


In recent years, the proportion of "video conferencing" in work has gradually increased, and manufacturers have also developed various technologies such as real-time subtitles to facilitate communication between people with different languages in meetings.
But there is another pain point. If some terms that are unfamiliar to the other party are mentioned in the conversation, and it is difficult to describe them in words, such as the food "Sukiyaki", or " "Went to a park for vacation last week", it is difficult to describe the beautiful scenery to the other party in words; even pointed out that "Tokyo is located in the Kanto region of Japan" and needs a map to show it, etc. If you only use words, it may make the other party more and more angry. More and more confused.

Recently, Google demonstrated at the ACM CHI (Conference on Human Factors in Computing Systems), the top conference on human-computer interaction. Visual Captions, a system that introduces a new visual solution in remote conferencing, can generate or retrieve images in the context of a conversation to improve the other party's understanding of complex or unfamiliar concepts.

## Paper link: https://research.google/pubs/pub52074/
Code link: https://github.com/google/archat
The Visual Captions system is based on a fine-tuned A large language model that can proactively recommend relevant visual elements in open-vocabulary conversations and has been integrated into the open source project ARChat.

In the user survey, the researchers invited 26 participants within the laboratory to interact with those outside the laboratory 10 participants evaluated the system, and more than 80% of users basically agreed that Video Captions can provide useful and meaningful visual recommendations in various scenarios and can improve the communication experience.
Design IdeasBefore development, the researchers first invited 10 internal participants, including software engineers, researchers, UX designers, visual artists, students and practitioners from technical and non-technical backgrounds to discuss the specific needs and expectations for real-time visual enhancement services.
After two meetings, based on the existing text-to-image system, the basic design of the expected prototype system was established, mainly including eight dimensions (denoted as D1 to D8).
D1: Timing, the visual enhancement system can be displayed synchronously or asynchronously with the dialogue
D2: Theme, which can be used to express and understand speech content
D3: Visual, a wide range of visual content, visual types and visual sources can be used
D4: Scale, depending on the size of the meeting, visual Enhancements may vary
#D5: Space, whether the video conference is co-located or in a remote setting
D6: Privacy, these Factors also influence whether visuals should be displayed privately, shared among participants, or public to everyone
D7: Initial state, participants also identified the Different ways of interacting with the system, for example, different levels of "initiative", i.e. users can autonomously determine when the system intervenes in the chat. D8: Interaction, participants envisioned different interaction methods, for example, using voice or gestures for input
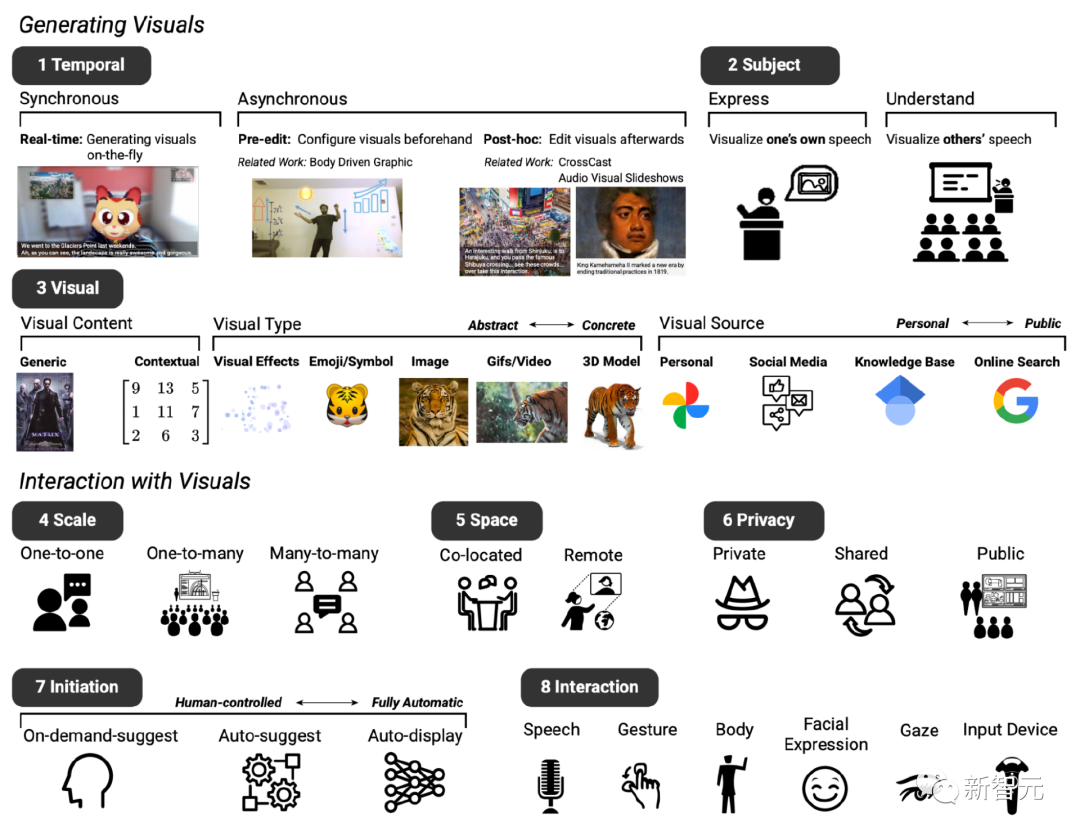
##Use dynamic visual effects to enhance the design space of language communication Based on preliminary feedback, the researchers designed the Video Caption system to focus on generating synchronized visual effects of semantically relevant visual content, type and source. While most of the ideas in exploratory meetings focus on one-to-one remote conversations, Video Caption can also be used for one-to-many (e.g., presenting to an audience) and deployment of many-to-many scenarios (multi-person conference discussions). Beyond that, the visuals that best complement the conversation depend heavily on the context of the discussion, so a purpose-crafted training set is needed. The researchers collected 1595 quadruples, including language, visual content, type, source, covering various contextual scenarios, including daily conversations, lectures, travel guides, etc. For example, the user says "I would love to see it!" (I would love to see it!) corresponding to the visual content and "emoticons" of "face smiling" (emoji) visual type and the visual source of "public search" (public search). "Did she tell you about our trip to Mexico?" Corresponding to the visual content of "Photos from the trip to Mexico", the visual type of "Photo" and "Personal Album" visual source. The data set VC 1.5K is currently open source. 
Data link: https://github.com/google/archat/tree/main/dataset
To predict which visuals complement the conversation, the researchers trained a visual intent based on a large language model using the VC1.5K dataset Intent prediction model.
In the training phase, each visual intent is parsed into the format of "

Based on this format, the system can handle open vocabulary conversations and contextually predict visual content, visual source, and visual type.

This approach is also better in practice than keyword-based approaches, as the latter cannot handle open-ended vocabulary For example, a user may say "Your Aunt Amy will visit this Saturday". If the keyword is not matched, the relevant visual type or visual source cannot be recommended.
The researchers used 1276 (80%) samples in the VC1.5K data set to fine-tune the large language model, and the remaining 319 (20%) samples as test data, and used tokens to accurately The rate index is used to measure the performance of the fine-tuned model, that is, the percentage of correct tokens in the samples that the model predicts correctly.
The final model can achieve 97% training token accuracy and 87% verification token accuracy.
In order to evaluate the practicality of the trained visual subtitle model, the research team invited 89 participants to perform 846 tasks and asked to rate the effect. , 1 means strongly disagree, 7 means strongly agree.
The experimental results show that most participants prefer to see visual effects in conversations (Q1), and 83% gave an evaluation of 5-somewhat agree or above.
Additionally, participants found the visuals displayed to be useful and informative (Q2), with 82% giving a rating higher than 5; high quality (Q3) , 82% gave an evaluation higher than 5 points; and related to the original voice (Q4, 84%).
Participants also found that the predicted visual type (Q5, 87%) and visual source (Q6, 86%) were accurate within the context of the corresponding conversation.
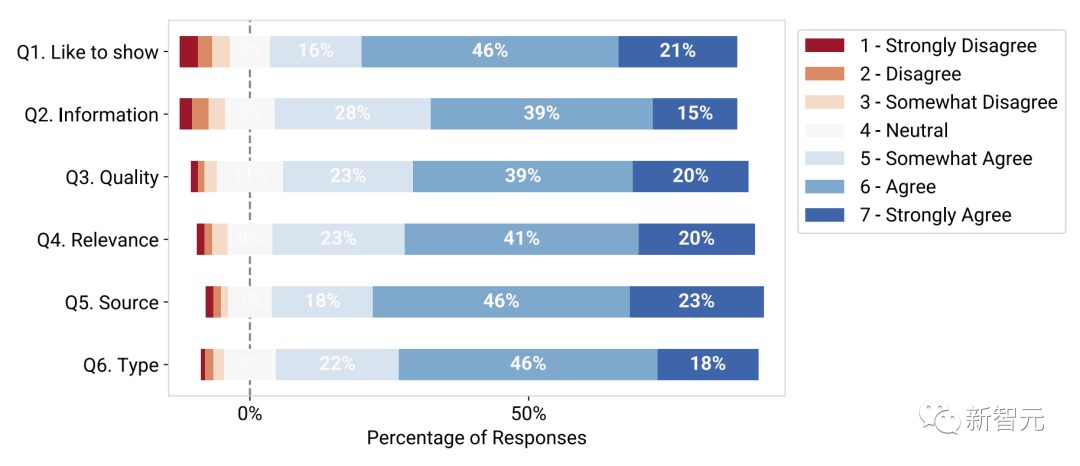
Study participants rate technical evaluation results of visual predictive models
Based on this fine-tuned visual intent prediction model, the researchers developed Visual Captions on the ARChat platform, which can add new interactive widgets directly on the camera stream of video conferencing platforms such as Google Meet. .
In the system workflow, Video Captions can automatically capture the user's voice, retrieve the last sentence, input data into the visual intent prediction model every 100 milliseconds, and retrieve relevant visual effects , and then provide recommended visuals.
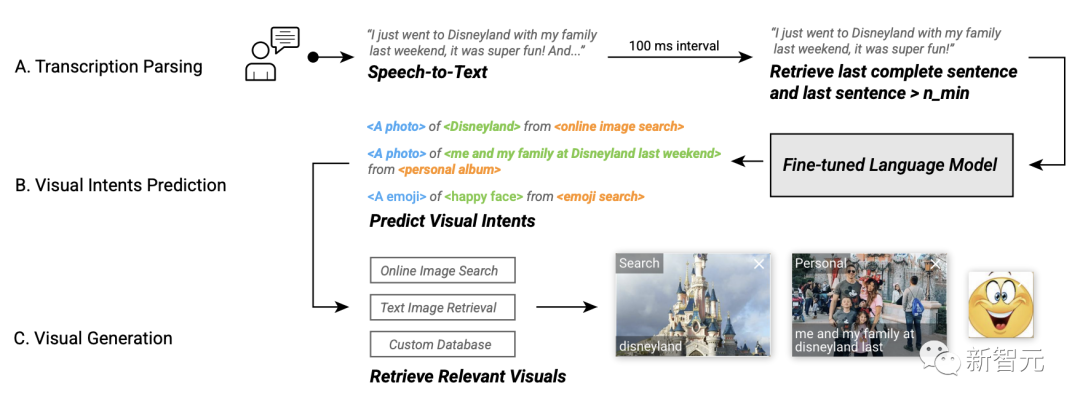
System workflow of Visual Captions
Visual Captions offers three levels of optional initiative when recommending visuals:
Automatic display (high initiative): The system autonomously searches for and displays visuals publicly to all meeting participants Effect without user interaction.
Auto-recommendations (medium initiative): Recommended visuals are displayed in a private scroll view, and then the user clicks on a visual for public display; in this mode, the system Visuals are proactively recommended, but the user decides when and what to display.
On-demand suggestions (low initiative): The system will only recommend visual effects after the user presses the space bar.
Researchers evaluated the Visual Captions system in a controlled lab study (n = 26) and a test phase deployment study (n = 10), and participants found that real-time visuals helped Facilitates live conversations by explaining unfamiliar concepts, resolving language ambiguities, and making conversations more engaging.
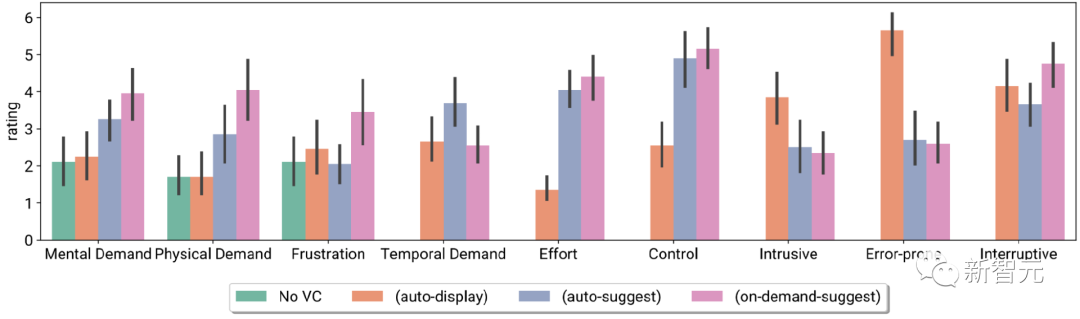
Participants’ task load index and Likert scale ratings, including no VC and three different initiatives Sexual VC
#Participants also reported different system preferences for interacting in the field, i.e. using varying degrees of VC initiative in different meeting scenarios
The above is the detailed content of No more worries about embarrassing 'video conferencing”! Google CHI will release a new artifact Visual Captions: let pictures be your subtitle assistant. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



