


When the industry was surprised that Baichuan Intelligent released a large model in an average of 28 days, the company did not stop.
At a press conference on the afternoon of September 6, Baichuan Intelligent announced the official open source of the fine-tuned Baichuan-2 large model.
 Zhang Bo, academician of the Chinese Academy of Sciences and honorary dean of the Institute of Artificial Intelligence of Tsinghua University, was at the press conference.
Zhang Bo, academician of the Chinese Academy of Sciences and honorary dean of the Institute of Artificial Intelligence of Tsinghua University, was at the press conference.
This is another new release by Baichuan since the release of the Baichuan-53B large model in August. The open source models include Baichuan2-7B, Baichuan2-13B, Baichuan2-13B-Chat and their 4-bit quantized versions, and they are all free and commercially available.
In addition to the full disclosure of the model, Baichuan Intelligence has also open sourced the Check Point for model training and published the Baichuan 2 technical report, detailing the training details of the new model. Wang Xiaochuan, founder and CEO of Baichuan Intelligence, expressed the hope that this move can help large model academic institutions, developers and enterprise users gain an in-depth understanding of the training process of large models, and better promote the technological development of large model academic research and communities.
Baichuan 2 large model original link: https://github.com/baichuan-inc/Baichuan2
Technical report: https://cdn.baichuan-ai.com/paper/ Baichuan2-technical-report.pdf
Today’s open source model is "smaller" in size compared to large models. Among them, Baichuan2-7B-Base and Baichuan2-13B-Base are both based on 2.6 trillion high-quality multi-dimensional Language data is used for training. On the basis of retaining the good generation and creation capabilities of the previous generation open source model, smooth multi-round dialogue capabilities, and low deployment threshold, the two models have excellent performance in mathematics, code, security, logical reasoning, Semantic understanding and other abilities have been significantly improved.
"To put it simply, Baichuan7B's 7 billion parameter model is already on par with LLaMA2's 13 billion parameter model on the English benchmark. Therefore, we can make a big difference with a small one, and the small model is equivalent to the capabilities of the large model. , and models of the same size can achieve higher performance, comprehensively surpassing the performance of LLaMA2," Wang Xiaochuan said.
Compared with the previous generation 13B model, Baichuan2-13B-Base has a 49% improvement in mathematical capabilities, a 46% improvement in coding capabilities, a 37% improvement in security capabilities, a 25% improvement in logical reasoning capabilities, and a 15% improvement in semantic understanding capabilities. .
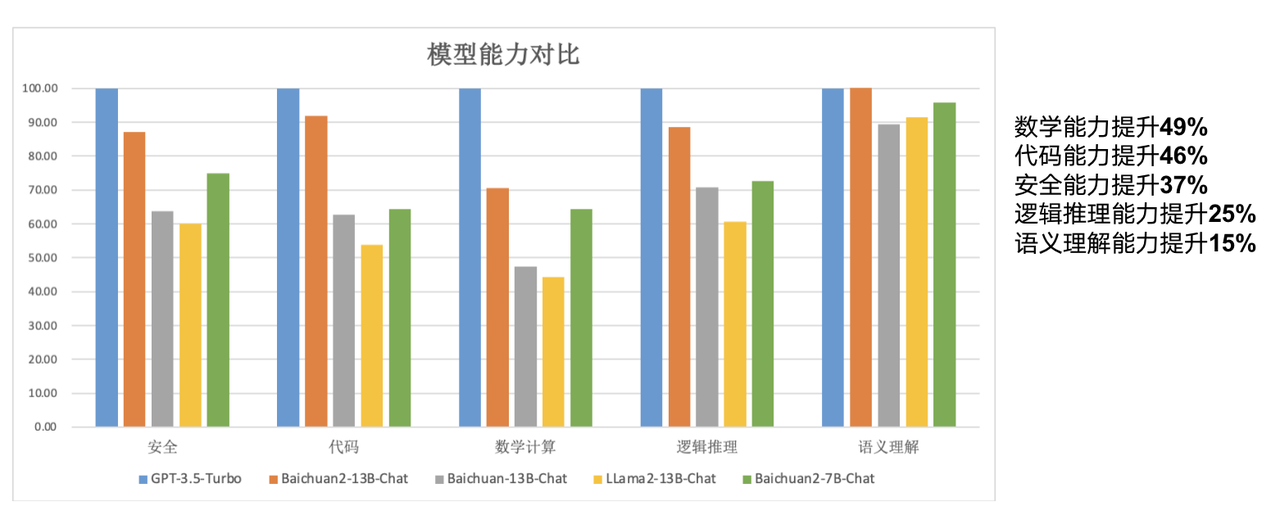
According to reports, on the new model, researchers from Baichuan Intelligence have made a lot of optimizations from data acquisition to fine-tuning.
"We drew on more experience in previous searches, conducted multi-granularity content quality scoring on a large amount of model training data, used 260 million T of corpus level to train 7B and 13B models, and added multi-language support," Wang Xiaochuan said. "We can achieve a training performance of 180TFLOPS in the Qianka A800 cluster, and the machine utilization rate exceeds 50%. In addition, we have also completed a lot of security alignment work."
Two open source projects this time The model performs well on major evaluation lists. In several authoritative evaluation benchmarks such as MMLU, CMMLU, and GSM8K, it leads LLaMA2 by a large margin. Compared with other models with the same number of parameters, the performance is also very eye-catching and the performance is high. The amplitude is better than LLaMA2 competing models of the same size.
What’s more worth mentioning is that according to multiple authoritative English evaluation benchmarks such as MMLU, Baichuan2-7B has 7 billion parameters on the same level as LLaMA2 with 13 billion parameters on mainstream English tasks.
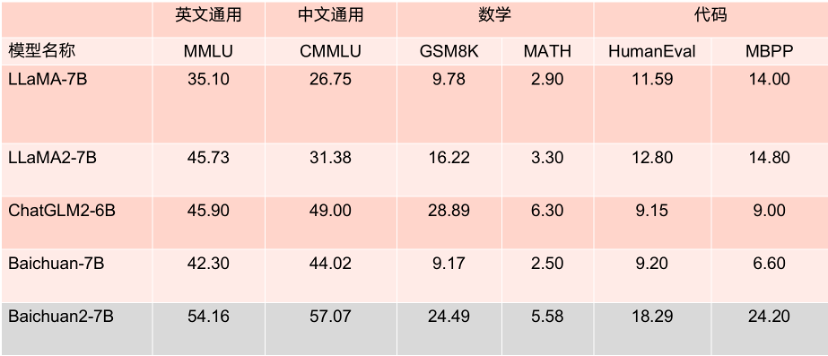
Benchmark results of the 7B parameter model.
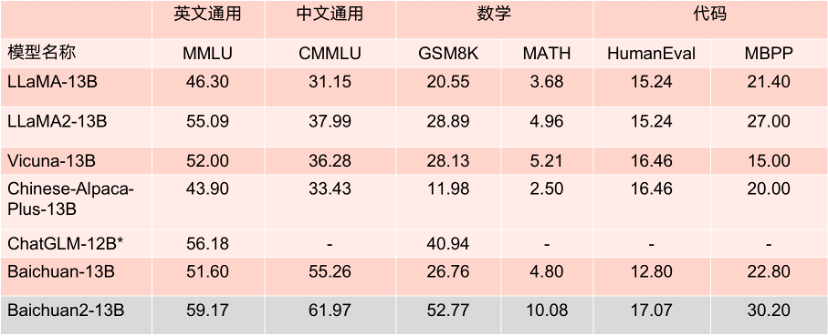
13B Benchmark results of the parametric model.
Baichuan2-7B and Baichuan2-13B are not only fully open to academic research, but developers can also use them for free commercially after applying by email to obtain an official commercial license.
"In addition to model release, we also hope to provide more support to the academic field," Wang Xiaochuan said. "In addition to the technical report, we have also opened up the weight parameter model in the Baichuan2 large model training process. This can help everyone understand pre-training, or perform fine-tuning and enhancement. This is also the first time in China that a company has opened up such a model. Training process."
Large model training includes multiple steps such as acquisition of massive high-quality data, stable training of large-scale training clusters, and model algorithm tuning. Each link requires the investment of a large amount of talents, computing power and other resources. The high cost of training a model from zero to one has hindered the academic community from conducting in-depth research on large model training.
Baichuan Intelligence has open sourced Check Ponit for the entire process of model training from 220B to 2640B. This is of great value for scientific research institutions to study the training process of large models, continued model training and model value alignment, etc., and can promote the scientific research progress of domestic large models.
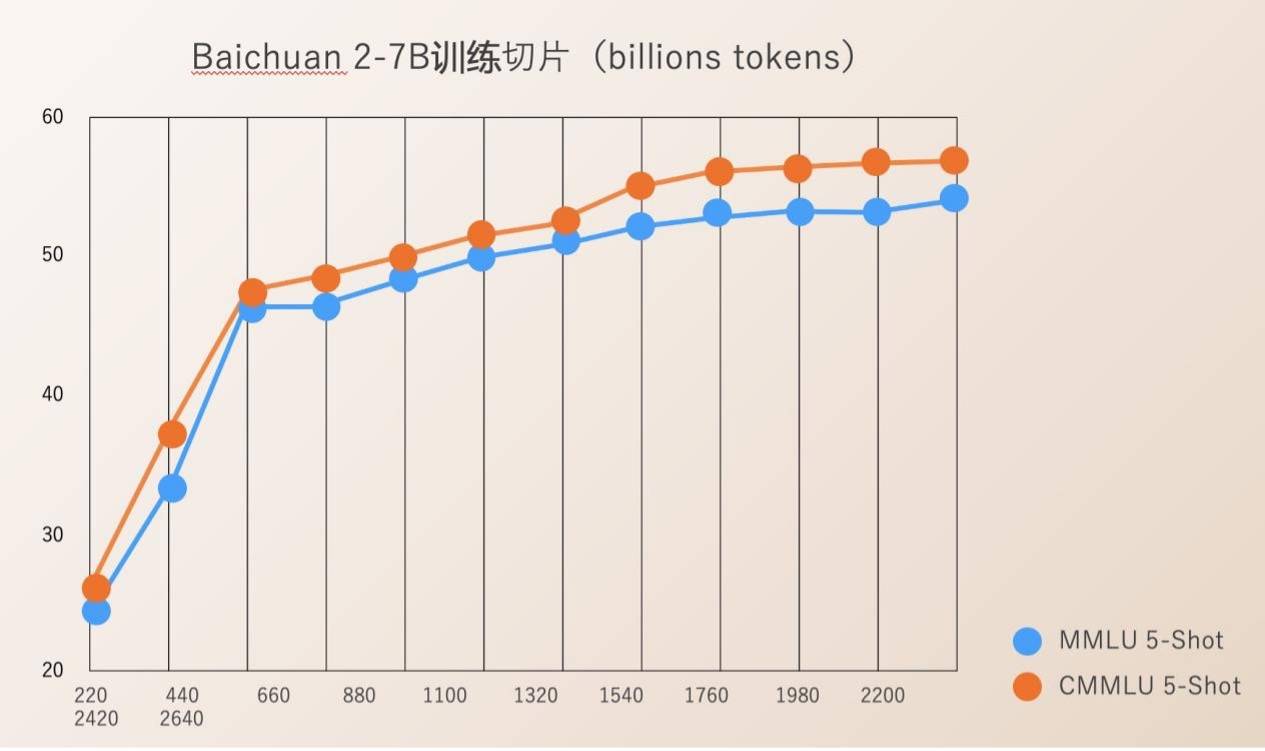
Previously, most open source models only disclosed their model weights to the outside world, and rarely mentioned training details. Developers could only perform limited fine-tuning, making it difficult to conduct in-depth research. .
The Baichuan 2 technical report published by Baichuan Intelligence details the entire process of Baichuan 2 training, including data processing, model structure optimization, scaling law, process indicators, etc.
Since its establishment, Baichuan Intelligence has regarded promoting the prosperity of China's large model ecology through open source as an important development direction of the company. Less than four months after its establishment, it has released two open source free commercial Chinese large models, Baichuan-7B and Baichuan-13B, as well as a search-enhanced large model Baichuan-53B. The two open source large models have been evaluated in many authoritative reviews. It ranks high on the list and has been downloaded more than 5 million times.
Last week, the launch of the first batch of large-scale model public service photography was important news in the field of science and technology. Among the large model companies founded this year, Baichuan Intelligent is the only one that has been registered under the "Interim Measures for the Management of Generative Artificial Intelligence Services" and can officially provide services to the public.
With industry-leading R&D and innovation capabilities in basic large models, the two open source Baichuan 2 models have received positive responses from upstream and downstream companies, including Tencent Cloud, Alibaba Cloud, Volcano Ark, Huawei, and MediaTek Many well-known companies participated in this conference and reached cooperation with Baichuan Intelligent. According to reports, the number of downloads of Baichuan Intelligence’s large models on Hugging Face has reached 3.37 million in the past month.
According to Baichuan Intelligence’s previous plan, this year they will release a large model with 100 billion parameters and launch a “super application” in the first quarter of next year.
The above is the detailed content of Baichuan Intelligent released the Baichuan2 large model: it is fully ahead of Llama2, and the training slices are also open source. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



