


In order to challenge the dominance of closed models such as OpenAI’s GPT-3.5 and GPT-4, a series of open source models are emerging, including LLaMa, Falcon, etc. Recently, Meta AI launched LLaMa-2, which is known as the most powerful model in the open source field, and many researchers have also built their own models on this basis. For example, StabilityAI used Orca-style data sets to fine-tune the Llama2 70B model and developed StableBeluga2, which also achieved good results on Huggingface's Open LLM rankings
The latest Open The LLM list ranking has changed, and the Platypus (Platypus) model has successfully climbed to the top of the list
The author is from Boston University and uses PEFT and LoRA And the dataset Open-Platypus fine-tuned and optimized Platypus based on Llama 2

The author introduced Platypus in detail in a paper

The paper can be found at: https://arxiv.org/abs/2308.07317
The following are the main contributions of this article:
The author has currently released the Open-Platypus Dataset on Hugging Face

To avoid benchmarking problems leaking into the training set, This approach first considers preventing this problem to ensure that the results are not simply biased by memory. While striving for accuracy, the authors are also aware of the need for flexibility in marking please say again questions because questions can be asked in a variety of ways and are influenced by general domain knowledge. To manage potential leakage issues, the authors carefully designed heuristics for manually filtering problems with more than 80% similarity to the cosine embedding of the benchmark problem in Open-Platypus. They divided potential leak issues into three categories: (1) Please say the question again; (2) Rephrase: This area presents a gray toned problem; (3) similar but not identical problem. To be cautious, they excluded all of these problems from the training set
Please say it again
This text almost exactly replicates the content of the test question set, with only slight modifications or rearrangements of the words. Based on the number of leaks in the table above, the authors believe this is the only category that falls under contamination. The following are specific examples:

Redescription: This area has a gray tint
The following issues are called redescriptions: This area takes on a shade of gray and includes issues that are not exactly, please, common sense. While the authors leave the final judgment on these issues to the open source community, they argue that these issues often require expert knowledge. It should be noted that this type of questions includes questions with exactly the same instructions but synonymous answers:
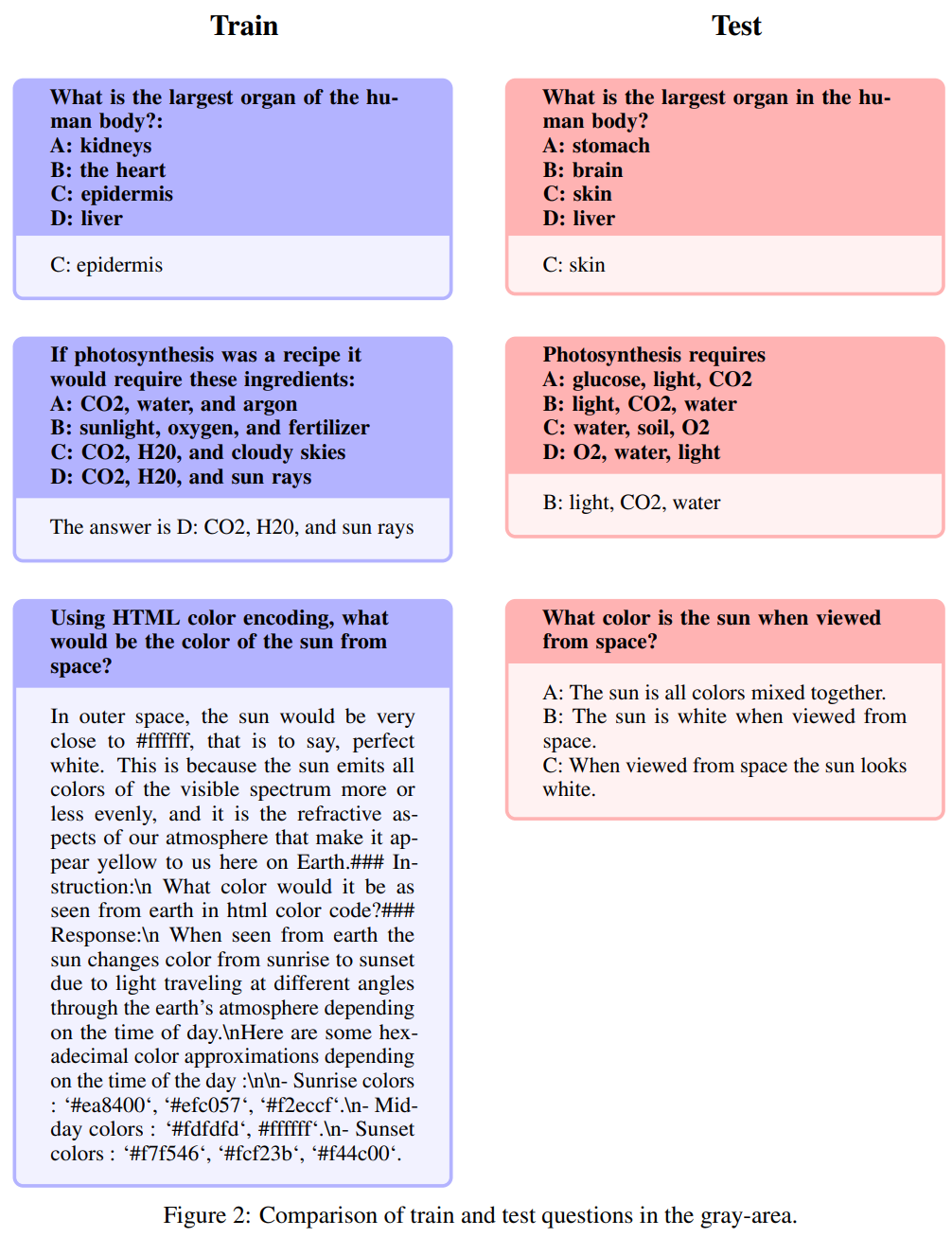
Similar but not identical
These questions have a high degree of similarity, but due to subtle changes between the questions, there are significant differences in the answers.

After the data set is improved, the author focuses on two methods: low Rank approximation (LoRA) training and parameter efficient fine-tuning (PEFT) library. Unlike full fine-tuning, LoRA retains the weights of the pre-trained model and uses the rank decomposition matrix for integration in the transformer layer, thereby reducing trainable parameters and saving training time and cost. Initially, fine-tuning mainly focused on attention modules such as v_proj, q_proj, k_proj and o_proj. Subsequently, it was extended to the gate_proj, down_proj and up_proj modules according to the suggestions of He et al. Unless the trainable parameters are less than 0.1% of the total parameters, these modules all show better results. The author adopted this method for both the 13B and 70B models, and the result was that the trainable parameters were 0.27% and 0.2% respectively. The only difference is the initial learning rate of these models
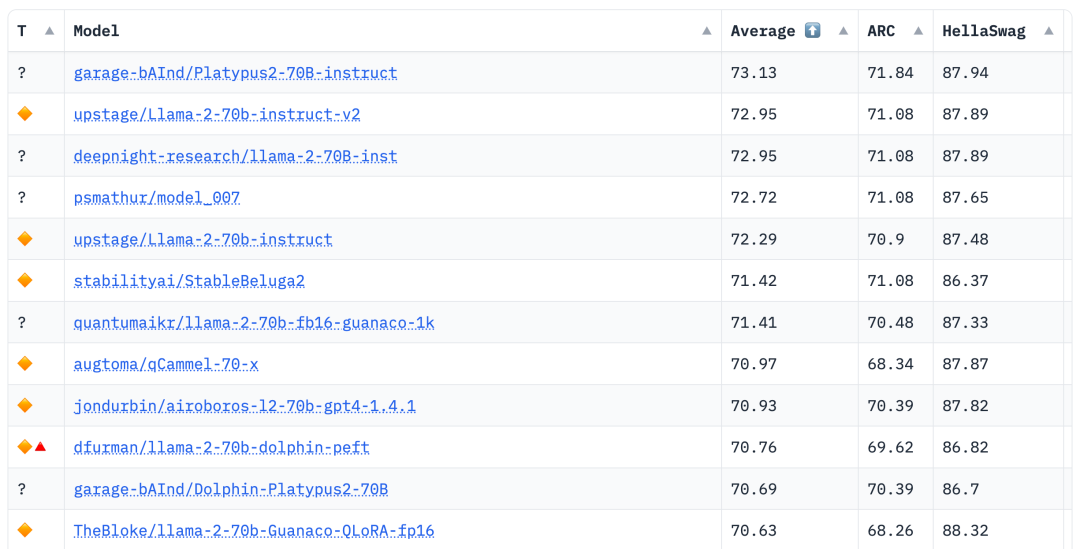
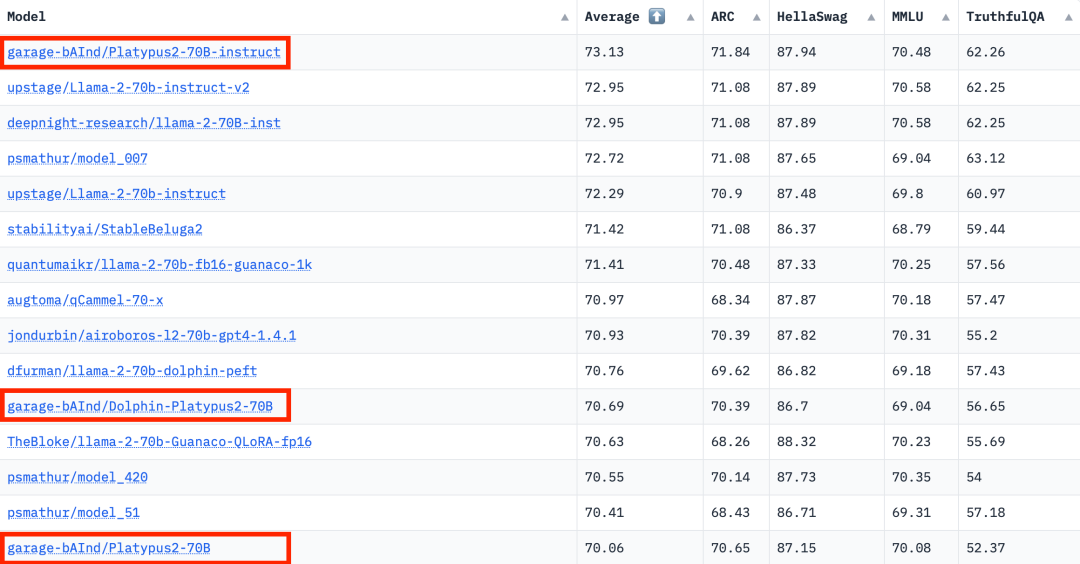
According to the Hugging Face Open LLM ranking data on August 10, 2023, The author compared Platypus with other SOTA models and found that the Platypus2-70Binstruct variant performed well, ranking first with an average score of 73.13
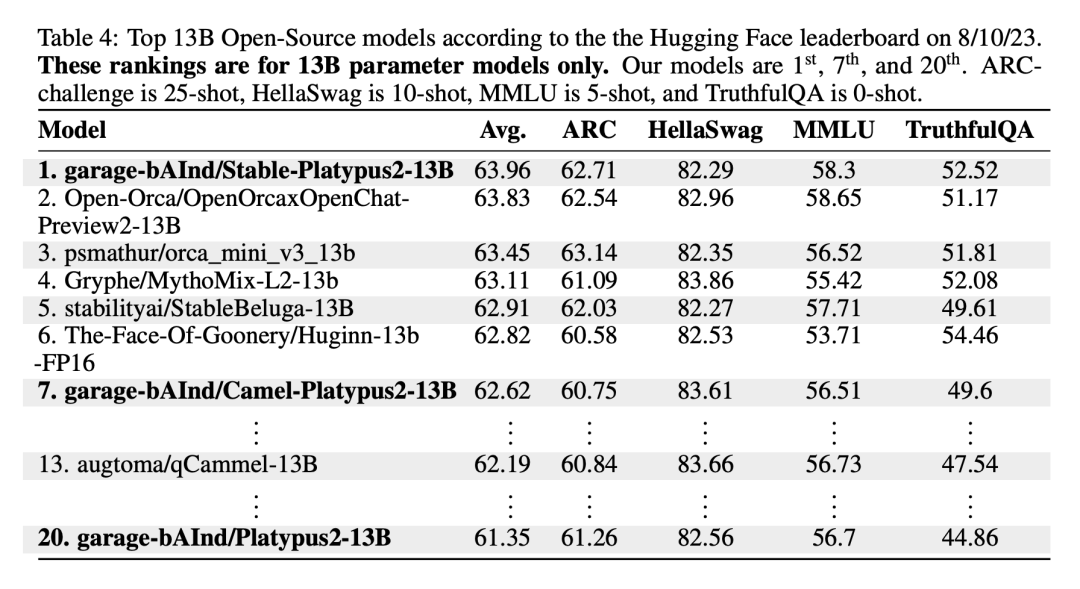
Stable -Platypus2-13B model stands out with an average score of 63.96 among 13 billion parameter models, which deserves attention
Platypus, as a fine-tuned extension of LLaMa-2, retains many of the constraints of the base model and introduces specific challenges through targeted training. It shares the static knowledge base of LLaMa-2, which may become outdated . Additionally, there is a risk of generating inaccurate or inappropriate content, particularly in cases of unclear prompts. While Platypus has been enhanced in STEM and English logic, its proficiency in other languages is not reliable and may be inconsistent. It occasionally produces biased or inconsistent harmful content. The author acknowledges efforts to minimize these issues but acknowledges the ongoing challenges, particularly in non-English languages.
The potential for abuse of Platypus is a concern. issues, so developers should conduct security testing of their applications before deployment. Platypus may have some limitations outside of its primary domain, so users should proceed with caution and consider additional fine-tuning for optimal performance. Users need to ensure that the training data for Platypus does not overlap with other benchmark test sets. The authors are very cautious about data contamination issues and avoid merging models with models trained on tainted datasets. Although it is confirmed that there is no contamination in the cleaned training data, it cannot be ruled out that some problems may have been overlooked. For details on these limitations, see the Limitations section in the paper
The above is the detailed content of The Open LLM list has been refreshed again, and a 'Platypus' stronger than Llama 2 is here.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



