the prompt describe the task correctly? Is it necessary to edit the prompt?
(d) Context specification. In practice, there is flexibility in where hints are inserted throughout the input sequence. It can describe the task before entering the text, such as "translate English to French." It can also appear after inputting text, such as "think step by step" to trigger reasoning skills. To recognize these different contexts, researchers explicitly specify the interaction between cues and input. For example: "Q:A: Think step by step."
Incorporate common optimizer concepts. The cue engineering problem described previously in Equation 1 is essentially an optimization problem, while the cue proposal in Equation 2 can be viewed as undergoing an optimization step. Therefore, researchers consider the following concepts commonly used in gradient-based optimization and develop their counterparts for use in meta-cues.
(e) Batch size. The batch size is the number of (failed) examples used in each tip proposal step (Equation 2). The authors tried batch sizes of {1, 2, 4, 8} in their analysis.
(f) step size. In gradient-based optimization, the step size determines how much the model weights are updated. In a prompt project, its counterpart might be the number of words (tokens) that can be modified. The author directly specifies "You can change up to s words in the original prompt", where s ∈ {5, 10, 15, None}.
(g) Optimize history and momentum. Momentum (Qian, 1999) is a technique that speeds up optimization and avoids oscillations by maintaining a moving average of past gradients. To develop the linguistic counterpart of momentum, this paper includes a summary of all past prompts (time stamped 0, 1, ..., t − 1), their performance on the dev set, and prompt edits.
Experiment
The author uses the following four sets of tasks to evaluate the effectiveness and limitations of PE2:
1. Mathematical reasoning; 2. Instruction induction ; 3. Counterfactual evaluation; 4. Production prompts.
Improved benchmarks and updated LLMs. In the first two parts of Table 2, the authors observe significant performance improvements using TEXT-DAVINCI-003, indicating that it is more capable of solving mathematical reasoning problems in Zero-shot CoT. Furthermore, the gap between the two cues decreased (MultiArith: 3.3% → 1.0%, GSM8K: 2.3% → 0.6%), indicating reduced sensitivity of TEXT-DAVINCI-003 to cue interpretation. For this reason, methods that rely on simple paraphrases, such as Iterative APE, may not be effective in improving the final results. More precise and targeted prompt editing is necessary to improve performance.
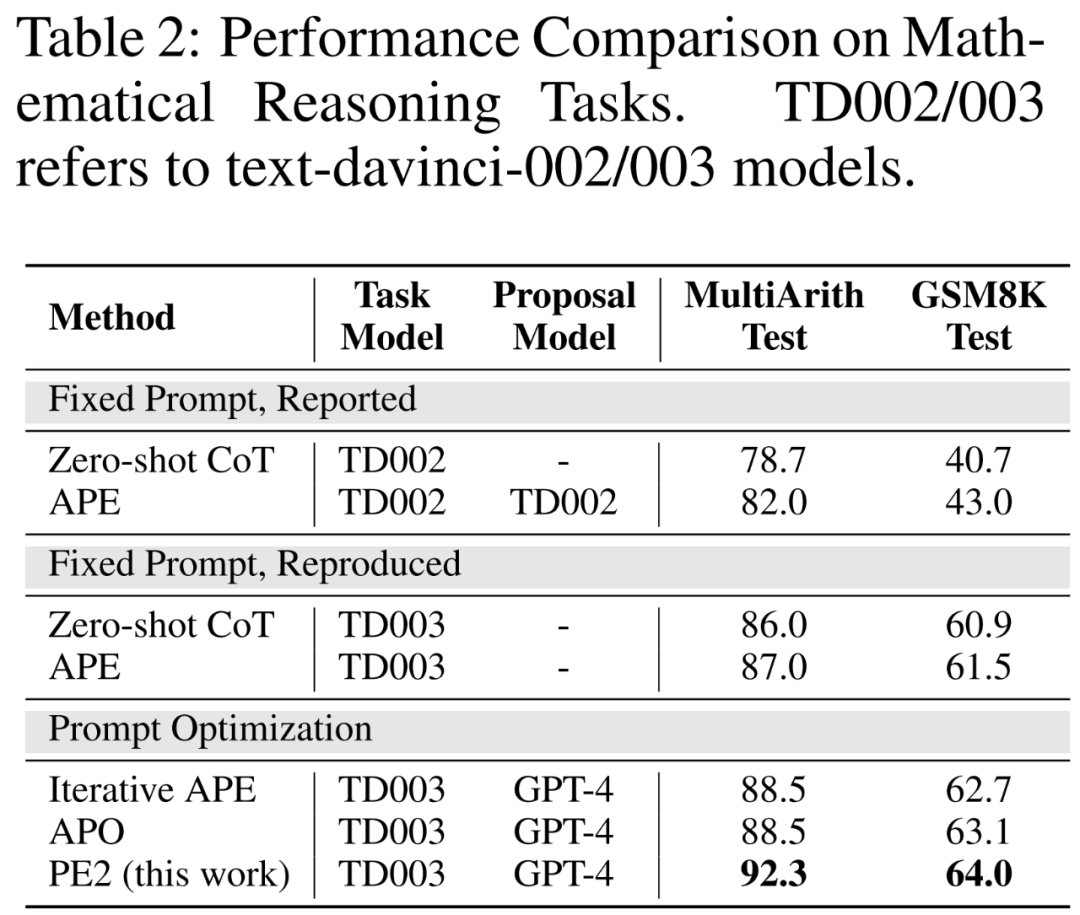
#PE2 outperforms Iterative APE and APO on a variety of tasks. PE2 is able to find a tip with 92.3% accuracy on MultiArith (6.3% better than Zero-shot CoT) and 64.0% on GSM8K (3.1%). Furthermore, PE2 found cues that outperformed Iterative APE and APO on the instruction induction benchmark, counterfactual evaluation, and production cues.
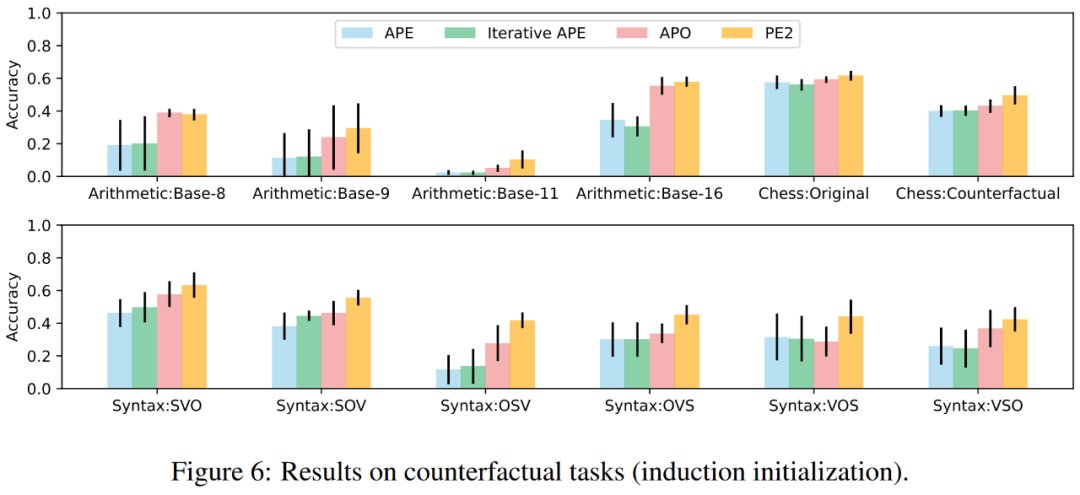
In Figure 1 above, the author summarizes the performance improvements achieved by PE2 on the instruction induction benchmark, counterfactual evaluation, and production prompts, demonstrating that PE2 achieves strong performance on various language tasks. Notably, when using inductive initialization, PE2 outperforms APO on 11 out of 12 counterfactual tasks (shown in Figure 6), demonstrating PE2’s ability to reason about paradoxical and counterfactual situations.
PE2 generates targeted prompt editing and high-quality prompts. In Figure 4(a), the authors plot the quality of the cue proposals during the cue optimization process. A very clear pattern was observed across the three cue optimization methods in the experiments: Iterative APE is based on paraphrasing, so the newly generated cues have smaller variance. APO undergoes drastic prompt editing, so performance degrades on the first step. PE2 is the most stable of the three methods. In Table 3, the authors list the best tips found by these methods. Both APO and PE2 can provide "consider all parts/details" instructions. Additionally, PE2 is designed to scrutinize batches, enabling it to go beyond simple paraphrase edits to very specific prompt edits such as "Remember to add or subtract as needed."
For more information, please refer to the original paper.
The above is the detailed content of More effective than the mantra 'Let's think step by step', it reminds us that the project is being improved.. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



