


Large-scale language models (LLM or LM) were originally used to generate language, but over time they have been able to generate content in multiple modalities and have found applications in audio, speech, code generation, medical applications, Fields like robotics are starting to dominate
Of course, LM can also generate images and videos. During this process, image pixels are mapped into a series of discrete tokens by the visual tokenizer. These tokens are then fed into the LM transformer and used like vocabularies for generative modeling. Despite significant progress in visual generation, LM still performs worse than diffusion models. For example, when evaluated on the ImageNet dataset, the gold standard benchmark for image generation, the best language model performed a whopping 48% worse than the diffusion model (FID 3.41 vs. 1.79 when generating images at 256ˆ256 resolution).
Why do language models lag behind diffusion models in visual generation? Researchers from Google and CMU believe that the main reason is the lack of a good visual representation, similar to our natural language system, to effectively model the visual world. To confirm this hypothesis, they conducted a study.

Paper link: https://arxiv.org/pdf/2310.05737.pdf
This The study shows that with the same training data, comparable model size and training budget, using a good visual tokenizer, masked language models surpass SOTA diffusion models in both generation fidelity and efficiency on image and video benchmarks. This is the first evidence that a language model beats a diffusion model on the iconic ImageNet benchmark.
It should be emphasized that the purpose of the researchers is not to assert whether the language model is better than other models, but to promote the exploration of LLM visual tokenization methods. The fundamental difference between LLM and other models (such as diffusion models) is that LLM uses discrete latent formats, i.e. tokens obtained from a visual tokenizer. This research shows that the value of these discrete visual tokens should not be ignored because of their following advantages:
1. Compatibility with LLM. The main advantage of the token representation is that it shares the same form as the language token, thereby directly leveraging the optimizations the community has made over the years to develop LLM, including faster training and inference speeds, advances in model infrastructure, ways to extend the model, and Innovations such as GPU/TPU optimization. Unifying vision and language through the same token space could lay the foundation for truly multimodal LLMs that can understand, generate, and reason within our visual environments.
2. Compressed representation. Discrete tokens can provide a new perspective on video compression. Visual tokens can be used as a new video compression format to reduce the disk storage and bandwidth occupied by data during Internet transmission. Unlike compressed RGB pixels, these tokens can be fed directly into the generative model, bypassing traditional decompression and latent encoding steps. This can speed up the processing of video-generating applications and is especially beneficial in edge computing situations.
3. Advantages of visual understanding. Previous research has shown the value of discrete labels as pre-training targets in self-supervised representation learning, as discussed in BEiT and BEVT. In addition, the study found that using markers as model inputs can improve its robustness and generalization performance
In this paper, the researchers proposed a model called MAGVIT-v2 A video tokenizer designed to convert videos (and images) into compact discrete tokens
This content is rewritten as follows: The model is based on the SOTA video tokenizer within the VQ-VAE framework ——Improvements made by MAGVIT. The researchers proposed two new technologies: 1) an innovative lookup-free quantification method that allows learning a large vocabulary, thereby improving the quality of language model generation; 2) through extensive empirical analysis, they determined Modifications to MAGVIT not only improve the generation quality, but also allow images and videos to be tokenized using a shared vocabulary
Experimental results show that the new model outperforms in three key areas The best performing video tokenizer before - MAGVIT. First, the new model significantly improves MAGVIT’s generation quality, achieving state-of-the-art results on common image and video benchmarks. Second, user studies show that its compression quality exceeds MAGVIT and the current video compression standard HEVC. Furthermore, it is comparable to the next-generation video codec VVC. Finally, the researchers show that their new word segmentation performs better than MAGVIT on video understanding tasks in two settings and three datasets
This paper introduces a new video tokenizer, aiming to map the time-space dynamics in the visual scene into compact discrete tokens suitable for language models . Furthermore, the method builds on MAGVIT.
The study then highlights two novel designs: Lookup-Free Quantization (LFQ) and enhancements to the tokenizer model.
Lookup-free quantification
Recently, the VQ-VAE model has made great progress, but there is a problem with this method The problem is that the relationship between improvements in reconstruction quality and subsequent generation quality is unclear. Many people mistakenly believe that improving reconstruction is equivalent to improving language model generation, for example, expanding the vocabulary can improve the quality of reconstruction. However, this improvement only applies to generation with a small vocabulary, and when the vocabulary is very large, it will harm the performance of the language model
This article reduces the VQ-VAE codebook embedding dimension to 0, that is, Codebook 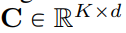 is replaced by an integer set
is replaced by an integer set 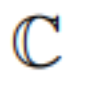 where
where 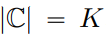 .
.
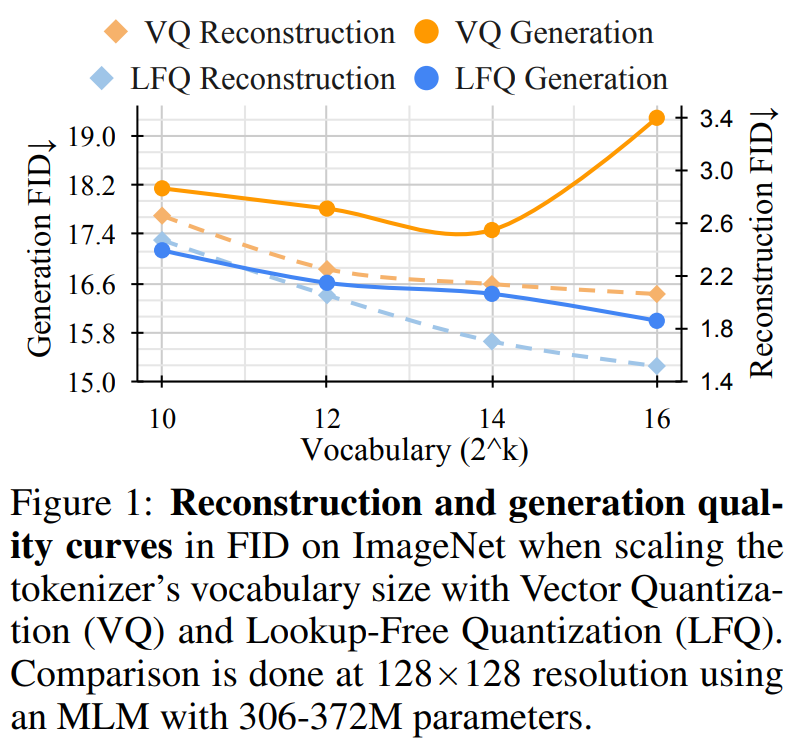
Unlike the VQ-VAE model, this new design completely eliminates the need for embedded lookups, hence the name LFQ. This paper finds that LFQ can improve the quality of language model generation by increasing vocabulary. As shown by the blue curve in Figure 1, both reconstruction and generation improve as vocabulary size increases—a property not observed in current VQ-VAE methods.
There are many LFQ methods available so far, but this article discusses a simple variant. Specifically, the latent space of LFQ is decomposed into the Cartesian product of single-dimensional variables, that is, 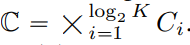 . Assuming that given a feature vector
. Assuming that given a feature vector 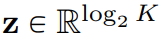 , each dimension of the quantified representation q (z) is obtained from:
, each dimension of the quantified representation q (z) is obtained from:
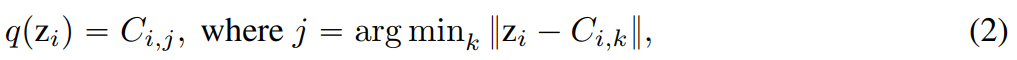
With respect to LFQ, q ( The token index of z) is:
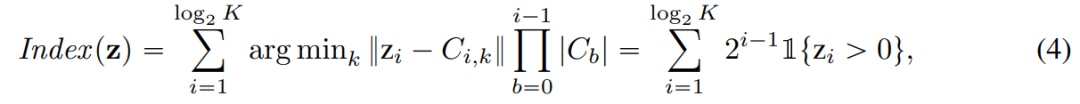
In addition, this article also adds an entropy penalty during the training process:
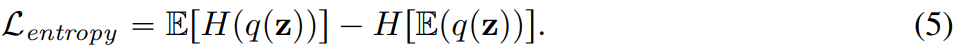
In order to build a joint image-video tokenizer, a redesign is required. The study found that compared with the spatial transformer, the performance of 3D CNN is better
This paper explores two feasible design solutions, as shown in Figure 2b, which combines C-ViViT and MAGVIT; Figure 2c uses temporal causal 3D convolution instead of regular 3D CNN.
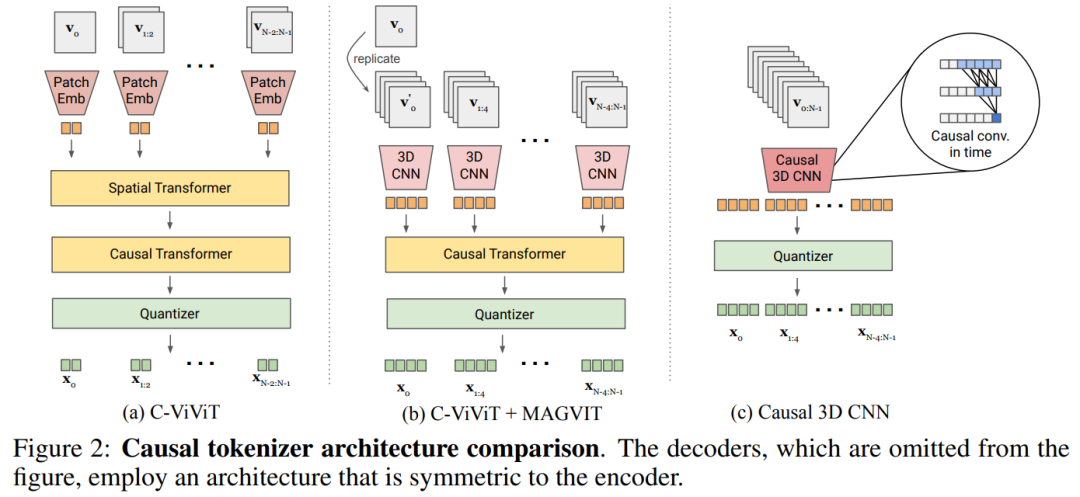
Table 5a empirically compares the designs in Figure 2 and finds that the causal 3D CNN performs best.
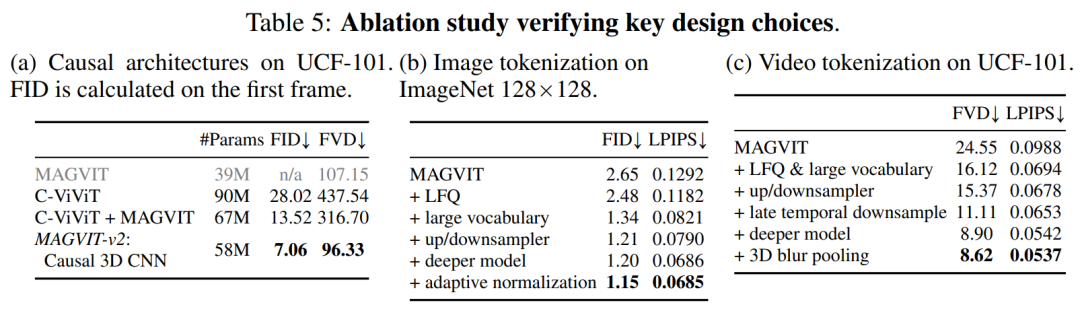
This article makes other architectural modifications to improve MAGVIT performance. In addition to using causal 3D CNN layers, this paper also changes the encoder downsampler from average pooling to strided convolution and adds an adaptive group normalization before the residual block at each resolution in the decoder. Layer etc
This paper verifies the performance of the proposed word segmenter through three parts of experiments: video and image generation, Video compression and action recognition. Figure 3 visually compares the tokenizer with the results of previous research

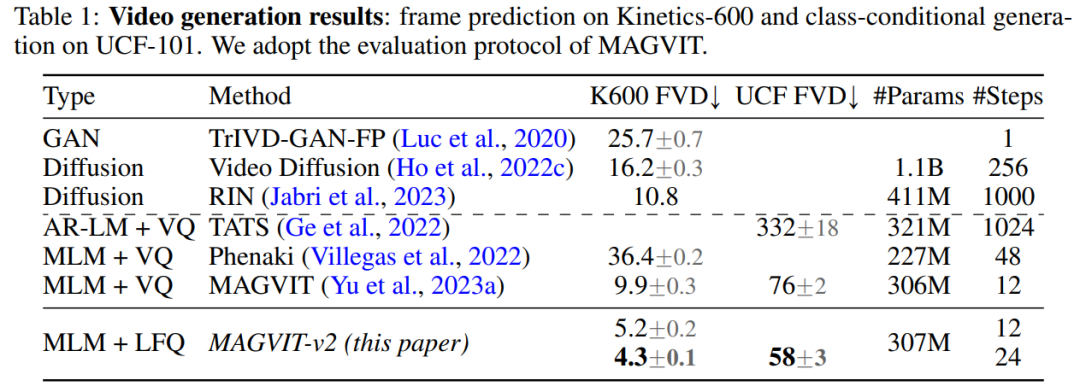
video generation. Table 1 shows that our model outperforms all existing techniques on both benchmarks, demonstrating that a good visual tokenizer plays an important role in enabling LM to generate high-quality videos.
The following is a description of the qualitative sample in Figure 4

By evaluating the image generation results of MAGVIT-v2, this study found that our model exceeded the best in terms of sampling quality (ID and IS) and inference time efficiency (sampling step) under standard ImageNet-like condition settings. The performance of the best diffusion model
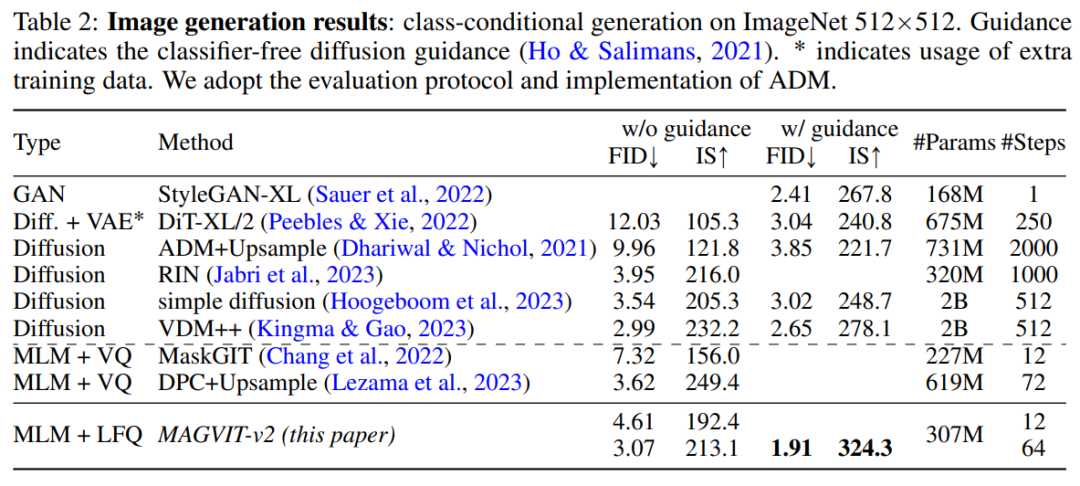
# Figure 5 shows the visualization results.

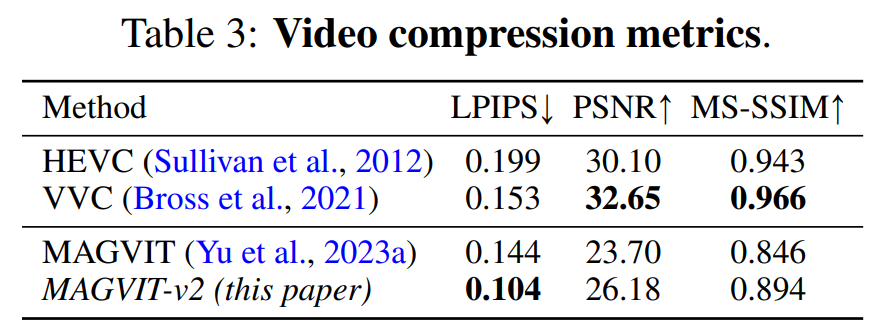
Video compression. The results are shown in Table 3. Our model outperforms MAGVIT on all indicators and outperforms all methods on LPIPS.
As shown in Table 4, MAGVIT-v2 outperforms the previous best MAGVIT
## in these evaluations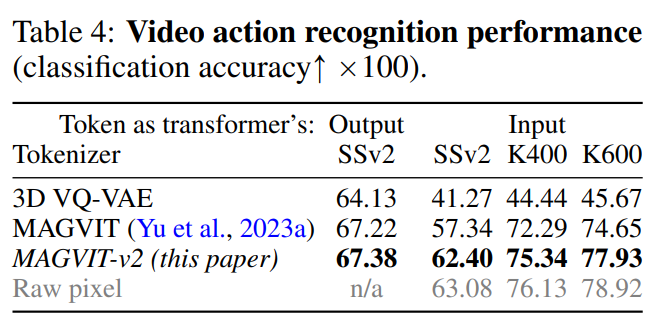 #
#
The above is the detailed content of In image and video generation, the language model defeated the diffusion model for the first time, and tokenizer is the key. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



