


If you’ve ever interacted with any conversational AI bot, you’ll remember some very frustrating moments. For example, the important things you mentioned in the conversation the day before were completely forgotten by the AI...
This is because most current LLMs can only remember limited context. Like students who cram for exams, their flaws will be revealed after a little questioning.
What if the AI assistant could contextually reference conversations from weeks or months ago in a chat, or you could ask the AI assistant to summarize a report that was thousands of pages long, then something like this Is your ability enviable?
In order to make LLM better able to remember and remember more content, researchers have been working hard. Recently, researchers from MIT, Meta AI, and Carnegie Mellon University proposed a method called "StreamingLLM" that enables language models to smoothly process endless text

StreamingLLM The working principle is to identify and save the initial tokens anchored by the model's inherent "attention sinks" for its reasoning. Combined with a rolling cache of recent tokens, StreamingLLM speeds up inference by 22x without sacrificing any accuracy. In just a few days, the project has gained 2.5K stars on the GitHub platform:
# Specifically, StreamingLLM is a A technology that enables language models to accurately remember the score of the last game, the name of a new baby, a lengthy contract, or the content of a debate. Just like upgrading the memory of the AI assistant, it can handle more heavy workloads perfectly

Let’s look at the technical details.
Generally, LLM is limited by the attention window during pre-training. Although there has been a lot of previous work to expand this window size and improve training and inference efficiency, the acceptable sequence length of LLM is still limited, which is not friendly for persistent deployment.
In this paper, the researcher first introduced the concept of LLM stream application and raised a question: "Can it be used with infinite length without sacrificing efficiency and performance? Input deployment LLM?"
When applying LLM to an infinitely long input stream, you will face two main challenges:
1. When decoding stage, the transformer-based LLM will cache the Key and Value status (KV) of all previous tokens, as shown in Figure 1 (a), which may cause excessive memory usage and increase decoding delay;
2. The length extrapolation ability of existing models is limited, that is, when the sequence length exceeds the attention window size set during pre-training, its performance will decrease.
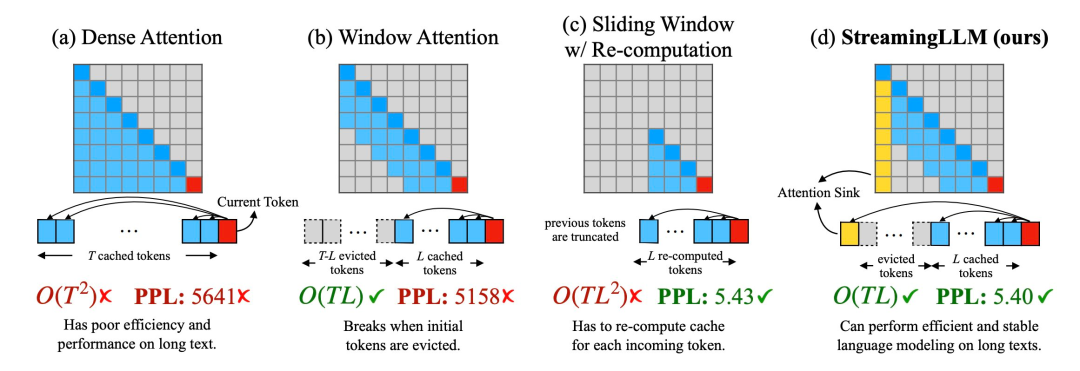
An intuitive method is called Window Attention (Figure 1 b). This method only focuses on the most recent token. Maintaining a fixed-size sliding window on the KV state, although it can ensure that stable memory usage and decoding speed can be maintained after the cache is filled, once the sequence length exceeds the cache size, even just the KV of the first token is evicted. The model will collapse. Another method is to recalculate the sliding window (shown in Figure 1 c). This method will reconstruct the KV state of the recent token for each generated token. Although the performance is powerful, it requires the calculation of secondary attention within the window. The result is significantly slower, which is not ideal in real streaming applications.
In the process of studying the failure of window attention, the researchers discovered an interesting phenomenon: according to Figure 2, a large number of attention scores are assigned to initial tags, regardless of whether these tags are related to language. Related to modeling tasks
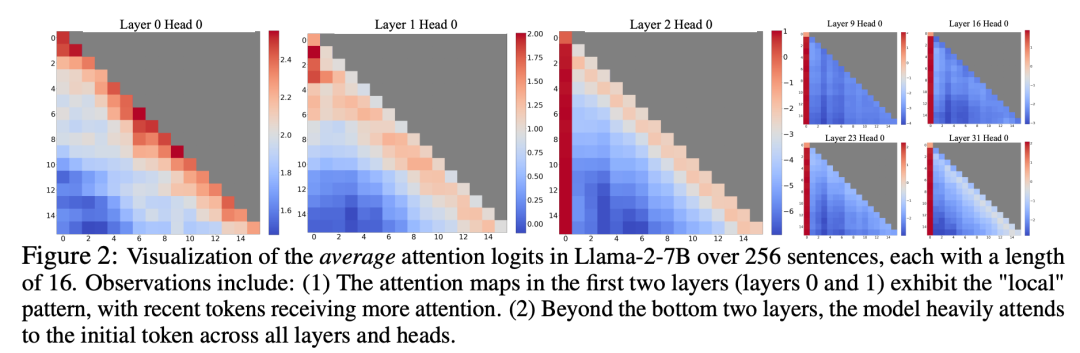
Researchers call these tokens "attention pools": although they lack semantic meaning, but takes up a lot of attention points. The researchers attribute this phenomenon to Softmax (which requires the sum of the attention scores of all context tokens to be 1). Even if the current query does not have a strong match among many previous tokens, the model still needs to transfer these unnecessary attentions. Values are assigned somewhere so that they sum to 1. The reason why the initial token becomes a "pool" is intuitive: due to the characteristics of autoregressive language modeling, the initial token is visible to almost all subsequent tokens, which makes them easier to train as an attention pool.
Based on the above insights, the researcher proposed StreamingLLM. This is a simple yet efficient framework that allows attention models trained with limited attention windows to handle infinitely long text without fine-tuning
StreamingLLM leverages attention The fact that pools have high attention values, retaining these attention pools can make the attention score distribution close to a normal distribution. Therefore, StreamingLLM only needs to retain the KV value of the attention pool token (only 4 initial tokens are enough) and the KV value of the sliding window to anchor the attention calculation and stabilize the performance of the model.
Use StreamingLLM, including Llama-2-[7,13,70] B, MPT-[7,30] B, Falcon-[7,40] B and Pythia [2.9 ,6.9,12] Models including B can reliably simulate 4 million tokens or even more.
Compared to recalculating the sliding window, StreamingLLM is 22.2 times faster without any performance penalty
In experiments, as shown in Figure 3, for text spanning 20K tokens, StreamingLLM’s perplexity is comparable to the Oracle baseline of recomputing the sliding window. At the same time, when the input length exceeds the pre-training window, dense attention fails, and when the input length exceeds the cache size, window attention gets stuck, causing the initial tags to be eliminated
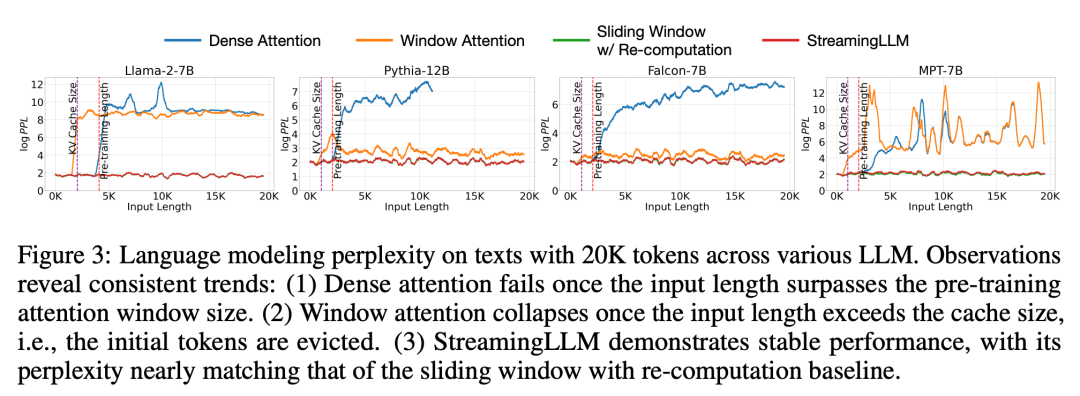
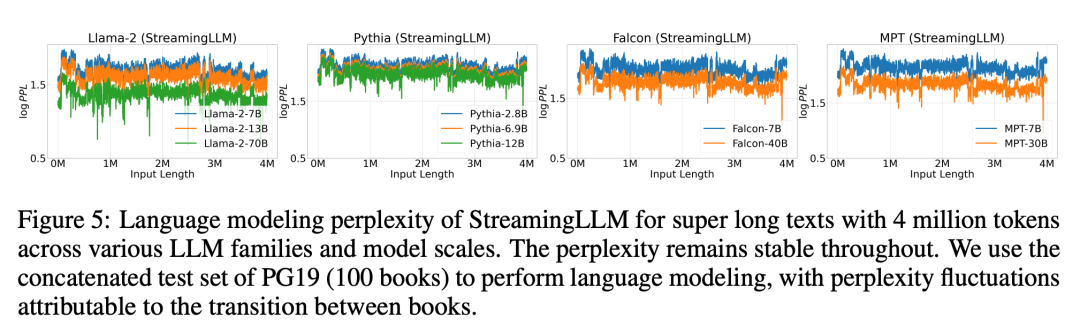
Figure 5 further confirms the reliability of StreamingLLM, which can handle unconventional scale text, including more than 4 million tokens, covering various model families and sizes. These models include Llama-2-[7,13,70] B, Falcon-[7,40] B, Pythia-[2.8,6.9,12] B and MPT-[7,30] B
Subsequently, the researchers confirmed the hypothesis of "attention pool" and proved that the language model can be pre-trained and only requires one attention pool token during streaming deployment. Specifically, they suggest adding an additional learnable token at the beginning of all training samples as a designated attention pool. By pre-training a language model with 160 million parameters from scratch, the researchers demonstrated that our method can maintain the performance of the model. This is in sharp contrast to current language models, which require the reintroduction of multiple initial tokens as attention pools to achieve the same level of performance.
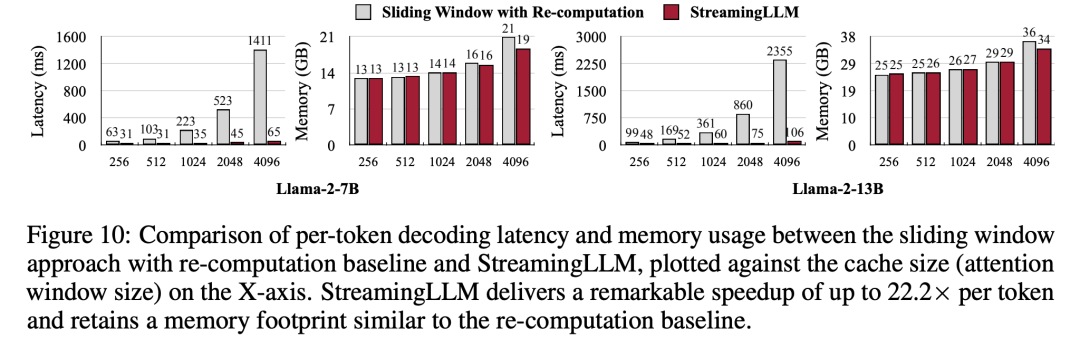
Finally, the researchers compared the decoding latency and memory usage of StreamingLLM with the recalculated sliding window, using Llama-2-7B and Llama- on a single NVIDIA A6000 GPU. 2-13B model was tested. According to the results in Figure 10, as the cache size increases, the decoding speed of StreamingLLM increases linearly, while the decoding delay increases quadratically. Experiments have proven that StreamingLLM achieves impressive speed-up, with the speed of each token increased by up to 22.2 times
More For more research details, please refer to the original paper.
The above is the detailed content of With up to 4 million token contexts and 22 times faster inference, StreamingLLM has become popular and has received 2.5K stars on GitHub.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



