

/1 Foreword/

#/2 Project Goal/
Get details of upcoming movies from Maoyan Movies.
##/3 Project preparation/ Software:
PyCharmRequired libraries:
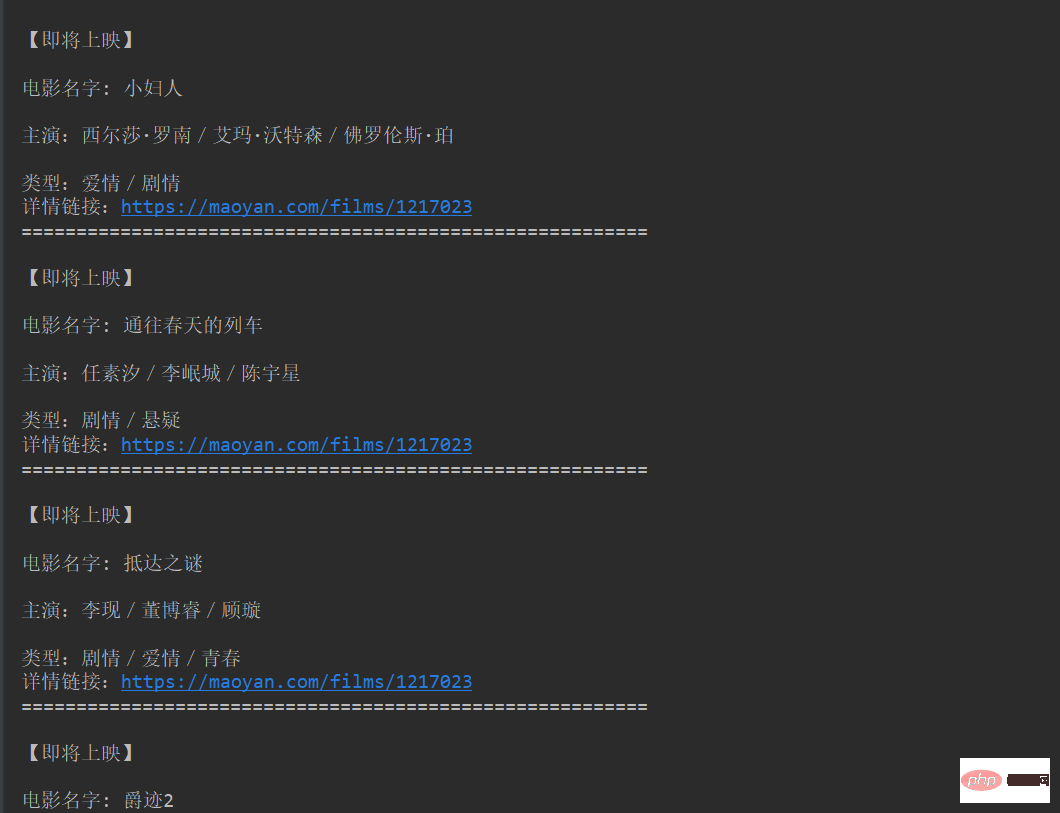
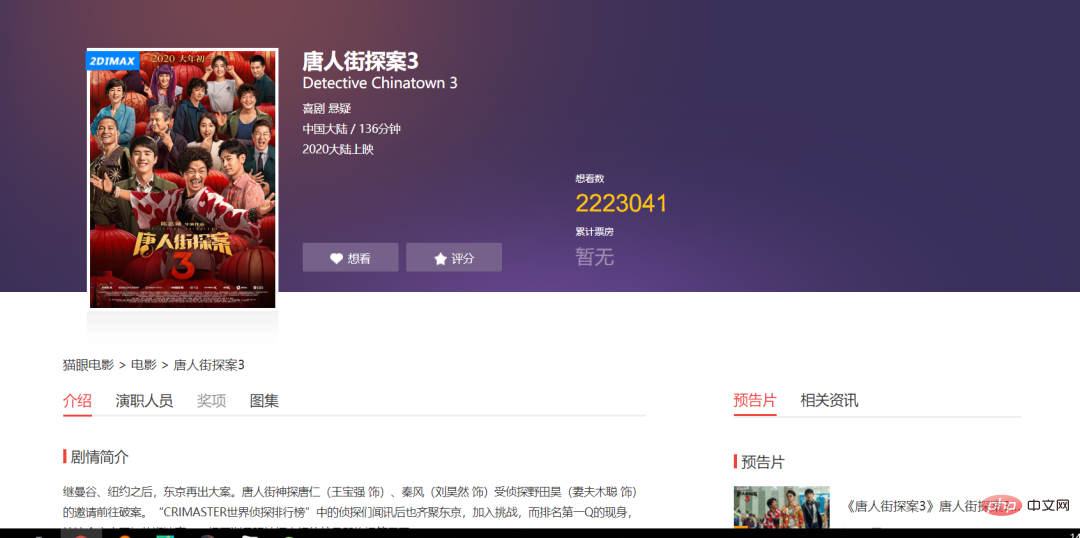
requests, lxml、random、time Plug-in:Xpath ##The website is as follows: Click the button on the next page and observe the changes in the website as follows: When you click the next page, the page offset=() increases by 30 each time, so you can use {} to replace the transformed variable, and then use a for loop to traverse the URL. , to implement multiple URL requests. #/4 Project Implementation/ 1)基准xpath节点对象列表。 /5 Effect display/ 1. Click the green triangle to run the input Start page, end page. 2. After running the program, the result is displayed on the console, as shown below shown. ##3. Click the blue download link to view details online . #/6 Summary/ 2. This article is based on Python web crawler and uses the crawler library to crawl Maoyan movies. https://maoyan.com/films?showType=2&offset={}Copy after loginhttps://maoyan.com/films?showType=2&offset=30
https://maoyan.com/films?showType=2&offset=60
https://maoyan.com/films?showType=2&offset=90
Copy after loginimport requests
from lxml import etree
import time
import random
class MaoyanSpider(object):
def __init__(self):
self.url = "https://maoyan.com/films?showType=2&offset={}"
def main(self):
pass
if __name__ == '__main__':
spider = MaoyanSpider()
spider.main()Copy after login2、随机产生UserAgent。
for i in range(1, 50):
# ua.random,一定要写在这里,每次请求都会随机选择。
self.headers = {
'User-Agent': ua.random,
}Copy after login3、发送请求,获取页面响应。
def get_page(self, url):
# random.choice一定要写在这里,每次请求都会随机选择
res = requests.get(url, headers=self.headers)
res.encoding = 'utf-8'
html = res.text
self.parse_page(html)
Copy after login4、xpath解析一级页面数据,获取页面信息。
# 创建解析对象
parse_html = etree.HTML(html)
# 基准xpath节点对象列表
dd_list = parse_html.xpath('//dl[@class="movie-list"]//dd')
Copy after login2)依次遍历每个节点对象,提取数据。
for dd in dd_list:
name = dd.xpath('.//div[@class="movie-hover-title"]//span[@class="name noscore"]/text()')[0].strip()
star = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][3]/text()')[1].strip()
type = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][2]/text()')[1].strip()
dowld=dd.xpath('.//div[@class="movie-item-hover"]/a/@href')[0].strip()
# print(movie_dict)
movie = '''【即将上映】Copy after login5、定义movie,保存打印数据。
movie = '''【即将上映】
电影名字: %s
主演:%s
类型:%s
详情链接:https://maoyan.com%s
=========================================================
''' % (name, star, type,dowld)
print( movie)Copy after login6、random.randint()方法,设置时间延时。
time.sleep(random.randint(1, 3))
Copy after login7、调用方法,实现功能。
html = self.get_page(url)
self.parse_page(html)
Copy after login
The above is the detailed content of Use a Python web crawler to see what movies are currently playing in theaters. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



