


In time series problems, there is a type of time series that is not equally frequently sampled, that is, the time intervals between two adjacent observations in each group are different. Time series representation learning has been studied a lot in equal-frequency sampling time series, but there is less research in this irregular sampling time series, and the modeling method of this type of time series is different from that in equal-frequency sampling. The modeling methods are quite different
The article introduced today explores the application method of representation learning in the irregular sampling time series problem, drawing on relevant experience in NLP, and in downstream tasks Relatively significant results have been achieved.
 Picture
Picture
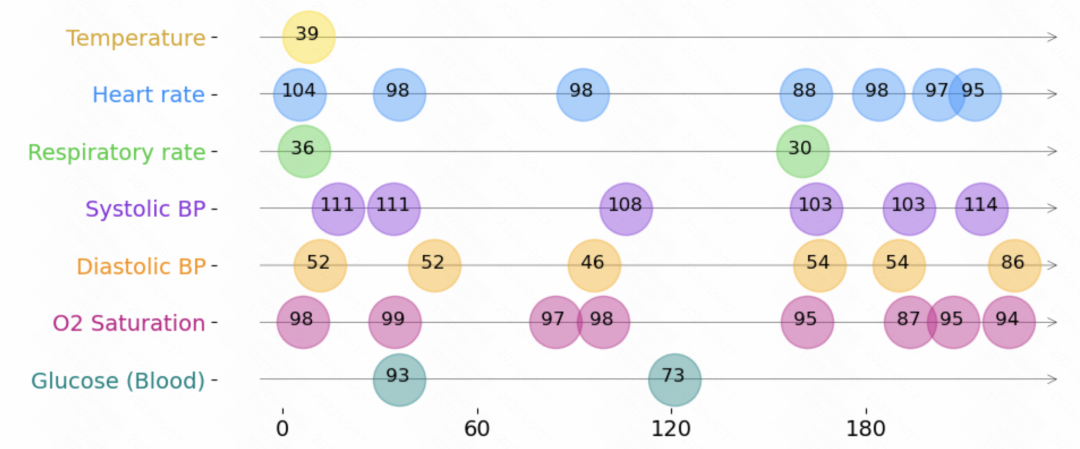
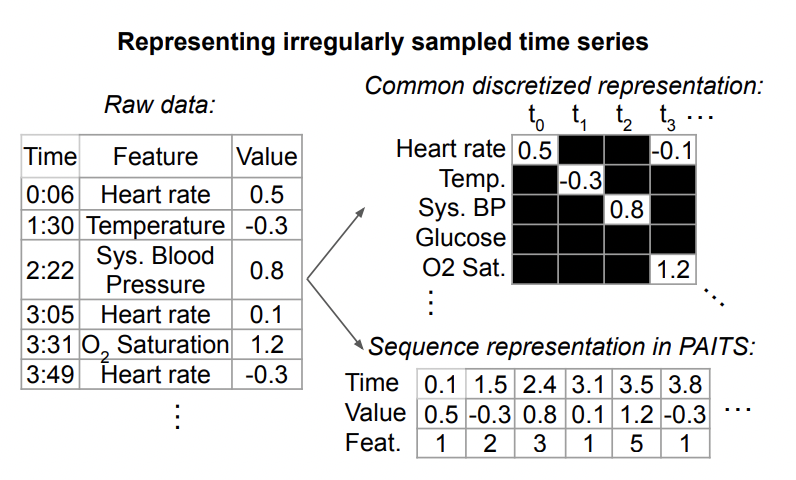
The following is a representation of irregular time series data, as shown below shown. Each time series consists of a set of triples. Each triple contains three fields: time, value, and feature, which respectively represent the sampling time, value, and other features of each element in the time series. In addition to these triples, each sequence also includes other static features that do not change over time, as well as a label for each time series
 Picture
Picture
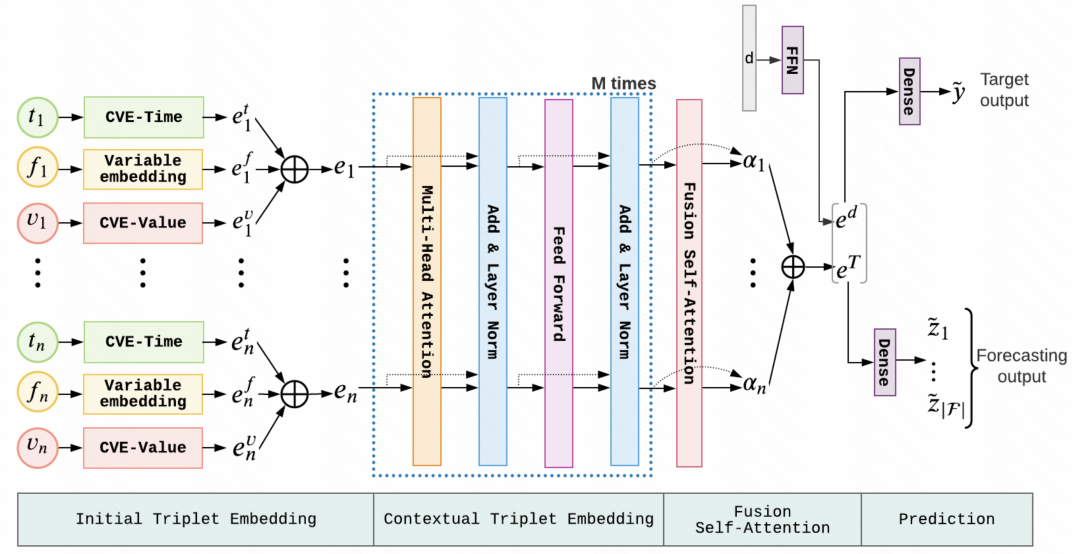
Generally, the common structure of this irregular time series modeling method is to embedding the above triple data separately, splicing them together, and inputting them into models such as transformer. In this way, the information at each moment and the time at each moment are integrated. The representations are fused together and fed into the model to make predictions for subsequent tasks.
 Picture
Picture
In the task of this article, the data used includes not only the data with labels, but also the data without labels, which is used to do Unsupervised pre-training.
The pre-training method in this article refers to the experience in the field of natural language processing and mainly covers two aspects
The design of the pre-training task: In order to process Irregular time series require the design of appropriate pre-training tasks so that the model can learn effective representations from unsupervised data. This article mainly introduces two pre-training tasks based on prediction and reconstruction.
Design of data enhancement methods: In this study, a data enhancement method for unsupervised learning was designed, including adding noise and adding random masks. etc.
In addition, the article also introduces an algorithm for different distribution data sets to explore the optimal unsupervised learning method
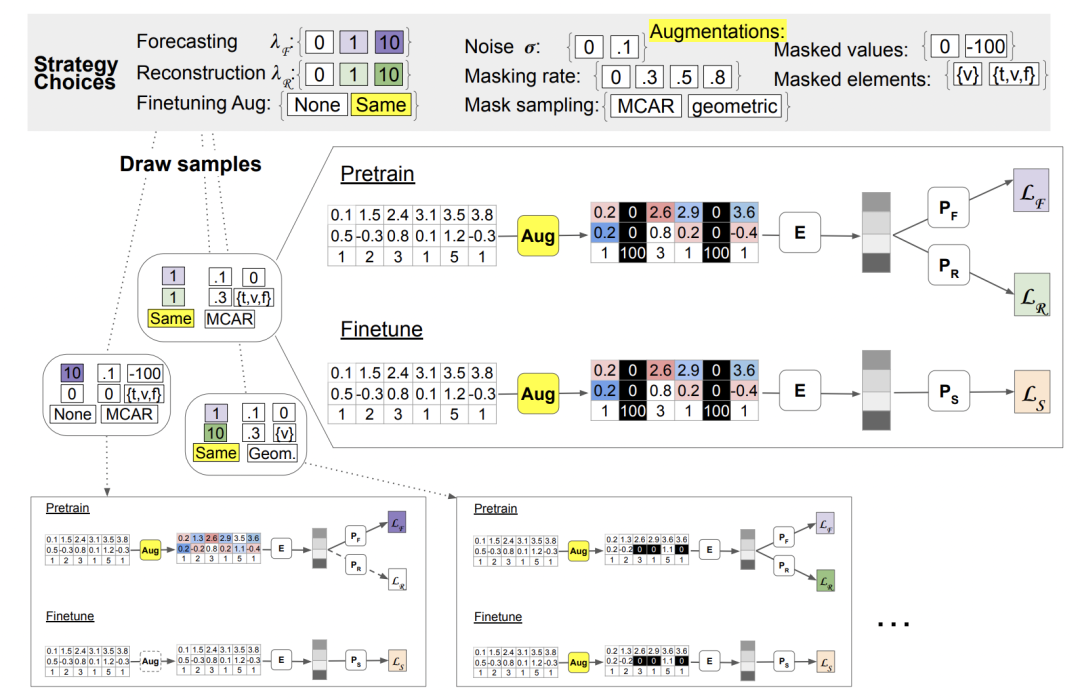
This article proposes two pre-training tasks on irregular time series, namely Forecasting pretraining and Reconstruction pretraining.
In Forecasting pretraining, for each feature in the time series, its value is predicted based on the preorder sequence of a time window of a certain size. The characteristics here refer to the features in the triplet. Since each feature may appear multiple times in a time window, or may not appear at all, the value of the first occurrence of this feature is used as the label for pre-training. The input data includes original series and enhanced time series.
In reconstruction pre-training, first, for an original time series, an enhanced sequence is generated through some data enhancement method, and then the enhanced sequence is used as input, and the encoder generates a representation vector, and then The input is fed into a decoder to restore the original time series. The article uses a mask to guide which parts of the sequence need to be restored. If the mask is all 1, the entire sequence is restored.
After obtaining the pre-training parameters, it can be directly applied to the downstream finetune task. The entire The pretrain-finetune process is shown in the figure below.
 Picture
Picture
In this article, we propose two data enhancement methods. The first method is to add noise, by introducing some random interference into the data to increase the diversity of the data. The second method is random masking, which encourages the model to learn more robust features by randomly selecting parts of the data to mask. These data enhancement methods can help us improve the performance and generalization ability of the model
For each value or time point of the original sequence, the noise can be increased by adding Gaussian noise. The specific calculation method is as follows:
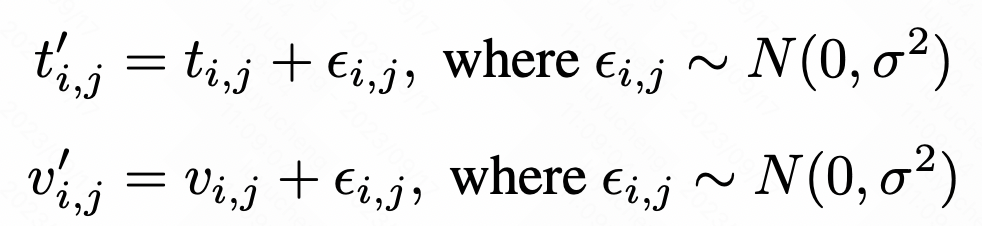 Picture
Picture
The random mask method draws on the ideas in NLP, by randomly selecting time, feature, value and other elements for random masking and replacement, and constructing the enhanced sequentially.
The following figure shows the effects of the above two types of data enhancement methods:
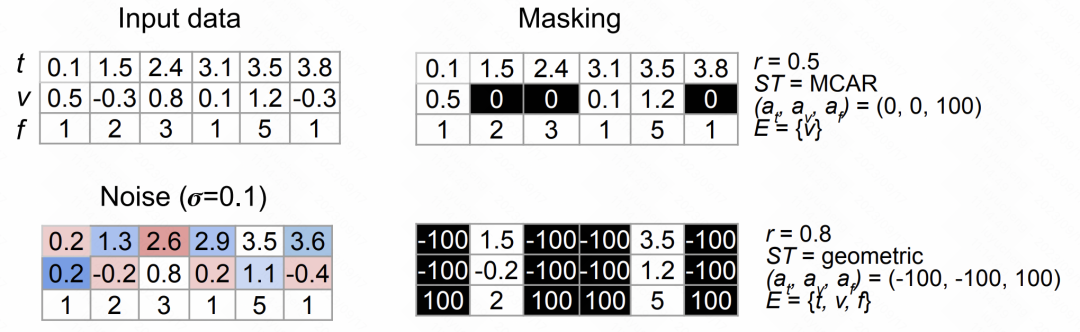 Picture
Picture
In addition, the article will Different combinations of training methods, etc. are used to search for the optimal pre-training method from these combinations for different time series data.
In this article, experiments were conducted on multiple data sets to compare the effects of different pre-training methods on these data sets. It can be observed that the pre-training method proposed in the article has achieved significant performance improvement on most data sets
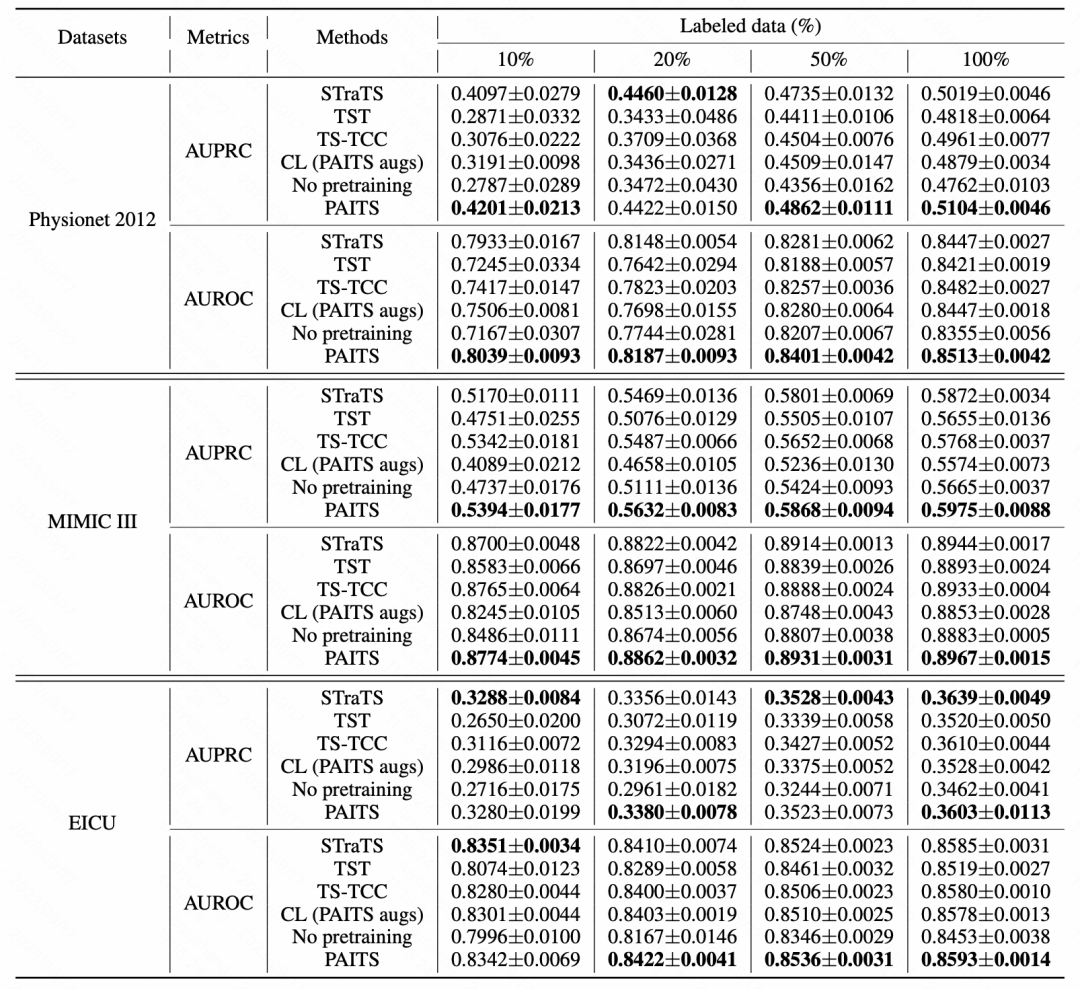 picture
picture
The above is the detailed content of Google: New method for learning time series representation with non-equal frequency sampling. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



