


With the rapid development of artificial intelligence technology, new products and technologies such as ChatGPT, New Bing, and GPT-4 have been released one after another. Basic large models will play an increasingly important role in many applications.
Most of the current large language models are autoregressive models. Autoregression means that the model often uses word-by-word output when outputting, that is, when outputting each word, the model needs to use the previously output words as input. This autoregressive mode usually restricts the full utilization of parallel accelerators during output.
In many application scenarios, the output of a large model is often very similar to some reference texts, such as in the following three common scenarios:
1. Retrieval enhanced generation
When retrieval applications such as New Bing respond to user input, they will first return some information related to the user input. Relevant information is then used to summarize the retrieved information using a language model, and then answers the user input. In this scenario, the model's output often contains a large number of text fragments from the search results.
2. Use cached generation
#In the process of large-scale deployment of language models, historical input and output will is cached. When processing new input, the retrieval application looks for similar input in the cache. Therefore, the output of the model is often very similar to the corresponding output in the cache.
3. Generation in multi-turn conversations
When using applications such as ChatGPT, users often use models based on The output repeatedly requested modifications. In this multi-turn dialogue scenario, the multiple outputs of the model often have only a small amount of change and a high degree of repetition.
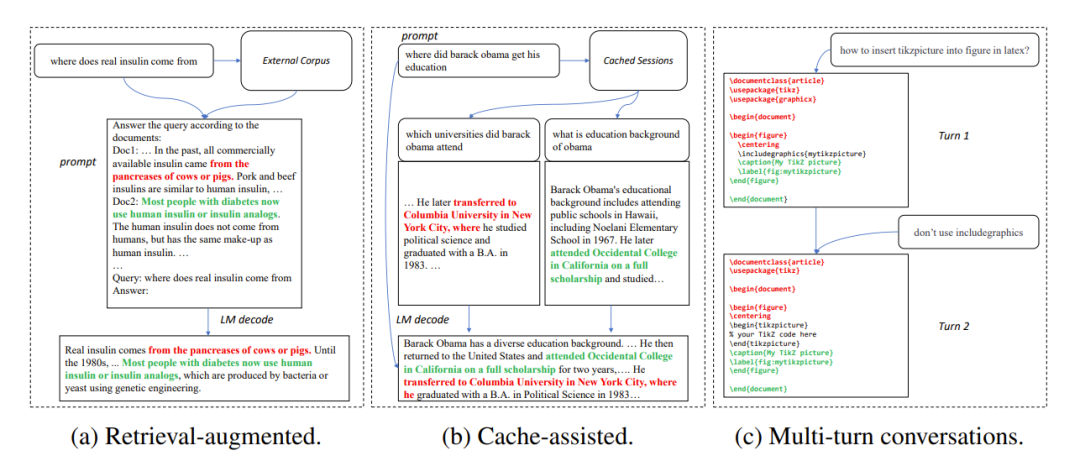
Figure 1: Common scenarios where the output of a large model is similar to the reference text
Based on the above observations, the researchers used the repeatability of reference text and model output as a focus to break through the autoregressive bottleneck, hoping to improve the utilization of parallel accelerators, accelerate large language model inference, and then A method LLM Accelerator is proposed that uses the repetition of output and reference text to output multiple words in one step.
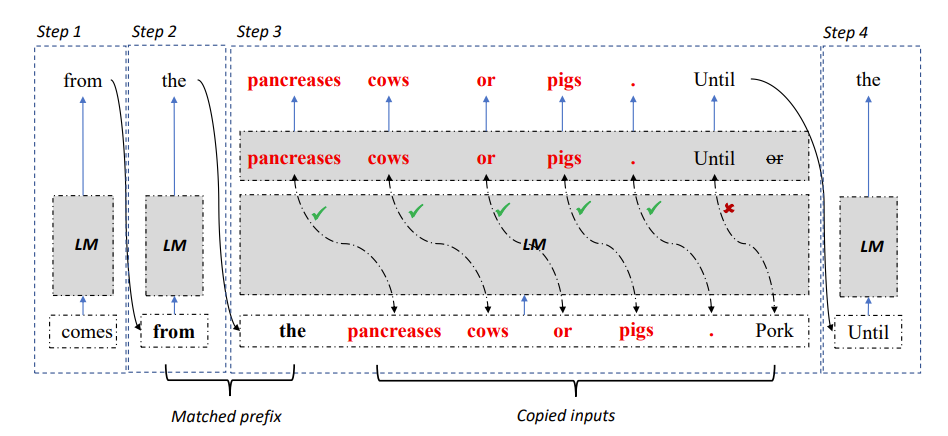
Figure 2: LLM Accelerator decoding algorithm
Specifically, at each decoding step, let the model first match the existing output results and the reference text. If a reference text is found to match the existing output, then the model is likely to postpone the existing reference text to continue output. .
Therefore, the researchers added subsequent words of the reference text as input to the model, so that one decoding step can output multiple words.
In order to ensure the accuracy of input and output, the researchers further compared the words output by the model with the words input from the reference document. If the two are inconsistent, the incorrect input and output results will be discarded.
The above method can ensure that the decoding results are completely consistent with the baseline method, and can increase the number of output words in each decoding step, thereby achieving lossless acceleration of large model inference.
LLM Accelerator does not require additional auxiliary models, is simple to use, and can be easily deployed in various application scenarios.
Paper link: https://arxiv.org/pdf/2304.04487.pdf
Project Link: https://github.com/microsoft/LMOps
Using LLM Accelerator, there are two hyperparameters that need to be adjusted.
The first is the number of matching words between the output required to trigger the matching mechanism and the reference text: the longer the number of matching words, the more accurate it is, which can better ensure that the words copied from the reference text are correct output and reduce inaccuracies. Necessary triggering and computation; shorter matches, fewer decoding steps, potentially faster speedup.
The second is the number of words copied each time: the more words copied, the greater the acceleration potential, but it may also cause more incorrect output to be discarded, which wastes computing resources. Researchers have found through experiments that more aggressive strategies (matching single word triggers, copying 15 to 20 words at a time) can often achieve better acceleration ratios.
In order to verify the effectiveness of LLM Accelerator, the researchers conducted experiments on retrieval enhancement and cache-assisted generation, and constructed experimental samples using the MS-MARCO paragraph retrieval data set.
In the retrieval enhancement experiment, the researchers used the retrieval model to return the 10 most relevant documents for each query, and then spliced them into the query as model input. These 10 documents were used as Reference text.
In the cache-assisted generation experiment, each query generates four similar queries, and then uses the model to output the corresponding query as the reference text.
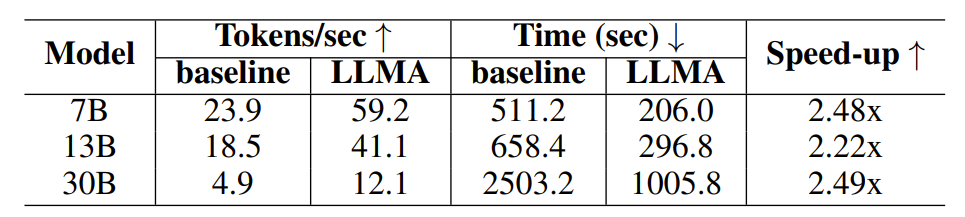
Table 1: Time comparison under retrieval enhanced generation scenario
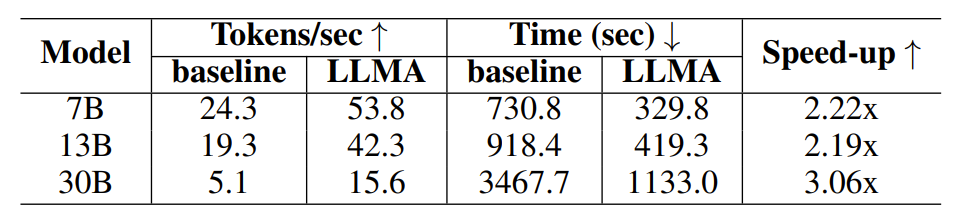
Table 2: Time comparison in the generation scenario using cache
The researchers used the output of the Davinci-003 model obtained through the OpenAI interface as the target output to obtain high-quality output. After obtaining the required input, output and reference text, the researchers conducted experiments on the open source LLaMA language model.
Since the output of the LLaMA model is inconsistent with the Davinci-003 output, the researchers used a goal-oriented decoding method to test the speedup ratio under the ideal output (Davinci-003 model result) .
The researchers used Algorithm 2 to obtain the decoding steps required to generate the target output during greedy decoding, and forced the LLaMA model to decode according to the obtained decoding steps.

Figure 3: Using Algorithm 2 to obtain the decoding steps required to generate the target output during greedy decoding
For models with 7B and 13B parameters, the researchers conducted experiments on a single 32G NVIDIA V100 GPU; for models with 30B parameters, they conducted experiments on four identical GPUs Conduct experiments on. All experiments use half-precision floating point numbers, decoding is greedy decoding, and the batch size is 1.
Experimental results show that LLM Accelerator has achieved two to three times the performance in different model sizes (7B, 13B, 30B) and different application scenarios (retrieval enhancement, cache assistance) Speedup ratio.
Further experimental analysis found that LLM Accelertator can significantly reduce the required decoding steps, and the acceleration ratio is positively correlated with the reduction ratio of decoding steps.
Fewer decoding steps, on the one hand, means that each decoding step generates more output words, which can improve the computational efficiency of GPU computing; on the other hand, for applications that require multi-card parallelism The 30B model means less multi-card synchronization, resulting in faster speed improvements.
In the ablation experiment, the results of analyzing the hyperparameters of LLM Accelertator on the development set showed that when a single word is matched (that is, the copy mechanism is triggered), 15 to 20 are copied at a time. The speedup ratio can reach the maximum when using words (shown in Figure 4).
In Figure 5, we can see that the number of matching words is 1, which can trigger the copy mechanism more, and as the copy length increases, the output words accepted by each decoding step increase, and the decoding steps decrease. Thus achieving a higher acceleration ratio.
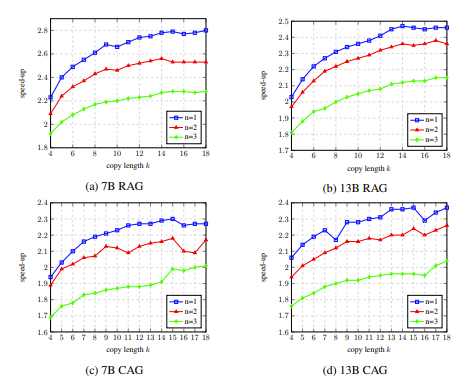
Figure 4: In the ablation experiment, the analysis results of the hyperparameters of LLM Accelertator on the development set
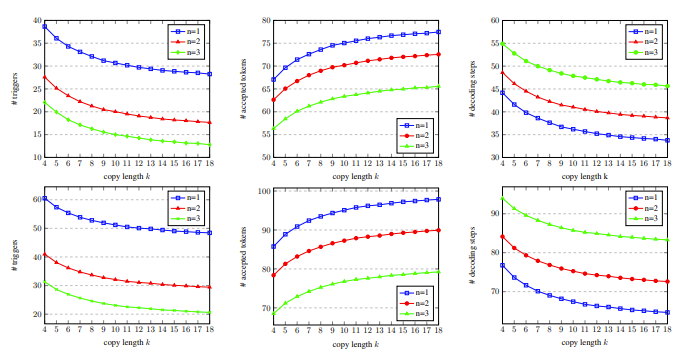
Figure 5: On the development set, with different number of matching words n and copy words Statistical data of several k decoding steps
LLM Accelertator is part of the Microsoft Research Asia Natural Language Computing Group’s series of work on large language model acceleration. In the future, researchers will continue to related issues for more in-depth exploration.
The above is the detailed content of LLM inference is 3 times faster! Microsoft releases LLM Accelerator: using reference text to achieve lossless acceleration. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



