



According to news on July 27, Microsoft recently launched a speech model called NaturalSpeech2. This model adopts a "potential diffusion" design and is at the zero-sample speech synthesis level. The effect is outstanding. Microsoft claims that this model provides a "commercial-grade" voice/singing solution and can give users a high-quality and diverse speech synthesis experience.
Microsoft conducted a series of demos showcasing NaturalSpeech2's ability to generate speech with different speaker identities, prosody, and styles (such as singing) without samples

▲ The picture source comes from the NaturalSpeech 2 paper
It is reported that, unlike the traditional speech-to-text (TTS) system, Microsoft's NaturalSpeech2 uses "continuous vectors" instead of "discrete markers" to Represent speech, thereby generating more complete speech segments, will not produce the phenomenon of "stick reading (speaking word for word)" that is "lack of emotion".
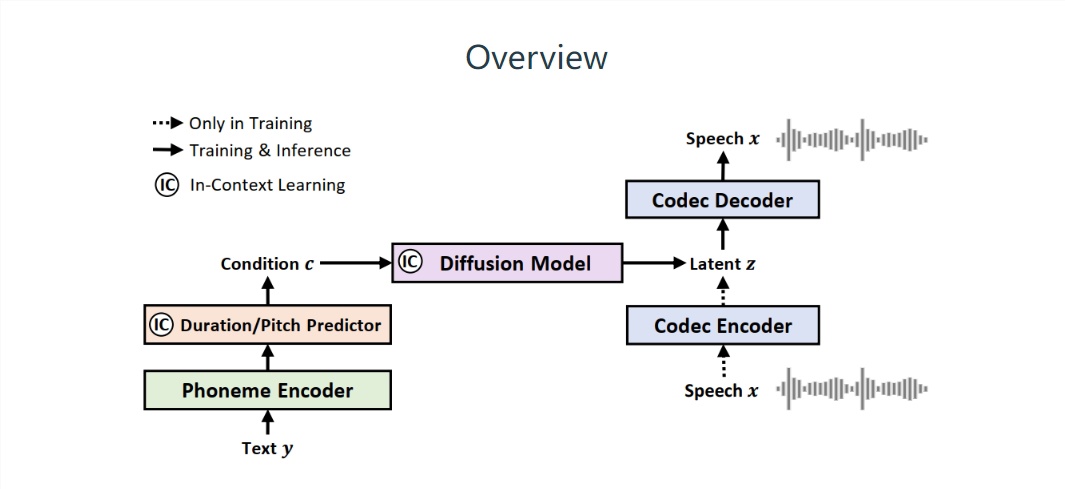
NaturalSpeech2 generates speech and speech prompts under zero sample conditions and real The prosody of the speech is nearly consistent, and the naturalness (measured in CMOS) on the LibriTTS and VCTK test sets is indistinguishable from human speech. The papers of this project have been published on GitHub. Interested IT House friends can
click here to visitThe above is the detailed content of Microsoft's latest NaturalSpeech2 speech synthesis model: provides more accurate speech reconstruction and avoids stick reading effects. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 Solution to failed connection between wsus and Microsoft server
Solution to failed connection between wsus and Microsoft server
 Kernelutil.dll error repair method
Kernelutil.dll error repair method
 The role of index
The role of index
 What are the virtual currencies that may surge in 2024?
What are the virtual currencies that may surge in 2024?
 How to solve the problem of slow server domain name transfer
How to solve the problem of slow server domain name transfer
 math.random function usage
math.random function usage








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



