


Extracting datafrom the requested web page, and correctly locating the desired data is the first step.
This article will compare severalcommonly used methods of locating web page elementsin Python crawlers for everyone to learn
"The reference webpage is”
- Traditional
BeautifulSoup Operation- CSS selector based on
BeautifulSoup (similar toPyQuery)XPath - Regular Expression
Dangdang.com best-selling book list:
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1
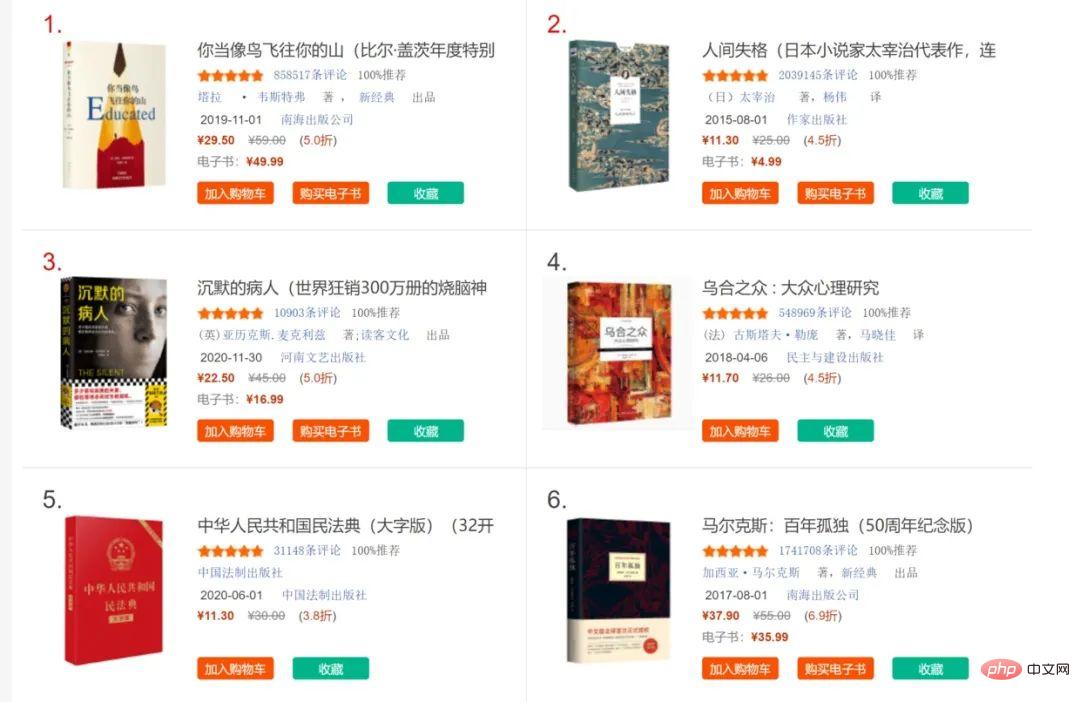
We take the title of the first 20 books as an example. First make sure that the website does not have anti-crawling measures set up, and whether it can directly return the content to be parsed:
import requests url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)
After careful inspection, it is found that the required data is all in the returned content, indicating that it is not required Special consideration is given to anti-crawling measures
After reviewing the web page elements, it can be found that the bibliographic information is included inli, which belongs toclassand isbang_list clearfix bang_list_modeulin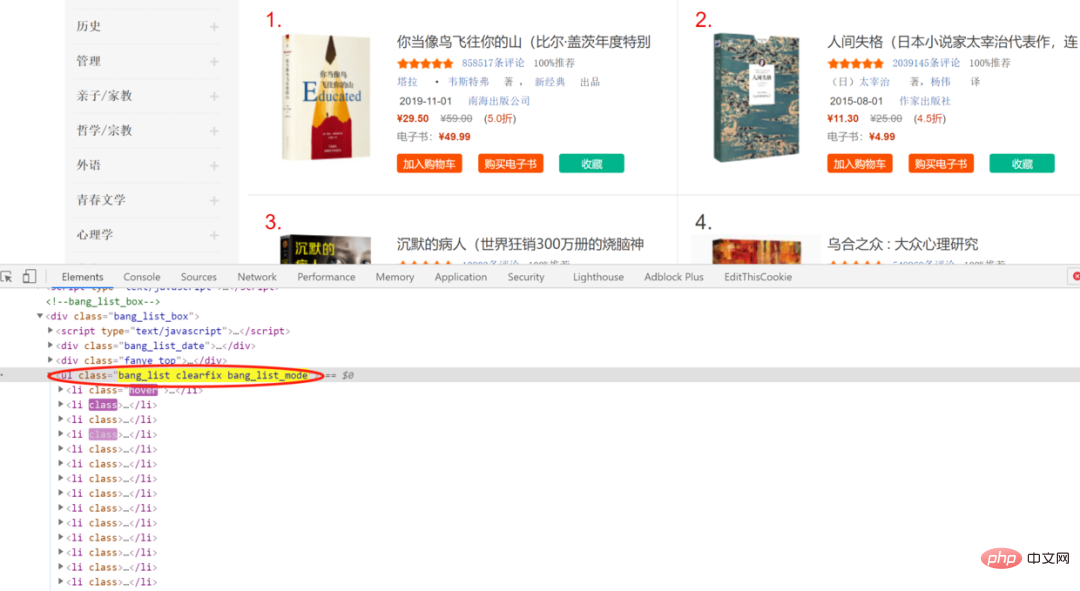
Further inspection can also reveal the corresponding position of the book title, which is an important basis for various analysis methods
The classic BeautifulSoup method usesfrom bs4 import BeautifulSoup, and then usessoup = BeautifulSoup(html, " lxml")Convert the text into a specific standardized structure and use thefindseries of methods to parse it. The code is as follows:
import requests from bs4 import BeautifulSoup url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def bs_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') # 锁定ul后获取20个li for li in li_list: title = li.find('div', class_='name').find('a')['title'] # 逐个解析获取书名 print(title) if __name__ == '__main__': bs_for_parse(response)

Successfully obtained 20 book titles, some of which appear lengthy in writing can be processed through regular expressions or other string methods. This article will not introduce them in detail
这种方法实际上就是 PyQuery 中 CSS 选择器在其他模块的迁移使用,用法是类似的。关于 CSS 选择器详细语法可以参考:http://www.w3school.com.cn/cssref/css_selectors.asp由于是基于 BeautifulSoup 所以导入的模块以及文本结构转换都是一致的:
import requests from bs4 import BeautifulSoup url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") print(soup) if __name__ == '__main__': css_for_parse(response)
然后就是通过soup.select辅以特定的 CSS 语法获取特定内容,基础依旧是对元素的认真审查分析:
import requests from bs4 import BeautifulSoup from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li') for li in li_list: title = li.select('div.name > a')[0]['title'] print(title) if __name__ == '__main__': css_for_parse(response)
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装XPath Helper插件,会大大提高写 XPath 的效率。
之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def xpath_for_parse(response): selector = html.fromstring(response) books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") for book in books: title = book.xpath('div[@class="name"]/a/@title')[0] print(title) if __name__ == '__main__': xpath_for_parse(response)
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是re
首先重新观察直接返回的内容中,需要的文字前后有什么特殊:
import requests import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)

 观察几个数目相信就有答案了:
观察几个数目相信就有答案了:
Related labels:
source:Python当打之年
Previous article:Gold three, silver four, 50 essential Python interview questions (recommended collection)
Next article:Exploding cylinder! Finally, all the Python libraries have been sorted out!
Statement of this Website
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
Latest Articles by Author
2023-08-15 15:07:54
2023-08-15 15:03:09
2023-08-15 15:01:56
2023-08-15 14:56:46
2023-08-15 14:55:25
2023-08-15 14:53:11
2023-08-15 14:48:06
2023-08-15 14:42:31
2023-08-15 14:41:13
2023-08-15 14:39:02
Latest Issues





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



