


This article is reprinted with the authorization of the Autonomous Driving Heart public account. Please contact the source for reprinting.
Original title: MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Paper link: https://arxiv.org/pdf/2309.16534.pdf
Author affiliation: Waymo
Conference: ICCV 2023

For autonomous vehicle safety planning, Reliably predicting future behavior of road agents is critical. This study represents continuous trajectories as sequences of discrete motion tokens and treats multi-agent motion prediction as a language modeling task. Our proposed model, MotionLM, has several advantages: First, it does not require the use of anchor points or explicit latent variables to optimally learn multi-modal distributions. Instead, we exploit the standard language modeling objective of maximizing the average log probability of sequence tokens. Second, our approach avoids post hoc interaction heuristics, where individual agent trajectory generation occurs after interaction scoring. In contrast, MotionLM generates a joint distribution of interactive agent futures in a single autoregressive decoding process. In addition, the sequential decomposition of the model enables temporal causal condition inference. Our proposed method achieves new state-of-the-art performance on the Waymo Open Motion Dataset, ranking first on the interactive challenge leaderboard
Here In this article, we discuss multi-agent motion prediction as a language modeling task. We introduce a temporal causal decoder to decode discrete motion tokens trained with a causal language modeling loss
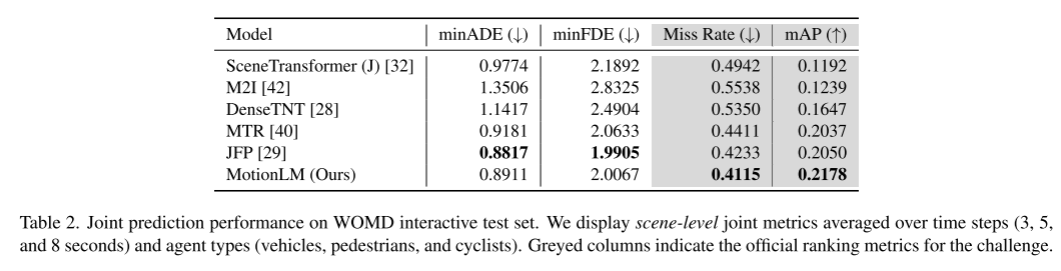
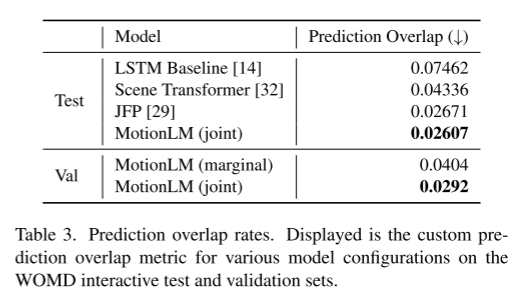
This paper will combine sampling in the model with a simple rollout aggregation scheme to improve the weighted pattern of the joint trajectory Recognition ability. Through experiments in the Waymo Open Motion Dataset interaction prediction challenge, we have demonstrated that this new method improves the ranking joint mAP metric by 6% and reaches the state-of-the-art performance level
This article's approach to this article Extensive ablation experiments are performed and its temporal causal conditional predictions are analyzed, which are largely unsupported by current joint prediction models.
The goal of this paper is to model the distribution on multi-agent interactions in a general way that can be applied to different Downstream tasks, including minimal, joint, and conditional predictions. To achieve this goal, an expressive generative framework is needed that can capture the multiple morphologies in driving scenes. Furthermore, we consider saving time dependencies here; that is, in our model, the inference follows a directed acyclic graph, with each node’s parent node being earlier in time and its child node being later in time, which makes Conditional prediction is closer to causal intervention because it eliminates certain spurious correlations that would otherwise lead to disobedience to temporal causality. This paper observes that joint models that do not preserve temporal dependencies may have limited ability to predict actual agent responses, a key use in planning. To this end, this paper utilizes an autoregressive decomposition of the future decoder, where the agent’s motion tokens conditionally depend on all previously sampled tokens and the trajectories are sequentially derived
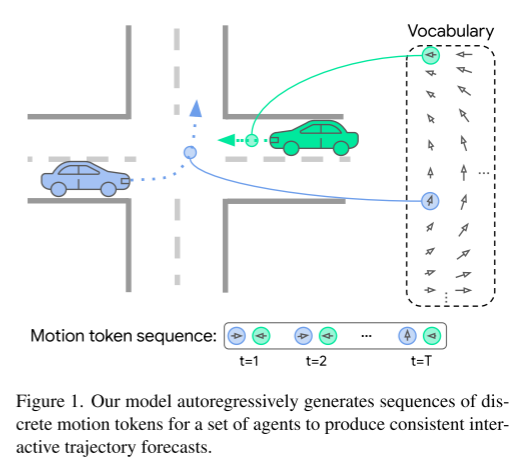
figure 1. Our model autoregressively generates sequences of discrete motion tokens for a set of agents to produce consistent interactive trajectory predictions.
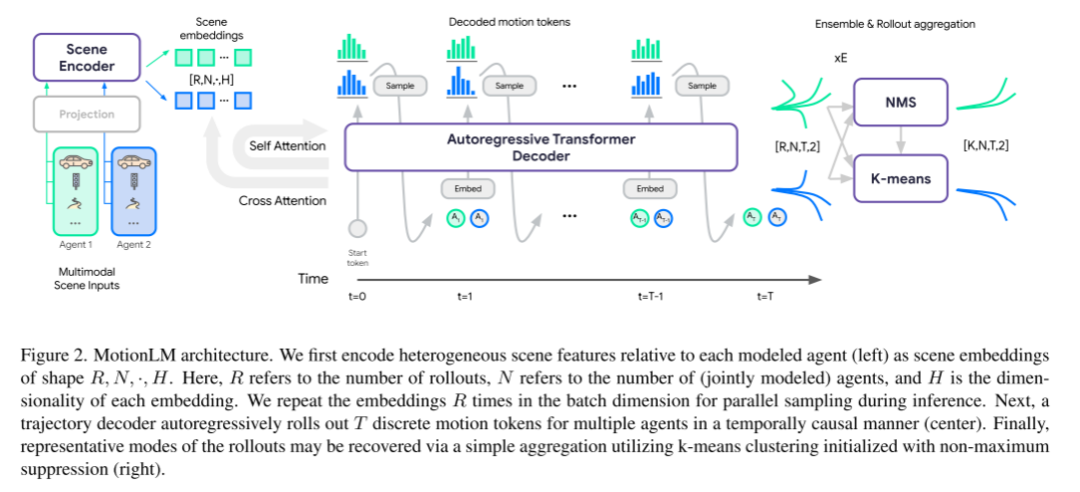
Please look at Figure 2, which is the architecture of MotionLM
This article first encodes the heterogeneous scene features (left) related to each modeling agent for scene embeddings of shape R,N,·,H. Among them, R is the number of rollouts, N is the number of jointly modeled agents, and H is the dimensionality of each embedding. During the inference process, in order to parallelize sampling, this paper repeats the embedding R times in the batch dimension. Next, a trajectory decoder rolls out T discrete motion tokens for multiple agents in a temporally causal manner (center). Finally, the typical pattern of rollouts can be recovered by simple aggregation of k-means clusters using non-maximum suppression initialization (right panel).
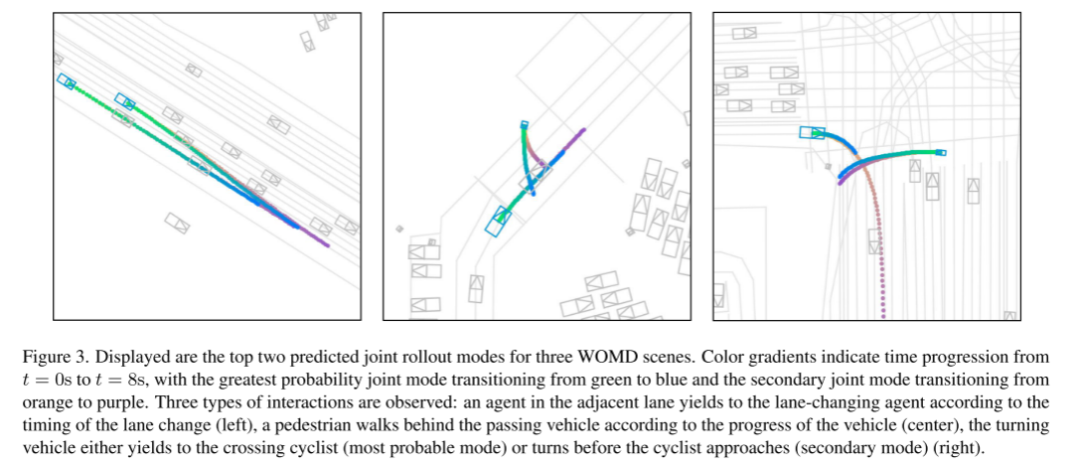
image 3. The first two prediction joint rollout modes for three WOMD scenarios are shown.
The color gradient represents the time change from t = 0 seconds to t = 8 seconds. The joint mode transitions from green to blue, and the sub-joint mode transitions from orange to purple with the highest probability. We observed three types of interactions: agents in adjacent lanes will give way to the lane-changing agent according to the lane-changing time (left), pedestrians will walk behind passing vehicles according to the vehicle's progress (center), and turning vehicles will either Will give way to a passing cyclist (most likely mode) or will turn before a cyclist approaches (minor mode) (right side)
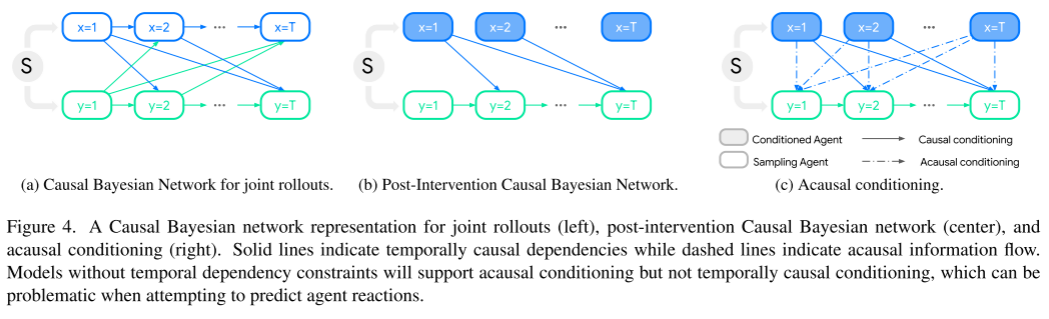
Please see Figure 4. This figure shows the causal Bayesian network representation of joint induction (left), post-intervention causal Bayesian network (middle), and causal conditioning (right)
Solid lines represent causality in time Correlation, while the dashed lines represent causal information flow. A model without time-dependent constraints will support causal conditioning but not temporal causal conditioning, which can be problematic when trying to predict agent responses.

ArXiv. /abs/2309.16534

The above is the detailed content of MotionLM: Language modeling technology for multi-agent motion prediction. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



