


Over the years, three vision backbone networks, Transformer, Large-kernel CNN, and MLP, have achieved great success in a wide range of computer vision tasks. , This is mainly due to their ability to efficiently fuse information on a global scale
Transformer, CNN and MLP are the three mainstream neural networks currently, and they use different ways to implement them. Global scope Token fusion. In the Transformer network, the self-attention mechanism uses the correlation of query-key pairs as the weight of Token fusion. CNN achieves similar performance to Transformer by expanding the size of the convolution kernel. MLP implements another powerful paradigm between all tokens through full connectivity. Although these methods are effective, they have high computational complexity (O(N^2)) and are difficult to deploy on devices with limited storage and computing capabilities, thus limiting the application scope of many models
In order to solve the computationally expensive problem, researchers developed a method called adaptive Fu Efficient global token fusion algorithm of Adaptive Fourier Filter (AFF). This algorithm uses Fourier transform to convert the Token set into the frequency domain, and learns a filter mask capable of adaptive content in the frequency domain to perform adaptive filtering operations on the Token set converted into the frequency domain space
Adaptive Frequency Filters: Efficient Global Token Mixers

##Click this link to access the original text: https://arxiv .org/abs/2307.14008
According to the frequency domain convolution theorem, the mathematical equivalent operation of AFF Token Mixer is a convolution operation performed in the original domain, which is equivalent to the Fourier Hadamard product operation in the domain. This means that AFF Token Mixer can achieve content-adaptive global token fusion by using a dynamic convolution kernel in the original domain, whose spatial resolution is the same as the size of the token set (as shown in the right subfigure of the figure below)
It is well known that dynamic convolution is computationally expensive, especially when using dynamic convolution kernels with large spatial resolution. This cost seems to be too high for efficient/lightweight network design. It's unacceptable. However, the AFF Token Mixer proposed in this article can simultaneously meet the above requirements in an equivalent implementation with low power consumption, reducing the complexity from O (N^2) to O (N log N), thereby significantly improving computing efficiency
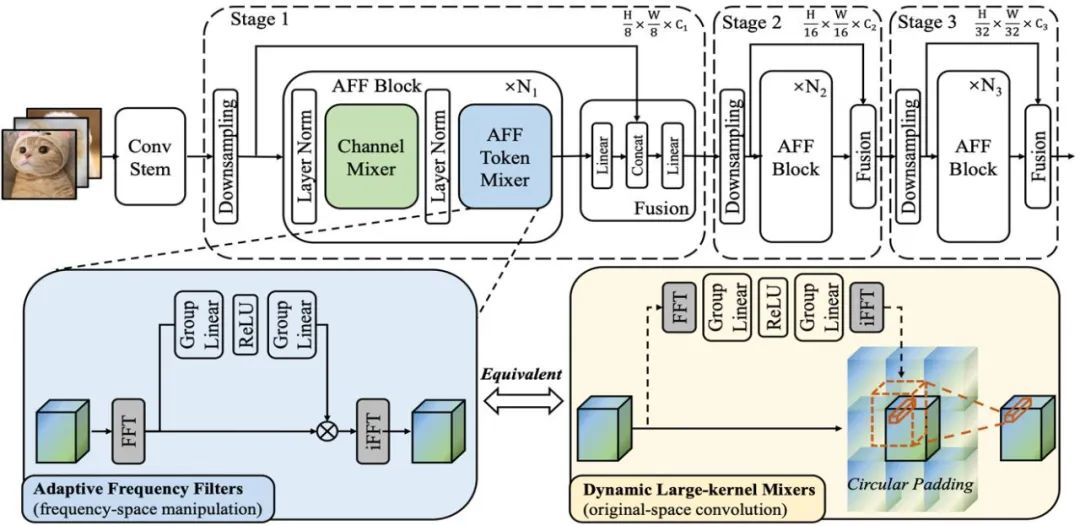
Schematic diagram 1: shows the structure of the AFF module and AFFNet network
By using AFF Token Mixer as the main neural network operation operator, researchers successfully constructed a lightweight neural network called AFFNet. Rich experimental results show that AFF Token Mixer achieves an excellent balance of accuracy and efficiency in a wide range of visual tasks, including visual semantic recognition and dense prediction tasks
Researchers evaluated the performance of AFF Token Mixer and AFFNet on multiple tasks such as visual semantic recognition, segmentation, and detection, and compared them with the most advanced lightweight visual backbone in the current research field. The network was compared. Experimental results show that the model design performs well in a wide range of visual tasks, confirming the potential of AFF Token Mixer as a new generation of lightweight and efficient token fusion operator
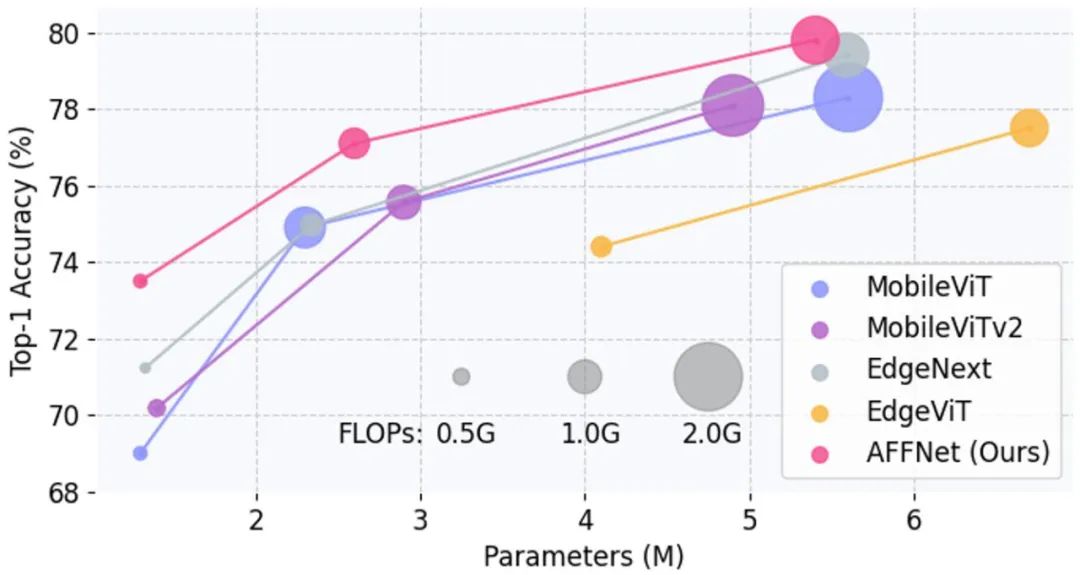
Compared with SOTA, Figure 2 shows the Acc-Param and Acc-FLOPs curves on the ImageNet-1K data set
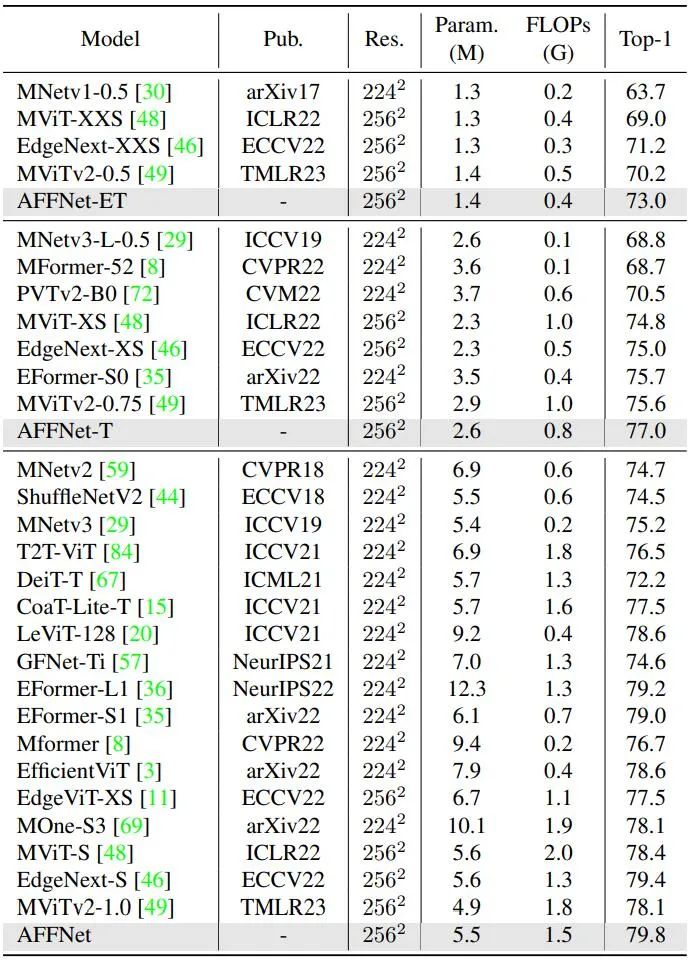
Compare the results of state-of-the-art methods with the ImageNet-1K dataset, see Table 1
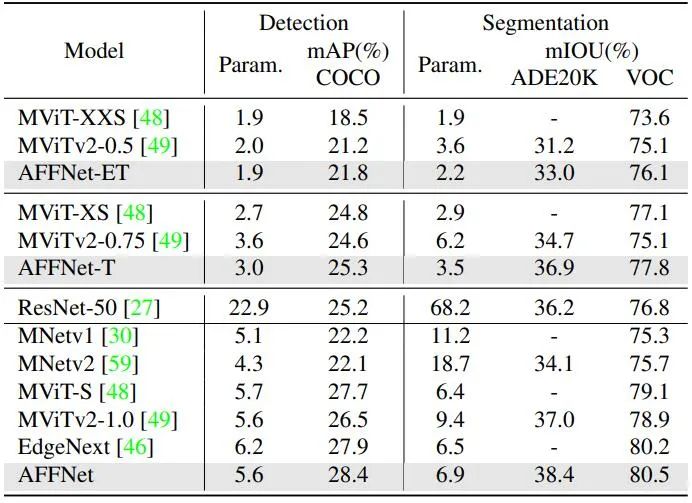
Table 2 shows the results of the visual detection and segmentation tasks with the Comparison of advanced technologies
This study proves that the frequency domain transformation in the latent space plays an important role in global adaptive token fusion and is an efficient and A low-power equivalent implementation. It provides new research ideas for the design of Token fusion operators in neural networks, and provides new development space for deploying neural network models on edge devices, especially when storage and computing capabilities are limited
The above is the detailed content of New backbone of lightweight visual network: efficient Fourier operator token mixer. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



