


Regression is one of the most powerful tools in statistics. Machine learning supervised learning algorithms are divided into two types: classification algorithms and regression algorithms. The regression algorithm is used for continuous distribution prediction and can predict continuous data rather than just discrete category labels.
Regression analysis is widely used in the field of machine learning, such as predicting product sales, traffic flow, housing prices, weather conditions, etc.The regression algorithm is a commonly used machine learning algorithm for establishing automatic The relationship between variable X and dependent variable Y. From a machine learning perspective, it is used to build an algorithm model (function) to achieve the mapping relationship between attribute X and label Y. During the learning process, the algorithm tries to find the best parameter relationship so that the degree of fit is the bestIn the regression algorithm, the final result of the algorithm (function) is a continuous data value. The input value (attribute value) is a d-dimensional attribute/numeric vectorSome commonly used regression algorithms include linear regression, polynomial regression, decision tree regression, Ridge regression, Lasso regression, ElasticNet regression, etc.This article will introduce some common regression algorithms and their respective characteristics
Linear regression It's often the first algorithm people learn about machine learning and data science. Linear regression is a linear model that assumes a linear relationship between an input variable (X) and a single output variable (y). Generally speaking, there are two situations:
Univariate linear regression is a modeling method used to analyze the relationship between a single input variable (i.e., a single feature variable) and a single output variable The relationship
Multivariable linear regression (also called multiple linear regression): It models the relationship between multiple input variables (multiple feature variables) and a single output variable .
Polynomial regression is one of the most popular choices when we want to create a model for nonlinear separable data. It is similar to linear regression but uses the relationship between variables X and y to find the best way to draw a curve that fits the data points.
Support vector machines are well known in classification problems. The use of SVM in regression is called Support Vector Regression (SVR). Scikit-learn has this method built into SVR().
The decision tree is a type of classification used Non-parametric supervised learning methods for and regression. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from data features. A tree can be viewed as a piecewise constant approximation.
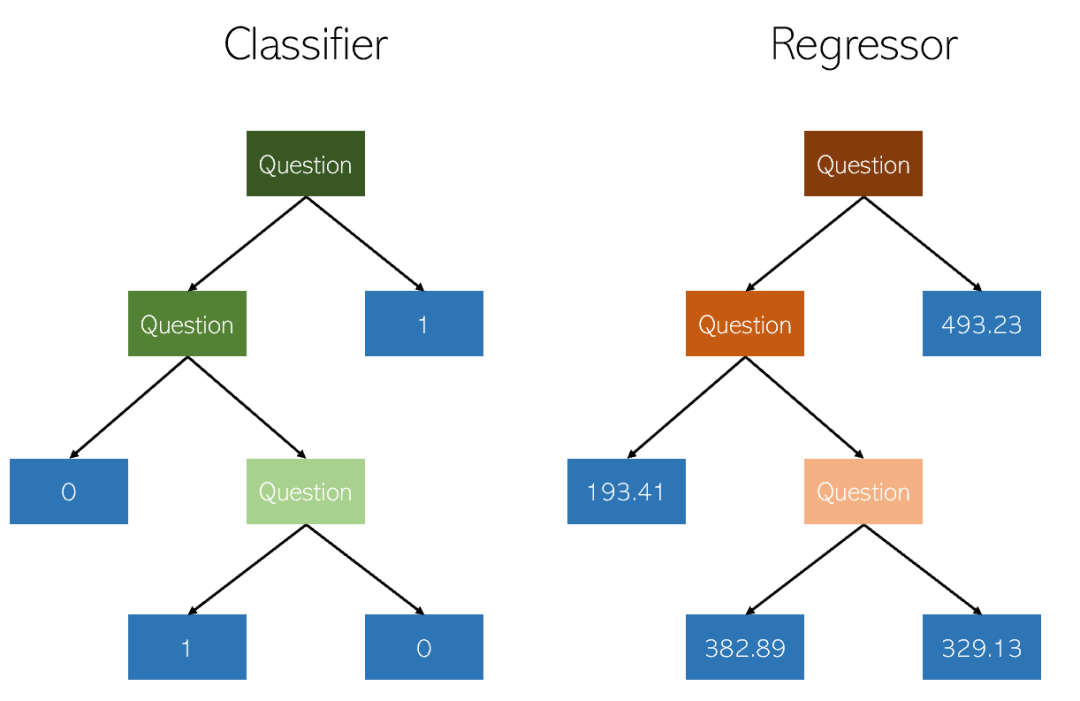
Random Forest Regression is basically very similar to Decision Tree Regression. It is a meta-estimator that can fit multiple decision trees on various subsamples of the data set and average them to improve prediction accuracy and control overfitting
random Forest regressors may perform better or worse than decision trees in regression problems (although they are generally better in classification problems) due to subtle overfitting and underfitting inherent in the tree construction algorithm. Trade-offs
LASSO regression is a variant of shrinkage linear regression. Shrinking is the process of shrinking data values to a center point as an average. This type of regression is ideal for models with severe multicollinearity (high correlation between features)
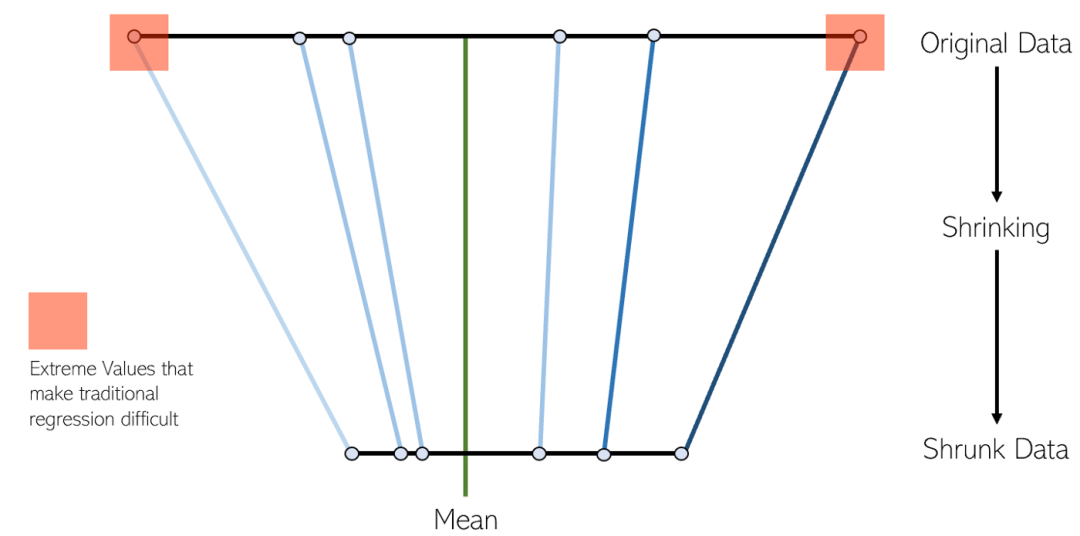
Ridge regression is very similar to LASSO regression because both techniques use shrinkage methods. Both Ridge and LASSO regression are well suited for models with severe multicollinearity problems (i.e. high correlation between features). The main difference between them is that Ridge uses L2 regularization, which means that none of the coefficients will go to zero (but close to zero) like in LASSO regression
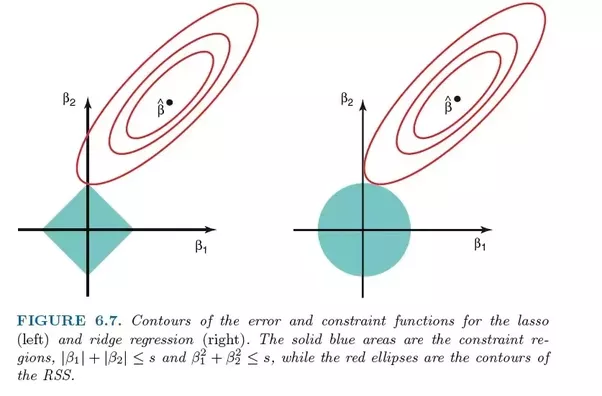
ElasticNet is another linear regression model trained using L1 and L2 regularization. It is a hybrid of Lasso and Ridge regression techniques, so it is also well suited for models that show severe multicollinearity (features are highly correlated with each other).
When weighing between Lasso and Ridge, a practical advantage is that Elastic-Net can inherit some of Ridge’s stability under rotation
XGBoost is an efficient and effective implementation of the gradient boosting algorithm. Gradient boosting is a type of ensemble machine learning algorithm that can be used for classification or regression problems
XGBoost is an open source library originally developed by Chen Tianqi in his 2016 paper "XGBoost: A Scalable Tree" Developed in "Boosting System". The algorithm is designed to be computationally efficient and efficient
In Local Weights Linear Regression (Local Weights Linear Regression), we are also performing linear regression. However, unlike ordinary linear regression, locally weighted linear regression is a local linear regression method. By introducing weights (kernel functions), when making predictions, only some samples that are close to the test points are used to calculate the regression coefficients. Ordinary linear regression is global linear regression, which uses all samples to calculate the regression coefficient
11. Bayesian Ridge Regression
The linear regression model solved using the Bayesian inference method is called Bayesian linear regressionBayesian linear regression is a method that treats the parameters of a linear model as random variables and calculates the posterior through the prior. Bayesian linear regression can be solved by numerical methods, and under certain conditions, posterior or related statistics in analytical form can also be obtained
Bayesian linear regression has a Bayesian statistical model The basic properties of it can solve the probability density function of weight coefficients, conduct online learning and model hypothesis testing based on Bayes factor (Bayes factor)
Advantages and Disadvantages&Applicable Scenarios
The disadvantage is the learning process overhead Too big. When the number of features is less than 10, you can try Bayesian regression.
The above is the detailed content of Commonly used regression algorithms and their characteristics in machine learning applications. For more information, please follow other related articles on the PHP Chinese website!
 What are the e-commerce platforms?
What are the e-commerce platforms?
 What is disk quota
What is disk quota
 Top ten digital currency exchanges
Top ten digital currency exchanges
 Introduction to dex concept digital currency
Introduction to dex concept digital currency
 How to view stored procedures in MySQL
How to view stored procedures in MySQL
 What drawing software are there?
What drawing software are there?
 The difference between static web pages and dynamic web pages
The difference between static web pages and dynamic web pages
 Introduction to laravel components
Introduction to laravel components








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



