


“We don’t have a moat, and neither does OpenAI.” In a recently leaked document, a Google internal researcher expressed this view.
This researcher believes that although OpenAI and Google appear to be chasing each other on large AI models, the real winner may not emerge from these two because a first The three-party forces are quietly rising.
This power is called "open source". Centering on open source models such as Meta's LLaMA, the entire community is rapidly building models with capabilities similar to those of OpenAI and Google's large models. Moreover, open source models are iterative faster, more customizable, and more private... "When it is free, People will not pay for a restricted model when unrestricted alternatives are of equal quality," the authors write.
This document was originally shared by an anonymous person on a public Discord server. SemiAnalysis, an industry media authorized to reprint, stated that they have verified the authenticity of this document.
This article has been heavily forwarded on social platforms such as Twitter. Among them, Alex Dimakis, a professor at the University of Texas at Austin, expressed the following view:
Of course, not all researchers agree with the views in the article. Some people are skeptical about whether open source models can really have the power and versatility of large models comparable to OpenAI.
However, for academia, the rise of open source power is always a good thing, which means that even if there is no 1,000 yuan With GPUs, researchers still have something to do.
##The following is the original text of the document:
Neither Google nor OpenAI has a moatWe don’t have a moat, and neither does OpenAI.
We have been paying attention to the dynamics and development of OpenAI. Who will cross the next milestone? What's next?
But the uncomfortable truth is that we are not equipped to win this arms race, and neither is OpenAI. While we have been bickering, a third faction has been reaping the benefits.
This faction is the "open source faction". Frankly, they are outpacing us. What we thought of as the "important unsolved problems" have now been solved and are now in people's hands.
Let me give you a few examples:
While our models still maintain a slight edge in quality, the gap is closing at an alarming rate. The open source model is faster, more customizable, more private, and more powerful under the same conditions. They're doing something with $100 and $13 billion parameters that we're having a hard time doing with $10 million and $54 billion parameters. And they can do it in weeks, not months. This has profound implications for us:
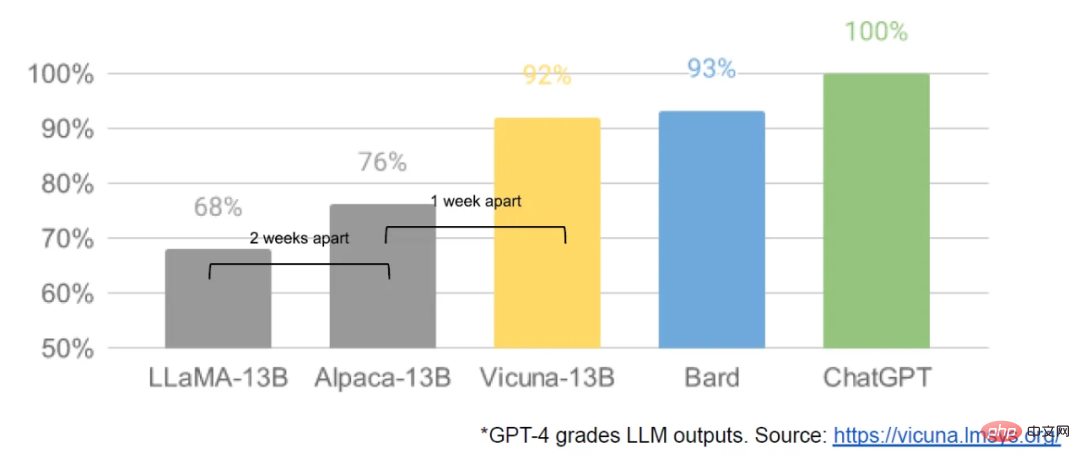
In early March, with Meta’s LLaMA model Leaked to the public, the open source community got its first truly useful base model. This model has no instructions or dialogue adjustments, and no RLHF. Nonetheless, the open source community immediately grasped LLaMA's importance.
What followed was a steady stream of innovation, with major advances appearing only a few days apart (such as running the LLaMA model on Raspberry Pi 4B and fine-tuning the LLaMA instructions on a laptop) , running LLaMA on MacBook, etc.). Just a month later, variants such as instruction fine-tuning, quantization, quality improvement, multi-modality, RLHF, etc. all appeared, many of which built on each other.
Most importantly, they have solved the scaling problem, which means anyone can freely modify and optimize this model. Many new ideas come from ordinary people. The threshold for training and experimentation has moved from major research institutions to one person, an evening, and a powerful laptop.
In many ways, this shouldn’t surprise anyone. The current renaissance in open source LLM comes on the heels of a renaissance in image generation, with many calling this LLM's Stable Diffusion moment.
In both cases, low-cost public participation is achieved through a much cheaper low-rank adaptation (LoRA) fine-tuning mechanism, combined with A major breakthrough in scale. The easy availability of high-quality models helped individuals and institutions around the world incubate a pipeline of ideas and allowed them to iterate on them and quickly outpace large enterprises.
These contributions are crucial in the field of image generation and set Stable Diffusion on a different path from Dall-E. Having an open model enabled product integration, marketplaces, user interfaces and innovations that were not present at Dall-E.
The effect was clear: Stable Diffusion’s cultural impact quickly became dominant compared to OpenAI’s solution. Whether LLM will see similar developments remains to be seen, but the broad structural elements are the same.
Open source projects use innovative methods or technologies that directly solve problems we are still grappling with. Paying attention to open source efforts can help us avoid making the same mistakes. Among them, LoRA is an extremely powerful technology and we should pay more attention to it.
LoRA presents model updates as low-rank factorization, which can reduce the size of the update matrix by thousands of times. In this way, model fine-tuning requires only a small cost and time. Reducing the time for personalized tuning of language models to a few hours on consumer-grade hardware is important, especially for those with a vision of integrating new and diverse knowledge in near real-time. While the technology has a big impact on some of the projects we want to accomplish, it's underutilized within Google.
One reason why LoRA is so effective is this: like other forms of tweaking, it stacks. We can apply improvements such as command fine-tuning to help with tasks such as dialogue and reasoning. While individual fine-tunes are low-rank, while their sum is not, LoRA allows full-rank updates to the model to accumulate over time.
This means that as newer and better data sets and tests become available, the model can be cheaply kept updated without paying the full running cost.
In contrast, training a large model from scratch not only throws away pre-training, but also throws away all previous iterations and improvements. In the open source world, these improvements quickly become prevalent, making a full retraining prohibitively expensive.
We should seriously consider whether each new application or idea really requires a completely new model. If we do have significant architectural improvements that preclude direct reuse of model weights, then we should commit to a more aggressive approach to distillation that preserves previous generation functionality as much as possible.
The cost of LoRA updates is very low (around $100) for the most popular model sizes. This means that almost anyone with an idea can generate and distribute it. At normal speeds where training takes less than a day, the cumulative effect of fine-tuning quickly overcomes the initial size disadvantage. In fact, these models are improving far faster than our largest variants can do in terms of engineer time. And the best models are already largely indistinguishable from ChatGPT. So focusing on maintaining some of the largest models actually puts us at a disadvantage.
Many of these projects save time by training on small, highly curated datasets. This indicates flexibility in data scaling rules. This dataset exists out of ideas from Data Doesn't Do What You Think and is quickly becoming the standard way to train without Google. These datasets are created using synthetic methods (such as filtering out the best reflections from existing models) and scraped from other projects, both of which are not commonly used at Google. Fortunately, these high-quality datasets are open source, so they are freely available.
This recent development has a very direct impact on business strategy. Who would pay for a Google product with usage restrictions when there is a free, high-quality alternative with no usage restrictions? Besides, we shouldn’t expect to catch up. The modern Internet runs on open source because open source has some significant advantages that we can't replicate.
Keeping our technology secrets is always a fragile proposition. Google researchers are regularly traveling to other companies to study, so it can be assumed that they know everything we know. And they will continue to do so as long as this pipeline is open.
But as cutting-edge research in the field of LLMs becomes affordable, maintaining a technological competitive advantage is becoming increasingly difficult. Research institutions around the world are learning from each other to explore solution spaces in a breadth-first approach that is well beyond our own capabilities. We can work hard to hold on to our own secrets, but external innovation dilutes their value, so try to learn from each other.
Most innovation is built on Meta’s leaked model weights. This will inevitably change as truly open models get better and better, but the point is they don't have to wait. The legal protections provided by "personal use" and the impracticality of individual prosecution mean that individuals can use these technologies while they are hot.
Paradoxically, there is only one winner in all of this, and that is Meta, after all the leaked model is theirs. Since most open source innovations are based on their architecture, there is nothing stopping them from being directly integrated into their own products.
As you can see, the value of having an ecosystem cannot be overstated. Google itself already uses this paradigm in open source products like Chrome and Android. By creating a platform for incubating innovative work, Google has solidified its position as a thought leader and direction-setter, gaining the ability to shape ideas bigger than itself.
The tighter we control our models, the more attractive it is to make open alternatives. Both Google and OpenAI tend to have a defensive release model that allows them to tightly control How to use the model. However, this control is unrealistic. Anyone who wants to use LLMs for unapproved purposes can choose from freely available models.
Therefore, Google should establish itself as a leader in the open source community and take the lead through broader dialogue and cooperation rather than ignoring it. This may mean taking some uncomfortable steps, like releasing model weights for small ULM variants. This also necessarily means giving up some control over your own model, but this compromise is inevitable. We cannot hope to both drive innovation and control it.
Given OpenAI’s current closed policy, all this open source discussion feels unfair. If they are not willing to share the technology, why should we share it? But the fact is that we have shared everything with them by continuously poaching senior researchers at OpenAI. Until we stem the tide, secrecy will remain a contentious issue.
Finally, OpenAI doesn’t matter. They make the same mistakes we do with their open source stance, and their ability to maintain their advantage is bound to be questioned. Unless OpenAI changes its stance, open source alternatives can and will eventually eclipse them. At least in this regard, we can take this step.
The above is the detailed content of A leaked internal Google document shows that both Google and OpenAI lack effective protection mechanisms, so the threshold for large models is being continuously lowered by the open source community.. For more information, please follow other related articles on the PHP Chinese website!
 Quick shutdown shortcut key
Quick shutdown shortcut key
 What are the uses of mysql
What are the uses of mysql
 The specific process of connecting to wifi in win7 system
The specific process of connecting to wifi in win7 system
 How to configure jsp virtual space
How to configure jsp virtual space
 Solution to the problem of downloading software and installing it in win11
Solution to the problem of downloading software and installing it in win11
 Why does the printer not print?
Why does the printer not print?
 The meaning of European and American website construction
The meaning of European and American website construction
 How to open ramdisk
How to open ramdisk








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



