


Although large-scale language models have amazing capabilities, due to their large scale, the costs required for their deployment are often huge. The University of Washington, together with the Google Cloud Computing Artificial Intelligence Research Institute and Google Research, further solved this problem and proposed the Distilling Step-by-Step paradigm to help model training. Compared with LLM, this method is more effective in training small models and applying them to specific tasks, and requires less training data than traditional fine-tuning and distillation. On a benchmark task, their 770M T5 model outperformed the 540B PaLM model. Impressively, their model only used 80% of the available data.

While large language models (LLMs) have demonstrated impressive Few-shot learning capability, but it is difficult to deploy such a large-scale model in real applications. Dedicated infrastructure serving a 175 billion parameter scale LLM requires at least 350GB of GPU memory. What's more, today's state-of-the-art LLM is composed of more than 500 billion parameters, which means it requires more memory and computing resources. Such computing requirements are out of reach for most manufacturers, let alone applications that require low latency.
In order to solve this problem of large models, deployers often use smaller specific models instead. These smaller models are trained using common paradigms - fine-tuning or distillation. Fine-tuning upgrades a small pre-trained model using downstream human annotated data. Distillation trains an equally smaller model using the labels produced by the larger LLM. Unfortunately, these paradigms come at a cost while reducing model size: to achieve comparable performance to LLM, fine-tuning requires expensive human labels, while distillation requires large amounts of unlabeled data that is difficult to obtain.
In a paper titled "Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes", researchers from the University of Washington and Google A new simple mechanism, Distilling step-bystep, is introduced for training smaller models using less training data. This mechanism reduces the amount of training data required to fine-tune and distill the LLM, resulting in a smaller model size.

Paper link: https://arxiv.org/pdf/2305.02301 v1.pdf
#The core of this mechanism is to change the perspective and regard LLM as an agent that can reason, rather than as a source of noise labels. LLM can generate natural language rationales that can be used to explain and support the labels predicted by the model. For example, when asked "A gentleman carries golf equipment, what might he have? (a) clubs, (b) auditorium, (c) meditation center, (d) conference, (e) church" , LLM can answer "(a) club" through chain of thought (CoT) reasoning, and rationalize this label by explaining that "the answer must be something used to play golf." Of the above choices, only clubs are used for golf. We use these justifications as additional, richer information to train smaller models in a multi-task training setting and perform label prediction and justification prediction.
As shown in Figure 1, stepwise distillation can learn task-specific small models with less than 1/500 the number of parameters of LLM. Stepwise distillation also uses far fewer training examples than traditional fine-tuning or distillation.

Experimental results show that among the 4 NLP benchmarks, there are three promising experiments in conclusion.
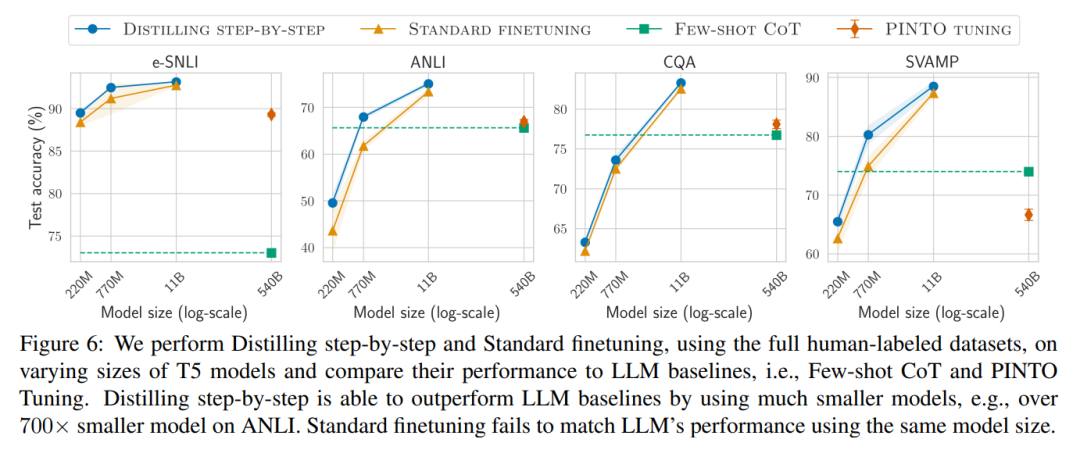
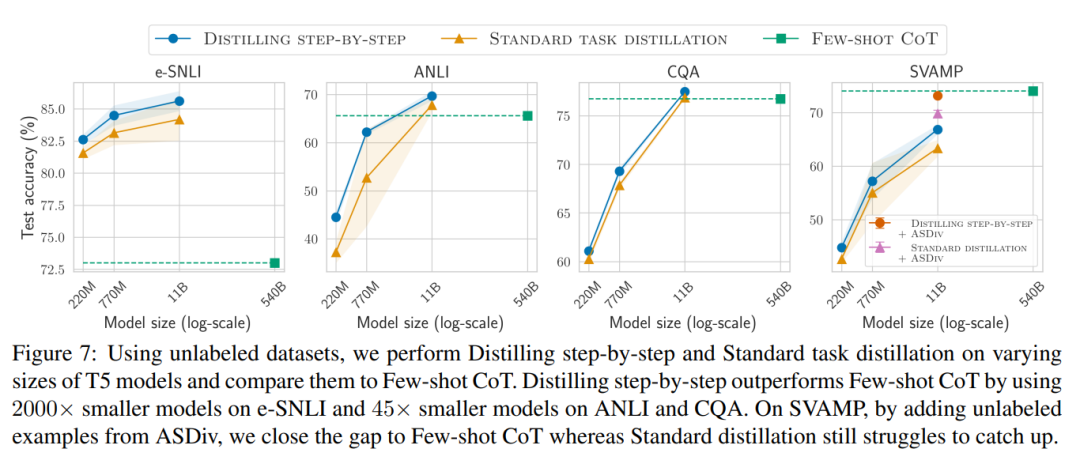
When there is only unlabeled data, the performance of the small model is still better than that of LLM - only using a 11B T5 model exceeds The performance of PaLM of 540B has been improved.
The study further shows that when a smaller model performs worse than LLM, stepwise distillation can more effectively utilize additional unlabeled data than standard distillation methods. Make smaller models comparable to the performance of LLM.
The researchers proposed a new paradigm of stepwise distillation, which uses the reasoning ability of LLM to predict its predictions to train smaller models in a data-efficient manner. Model. The overall framework is shown in Figure 2.
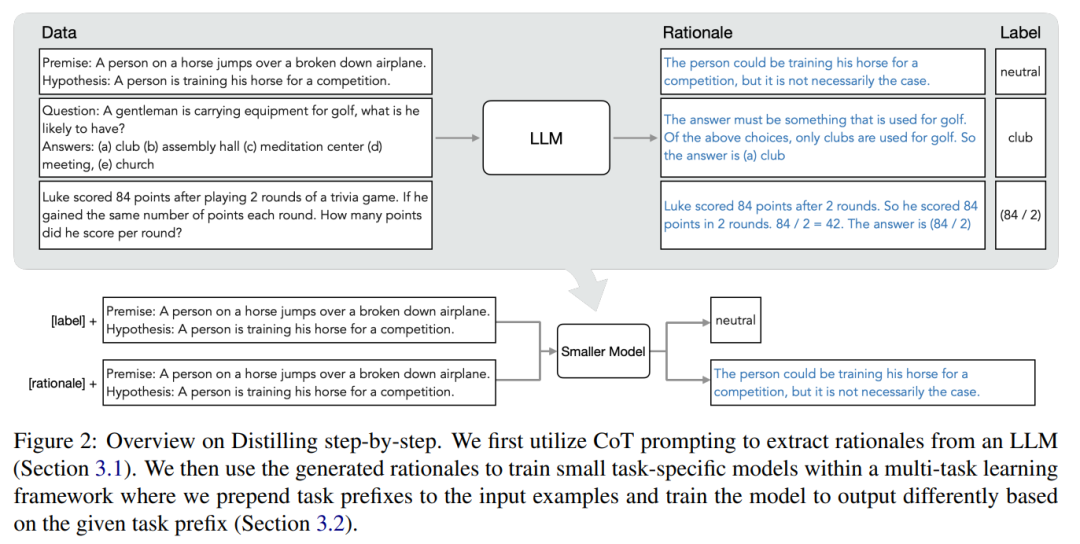
The paradigm has two simple steps: first, given an LLM and an An unlabeled data set prompts LLM to generate an output label and a justification for the label. The rationale is explained in natural language and provides support for the label predicted by the model (see Figure 2). Justification is an emergent behavioral property of current self-supervised LLMs.
Then, in addition to task labels, use these reasons to train smaller downstream models. To put it bluntly, reasons can provide richer and more detailed information to explain why an input is mapped to a specific output label.
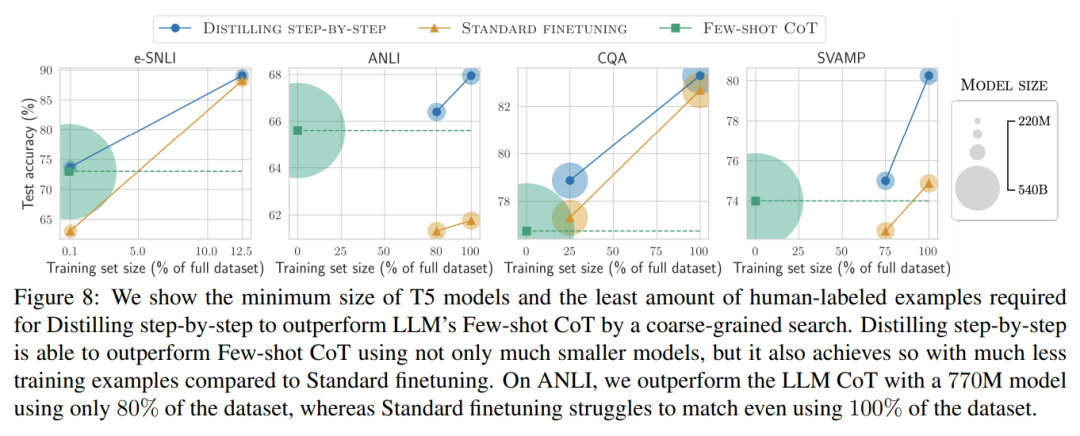
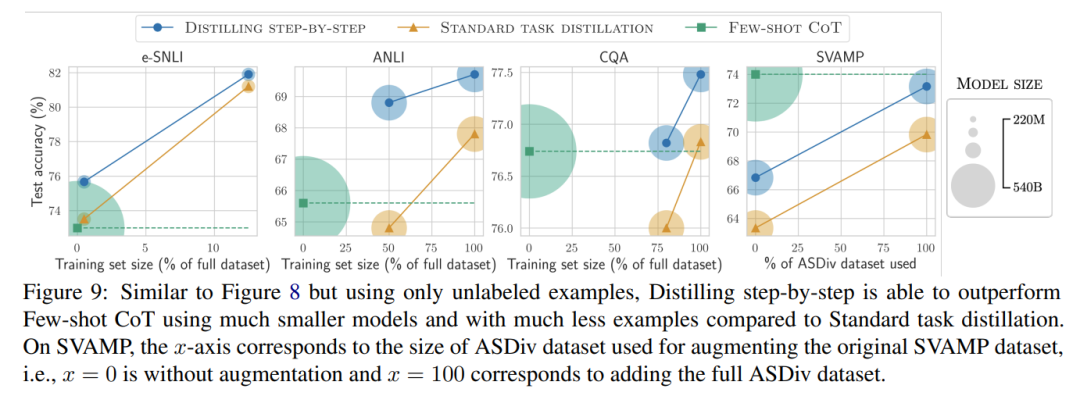
The researchers verified the effectiveness of stepwise distillation in the experiment. First, compared to standard fine-tuning and task distillation methods, stepwise distillation helps achieve better performance with a much smaller number of training examples, significantly improving the data efficiency of learning small task-specific models.
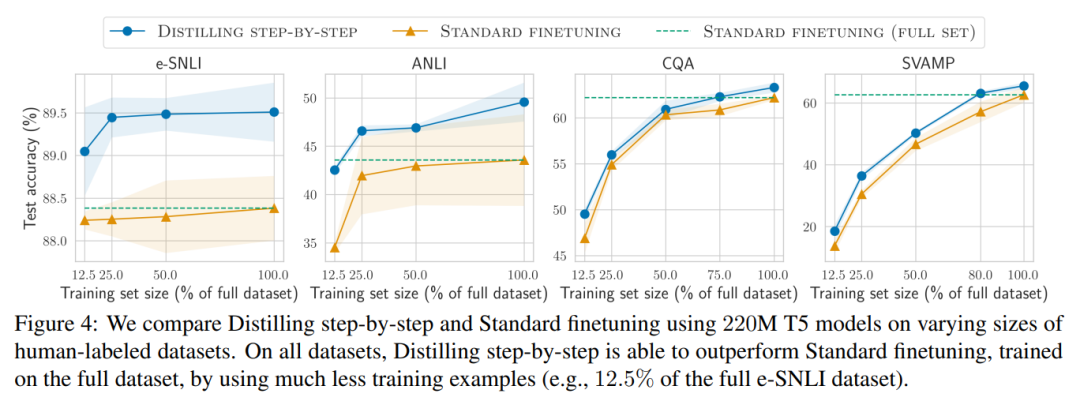
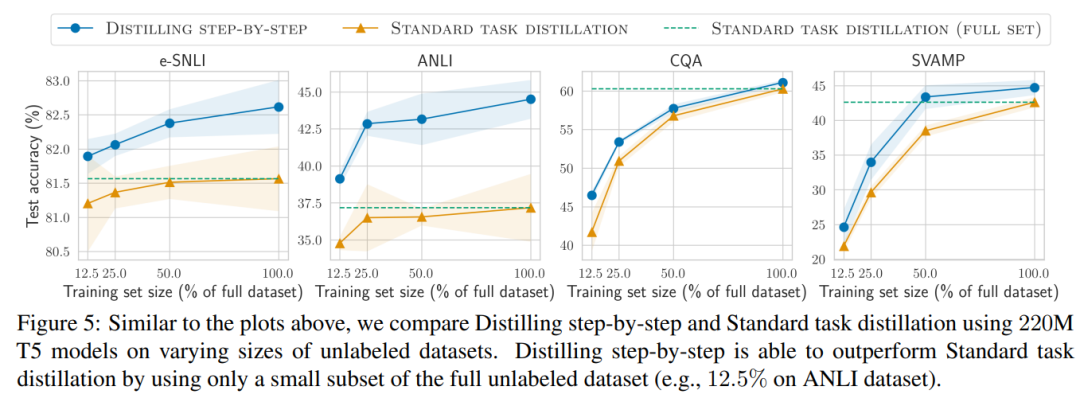
#Secondly, Studies show that the stepwise distillation method surpasses the performance of LLM with smaller model sizes, significantly reducing deployment costs compared to llm.
The above is the detailed content of Distillation can also be Step-by-Step: the new method allows small models to be comparable to large models 2000 times the size. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



