


The original content is as follows:
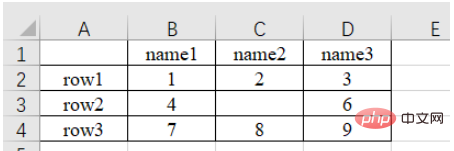
a) Read the nth Sheet (sub-table, you can view or add or delete sub-tables in the lower left) data
import pandas as pd # 每次都需要修改的路径 path = "test.xlsx" # sheet_name默认为0,即读取第一个sheet的数据 sheet = pd.read_excel(path, sheet_name=0) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 """
It can be noticed that there is no content in the upper left corner of the original form, and the read result is "Unnamed : 0", this is because the read_excel function will default the first row of the table as the column index name . In addition, for row index names, numbering starts from the second row by default (because the default first row is the column index name, so the default first row is not data). If not specifically specified, numbering starts from 0 automatically, as follows.
sheet = pd.read_excel(path) # 查看列索引名,返回列表形式 print(sheet.columns.values) # 查看行索引名,默认从第二行开始编号,如果不特意指定,则自动从0开始编号,返回列表形式 print(sheet.index.values) """ ['Unnamed: 0' 'name1' 'name2' 'name3'] [0 1 2] """
b) The column index name can also be customized, as follows:
sheet = pd.read_excel(path, names=['col1', 'col2', 'col3', 'col4']) print(sheet) # 查看列索引名,返回列表形式 print(sheet.columns.values) """ col1 col2 col3 col4 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 ['col1' 'col2' 'col3' 'col4'] """
c) You can also specify the nth column as the row index name , as follows:
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
"""d) Skip the nth row of data when reading
# 跳过第2行的数据(第一行索引为0) sheet = pd.read_excel(path, skiprows=[1]) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row2 4 NaN 6 1 row3 7 8.0 9 """
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('==========================')
print('shape of sheet:', sheet.shape)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
==========================
shape of sheet: (3, 3)
"""1. Directly add square brackets to index
You can use square brackets to add column names The method [col_name] is used to extract the data of a certain column, and then use square brackets plus the index number [index] to index the value of the specific position of this column. Here, the column named name1 is indexed, and then the data located in row 1 of the column (index is 1) is printed: 4, as follows:
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name1'] print(col) # 打印该列第二个数据 print(col[1]) # 4 """ 0 1 1 4 2 7 Name: name1, dtype: int64 4 """
2, iloc method, index by integer number
Use sheet.iloc[ ] index, the square brackets are the integer position numbers of the rows and columns (starting from 0 after excluding the column as the row index and the row as the column index) serial number).
a) sheet.iloc[1, 2]: Extract row 2, column 3 data. The first is the row index, the second is the column index
b) sheet.iloc[0: 2]: Extract the first two rowsdata
c) sheet.iloc[0:2, 0:2]: Extract the first two columns data of the first two rows through sharding
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.iloc[1, 2]
print(data) # 6
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.iloc[0:2]
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice = sheet.iloc[0:2, 0:2]
print(data_slice)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""3. loc method, index by row and column name
Use sheet.loc[ ] index, the square brackets are row and row The name string . The specific usage is the same as iloc , except that the integer index of iloc is replaced by the name index of the row and column. This indexing method is more intuitive to use.
Note: iloc[1: 2] does not contain 2, but loc['row1': 'row2'] does Contains 'row2'.
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.loc['row2', 'name3']
print(data) # 1
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.loc['row1': 'row2']
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice1 = sheet.loc['row1': 'row2', 'name1': 'name2']
print(data_slice1)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""1. Use isnan() or of the numpy library The isnull() method of the pandas library determines whether it is equal to nan .
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name2'] print(np.isnan(col[1])) # True print(pd.isnull(col[1])) # True """ True True """
2. Use str() to convert it to a string and determine whether it is equal to 'nan' .
sheet = pd.read_excel(path)
# 读取列名为 name1 的列数据
col = sheet['name2']
print(col)
# 打印该列第二个数据
if str(col[1]) == 'nan':
print('col[1] is nan')
"""
0 2.0
1 NaN
2 8.0
Name: name2, dtype: float64
col[1] is nan
"""Let’s understand the following code
# 提取name1 == 1 的行
mask = (sheet['name1'] == 1)
x = sheet.loc[mask]
print(x)
"""
name1 name2 name3
row1 1 2.0 3
"""sheet['name2'].replace(2, 100, inplace=True) : Change element 2 of column name2 to element 100, and operate in place.
sheet['name2'].replace(2, 100, inplace=True)
print(sheet)
"""
name1 name2 name3
row1 1 100.0 3
row2 4 NaN 6
row3 7 8.0 9
"""sheet['name2'].replace(np.nan, 100, inplace=True) : Change the empty element (nan) in the name2 column to element 100, operate in place .
import numpy as np
sheet['name2'].replace(np.nan, 100, inplace=True)
print(sheet)
print(type(sheet.loc['row2', 'name2']))
"""
name1 name2 name3
row1 1 2.0 3
row2 4 100.0 6
row3 7 8.0 9
"""To add a column, directly use square brackets [name to add] to add.
sheet['name_add'] = [55, 66, 77]: Add a column named name_add with a value of [55, 66, 77]
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('====================================')
# 添加名为 name_add 的列,值为[55, 66, 77]
sheet['name_add'] = [55, 66, 77]
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
====================================
name1 name2 name3 name_add
row1 1 2.0 3 55
row2 4 NaN 6 66
row3 7 8.0 9 77
"""a) del(sheet['name3']): Use the del method to delete
sheet = pd.read_excel(path, index_col=0)
# 使用 del 方法删除 'name3' 的列
del(sheet['name3'])
print(sheet)
"""
name1 name2
row1 1 2.0
row2 4 NaN
row3 7 8.0
"""b) sheet.drop('row1', axis=0)
Use the drop method to delete the row1 row. If the column is deleted, the corresponding axis=1.
When the inplace parameter is True, the parameter will not be returned and will be deleted directly on the original data.
When the inplace parameter is False (default), the original data will not be modified, but the modified data will be returned. Data
sheet.drop('row1', axis=0, inplace=True)
print(sheet)
"""
name1 name2 name3
row2 4 NaN 6
row3 7 8.0 9
"""c)sheet.drop(labels=['name1', 'name2'], axis=1)
Use label=[ ] parameter to delete Multiple rows or columns
# 删除多列,默认 inplace 参数位 False,即会返回结果
print(sheet.drop(labels=['name1', 'name2'], axis=1))
"""
name3
row1 3
row2 6
row3 9
"""1. Save the data in pandas format as an .xlsx file
names = ['a', 'b', 'c'] scores = [99, 100, 99] result_excel = pd.DataFrame() result_excel["姓名"] = names result_excel["评分"] = scores # 写入excel result_excel.to_excel('test3.xlsx')
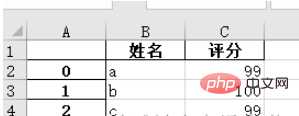
2. Save the modified excel file as an .xlsx file.
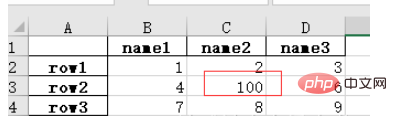
For example, after modifying nan in the original table to 100, save the file:
import numpy as np # 指定第一列为行索引 sheet = pd.read_excel(path, index_col=0) sheet['name2'].replace(np.nan, 100, inplace=True) sheet.to_excel('test2.xlsx')
Open test2.xlsx and the result is as follows:
The above is the detailed content of How to process Excel data with Python's Pandas library?. For more information, please follow other related articles on the PHP Chinese website!
 python development tools
python development tools
 python packaged into executable file
python packaged into executable file
 what python can do
what python can do
 Compare the similarities and differences between two columns of data in excel
Compare the similarities and differences between two columns of data in excel
 excel duplicate item filter color
excel duplicate item filter color
 How to use format in python
How to use format in python
 How to copy an Excel table to make it the same size as the original
How to copy an Excel table to make it the same size as the original
 Excel table slash divided into two
Excel table slash divided into two








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



