


The open source alpaca large model LLaMA context is equal to GPT-4, with only one simple change!
This paper just submitted by Meta AI shows that after the LLaMA context window is expanded from 2k to 32k, it only requires less than 1000 steps of fine-tuning.
The cost is negligible compared to pre-training.

Expanding the context window means that the AI's "working memory" capacity is increased. Specifically, it can:
More important meaning The question is, can all large alpaca model families based on LLaMA adopt this method at low cost and evolve collectively?
Yangtuo is currently the most comprehensive open source basic model, and has derived many fully open source commercially available large models and vertical industry models.
# Tian Yuandong, the corresponding author of the paper, also excitedly shared this new development in his circle of friends.
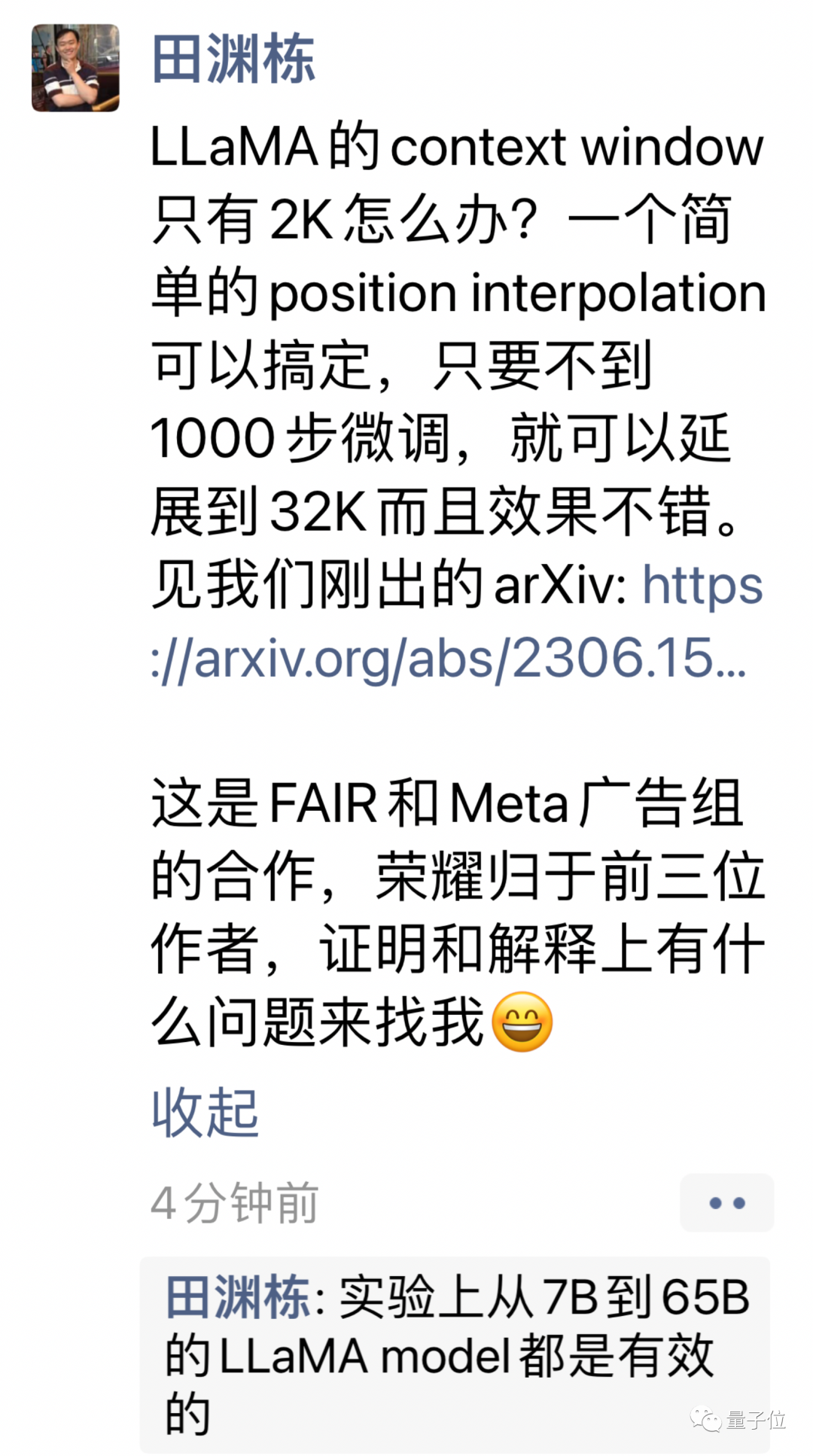
The new method is called position interpolation (Position Interpolation), which is suitable for large models that use RoPE (rotation position encoding) Applicable to all models.
RoPE was proposed by the Zhuiyi Technology team as early as 2021, and has now become one of the most common position encoding methods for large models.

But directly using extrapolation to expand the context window under this architecture will completely destroy the self-attention mechanism.
Specifically, the part beyond the length of the pre-trained context will cause the model perplexity to soar to the same level as an untrained model.
The new method is changed to linearly reduce the position index and expand the range alignment of the front and rear position index and relative distance.

# It is more intuitive to use pictures to express the difference between the two.
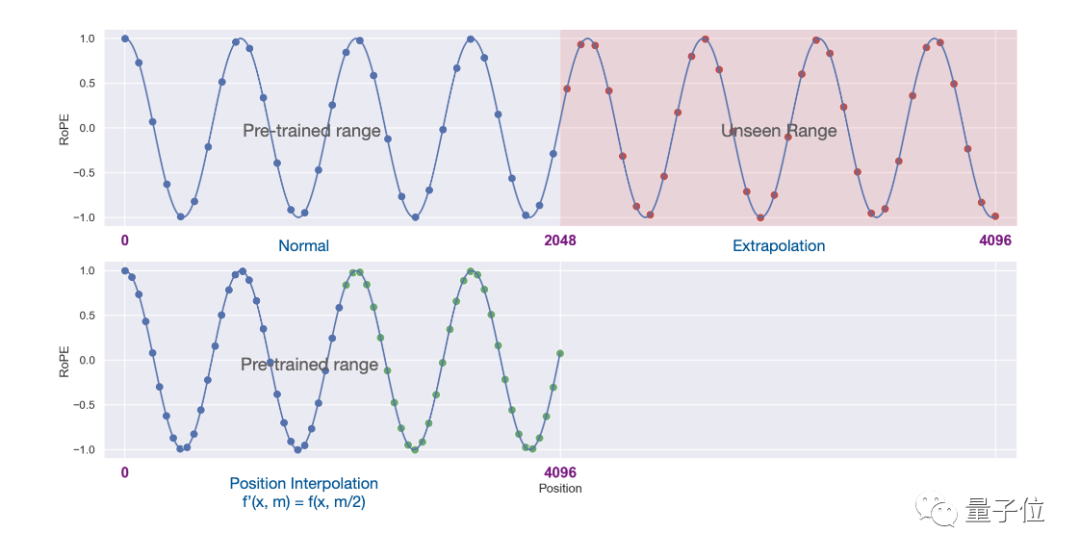
Experimental results show that the new method is effective for LLaMA large models from 7B to 65B.
There is no significant performance degradation in Long Sequence Language Modeling, Passkey Retrieval, and Long Document Summarization.
#In addition to experiments, a detailed proof of the new method is also given in the appendix of the paper.
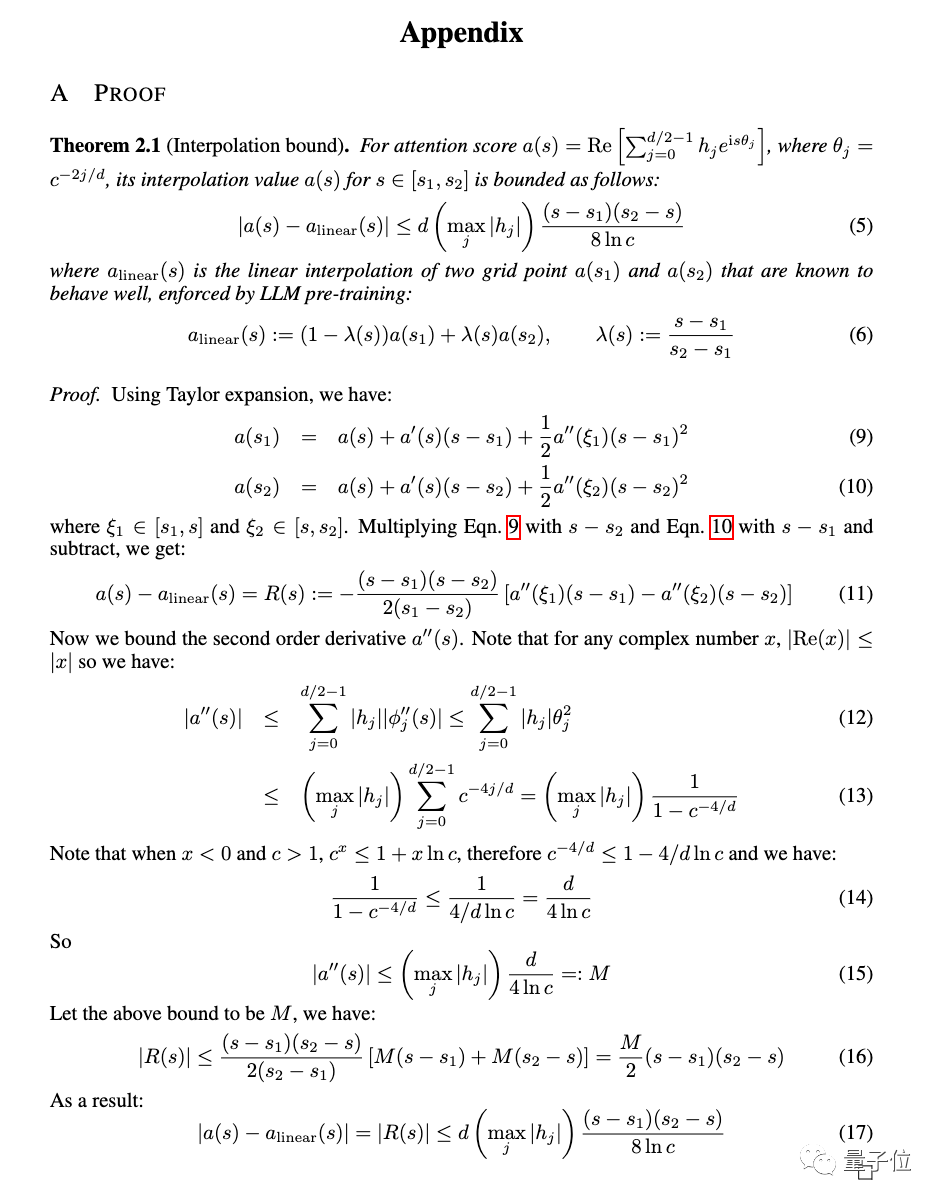
The context window used to be an important gap between open source large models and commercial large models.
For example, OpenAI’s GPT-3.5 supports up to 16k, GPT-4 supports 32k, and AnthropicAI’s Claude supports up to 100k.
At the same time, many large open source models such as LLaMA and Falcon are still stuck at 2k.
Now, Meta AI’s new results have directly bridged this gap.
Expanding the context window is also one of the focuses of recent large model research. In addition to position interpolation methods, there are many attempts to attract industry attention.
1. Developer kaiokendev explored a method to extend the LLaMa context window to 8k in a technical blog.
2. Galina Alperovich, head of machine learning at data security company Soveren, summarized 6 tips for expanding the context window in an article.

3. Teams from Mila, IBM and other institutions also tried to completely remove positional encoding in Transformer in a paper.

Friends who need it can click the link below to view~
Meta paper: //m.sbmmt.com/link/ 0bdf2c1f053650715e1f0c725d754b96
Extending Context is Hard…but not Impossible//m.sbmmt.com/link/9659078925b57e621eb3f9ef19773ac3
The Secret Sauce context window behind 100K in LLMs//m.sbmmt.com/link/09a630e07af043e4cae879dd60db1cac
Positionless Coding Paper//m.sbmmt.com/link/fb6c84779f12283a81d739d8f088fc12
The above is the detailed content of The large model of the alpaca family evolves collectively! 32k context equals GPT-4, produced by Tian Yuandong's team. For more information, please follow other related articles on the PHP Chinese website!
 How to operate Oracle rounding
How to operate Oracle rounding
 How to use frequency function
How to use frequency function
 The difference between win10 home version and professional version
The difference between win10 home version and professional version
 What to do if the chm file cannot be opened
What to do if the chm file cannot be opened
 What are the website building functions?
What are the website building functions?
 What are the differences between Eclipse version numbers?
What are the differences between Eclipse version numbers?
 How to open win11 control panel
How to open win11 control panel
 What does terminal equipment mean?
What does terminal equipment mean?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



