



produced by Big Data Digest
Family friends, after artificial intelligence (AI) conquered chess, Go, and Dota, I am writing this article This skill has also been learned by AI robots.

The above-mentioned pen-turning robot benefits from an agent called Eureka, which comes from NVIDIA and the University of Pennsylvania. , a study from Caltech and the University of Texas at Austin.
After receiving Eureka's "guidance", the robot can also open drawers and cabinets, throw and catch balls, or use scissors. According to Nvidia, Eureka comes in 10 different types and can perform 29 different tasks.
You must know that in the past, the function of pen transfer could not be realized so smoothly by manual programming by human experts.

Robot Panwalnut
And Eureka can independently write reward algorithms to train robots, and has the coding power Powerful: The self-written reward program surpasses human experts in 83% of tasks, improving the robot's performance by an average of 52%.
Eureka has created a new way of learning without gradient from human feedback. It can easily absorb rewards and text feedback provided by humans, thereby further improving its own reward generation mechanism.
Specifically, Eureka leverages OpenAI’s GPT-4 to write reward programs for trial-and-error learning of robots. This means that the system does not rely on human task-specific cues or preset reward patterns.
Eureka can quickly evaluate the merits of a large number of candidate rewards by using GPU-accelerated simulation in Isaac Gym, allowing for more efficient training. Eureka then generates a summary of key statistics of the training results and guides the LLM (Language Model) to improve the generation of the reward function. In this way, the AI agent is able to independently improve its instructions to the robot.
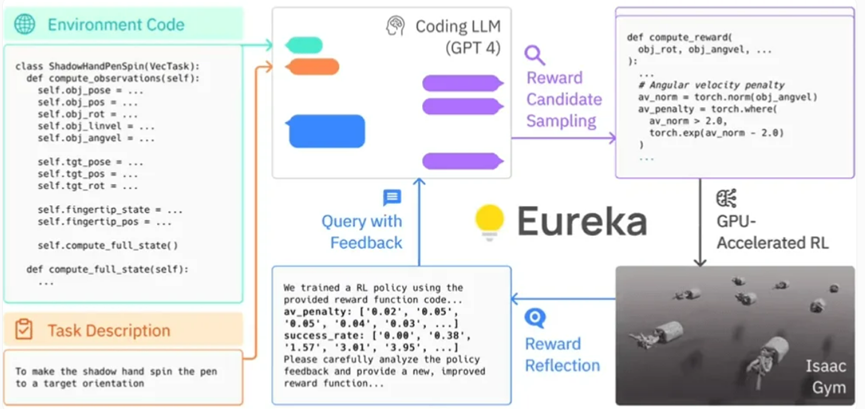
Eureka’s framework
The researchers also found that the more complex the task, the more GPT- 4's instructions are better than the human instructions of the so-called "reward engineers". Researchers involved in the study even called Eureka a "superhuman reward engineer."
#Eureka successfully bridges the gap between high-level reasoning (encoding) and low-level motor control. It uses what is called a "hybrid gradient architecture": a pure inference black box LLM (Language Model) guides a learnable neural network. In this architecture, the outer loop runs GPT-4 to optimize the reward function (gradient-free), while the inner loop runs reinforcement learning to train the robot’s controller (gradient-based).
- Linxi "Jim" Fan, Senior Research Scientist, NVIDIA
Eureka can integrate human feedback to Better tailor rewards to more closely align with developer expectations. Nvidia calls this process "in-context RLHF" (contextual learning from human feedback)
It is worth noting that Nvidia's research team has open sourced Eureka's AI algorithm library . This will allow individuals and institutions to explore and experiment with these algorithms through Nvidia Isaac Gym. Isaac Gym is built on the Nvidia Omniverse platform, a development framework for creating 3D tools and applications based on the Open USD framework.

Over the past decade, reinforcement learning has achieved great success, but we must acknowledge that there are still ongoing challenges. Although there have been attempts to introduce similar technologies before, compared with L2R (Learning to Reward) which uses language models (LLM) to assist reward design, Eureka is more prominent because it eliminates the need for task-specific prompts. What makes Eureka better than L2R is its ability to create freely expressed reward algorithms and leverage environmental source code as background information.
NVIDIA’s research team conducted a survey to explore whether priming with a human reward function offers some advantages. The purpose of the experiment is to see if you can successfully replace the original human reward function with the output of the initial Eureka iteration.
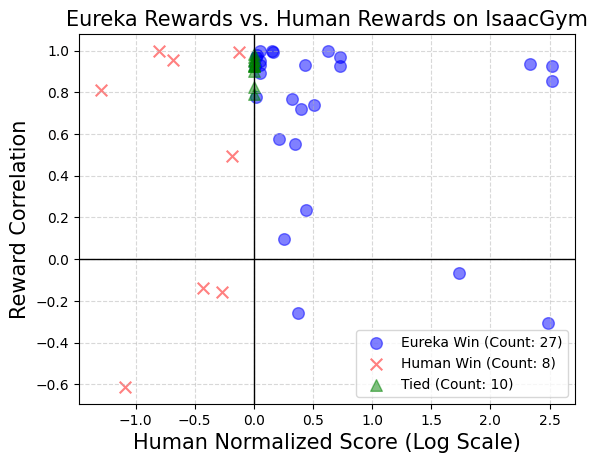
In the test, NVIDIA’s research team used the same reinforcement learning algorithm and the same hyperparameters for all tasks in the context of each task. The final reward function is optimized. To test whether these task-specific hyperparameters are well-tuned to ensure the effectiveness of artificially designed rewards, they employed a well-tuned proximal policy optimization (PPO) implementation that was based on previous work without any modifications. For each reward, the researchers conducted five independent PPO training runs and reported the average of the maximum task metric values reached at policy checkpoints as a measure of reward performance.
The results show that human designers often have a good understanding of relevant state variables, but may lack certain proficiency in designing effective rewards.
This groundbreaking research from Nvidia opens new frontiers in reinforcement learning and reward design. Their universal reward design algorithm, Eureka, harnesses the power of large language models and contextual evolutionary search to generate human-level rewards across a broad range of robotic task domains without the need for task-specific prompts or human intervention, significantly changing our Understanding of AI and machine learning.
The above is the detailed content of The robot learned to spin pens and plate walnuts! GPT-4 blessing, the more complex the task, the better the performance. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



