


Transformer, as an NLP pre-training model architecture, can effectively learn on large-scale unlabeled data. Research has proven that Transformer is the core architecture of NLP tasks since BERT.
Recent work has shown that the state space model (SSM) is a favorable competing architecture for modeling long-range sequences. SSM achieves state-of-the-art results on speech generation and Long Range Arena benchmarks, even outperforming the Transformer architecture. In addition to improving accuracy, the routing layer based on SSM will not exhibit quadratic complexity as the sequence length grows.
In this article, researchers from Cornell University, DeepMind and other institutions proposed Bidirectional Gated SSM (BiGS) for pre-training without attention. It mainly uses SSM routing is combined with an architecture based on multiplicative gating. The study found that SSM by itself performs poorly in pre-training for NLP, but when integrated into a multiplicative gated architecture, downstream accuracy improves.
Experiments show that BiGS is able to match the performance of BERT models when trained on the same data under controlled settings. With additional pretraining on longer instances, the model also maintains linear time when scaling the input sequence to 4096. Analysis shows that multiplicative gating is necessary and fixes some specific problems of SSM models on variable-length text inputs.

##Paper address: https://arxiv.org/pdf/2212.10544.pdf
Method IntroductionSSM connects the continuous input u (t) to the output y (t) through the following differential equation:
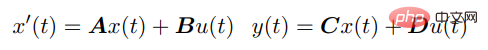
For discrete sequences, the SSM parameters are discretized, and the process can be approximated as:
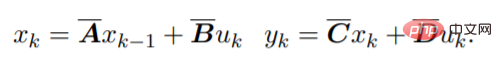
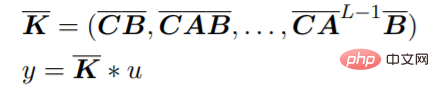
Pre-training model architecture
Can SSM replace attention in pre-training? To answer this question, the study considered two different architectures, the stacked architecture (STACK) and the multiplicative gated architecture (GATED) shown in Figure 1.The stacked architecture with self-attention is equivalent to the BERT /transformer model, and the gated architecture is a bidirectional adaptation of the gated unit, which has also recently been used for unidirectional SSM. 2 sequence blocks (i.e., forward and backward SSM) with multiplicative gating are sandwiched in a feedforward layer. For a fair comparison, the size of the gated architecture is kept comparable to the stacked architecture.
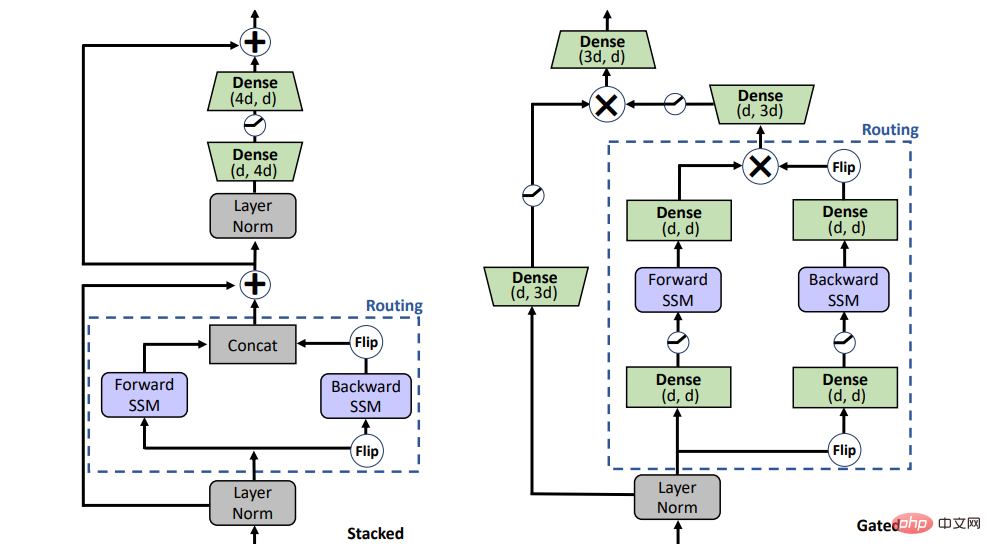
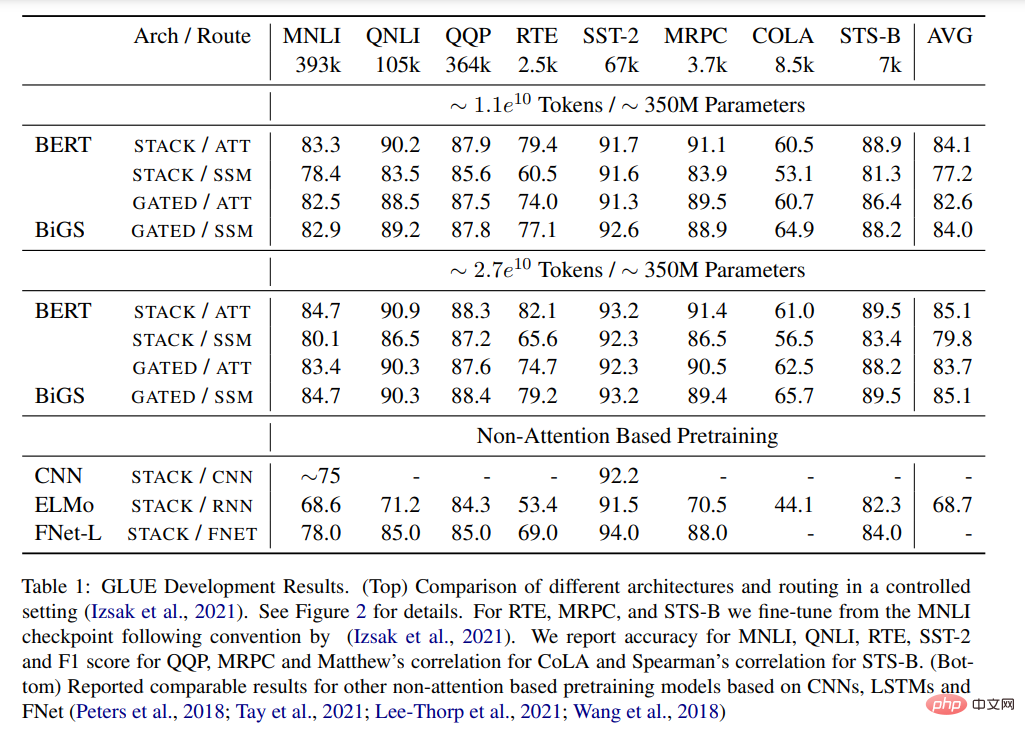
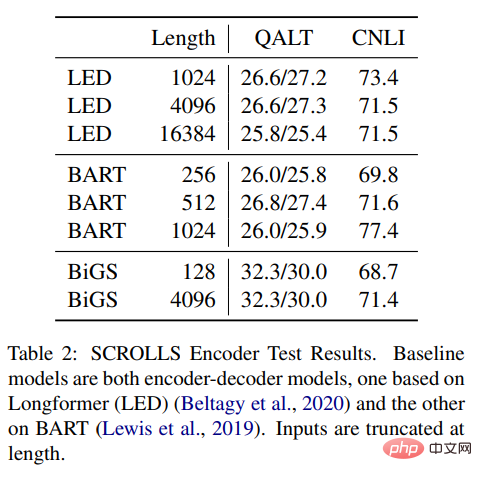
Figure 1: Model variables. STACK is a standard transformer architecture, and GATED is based on gate control units. For the Routing component (dashed line), the study considers both bidirectional SSM (shown in the figure) and standard self-attention. Gated(X) represents element-wise multiplication. Pre-training Table 1 shows the main results of different pre-trained models on the GLUE benchmark. BiGS replicates BERT’s accuracy on token expansion. This result shows that SSM can replicate the accuracy of the pre-trained transformer model under such a computational budget. These results are significantly better than other non-attention-based pre-trained models. To achieve this accuracy, multiplicative gating is necessary. Without gating, the results of stacked SSM are significantly worse. To examine whether this advantage mainly comes from the use of gating, we trained an attention-based model using the GATE architecture; however, the results show that the model is actually less effective than BERT. Table 1: GLUE results. (Top) Comparison of different architectures and routing under control settings. See Figure 2 for details. (Bottom) reported comparable results for other non-attention pretrained models based on CNN, LSTM and FNet. Long-Form Task Table 2 results show that SSM can be combined with Longformer EncoderDecoder (LED) was compared to BART, however, and the results showed that it performed just as well or even better in remote tasks. Compared to the other two methods, SSM has much less pre-training data. Even though SSM does not need to approximate at these lengths, the long form is still important. Table 2: SCROLLS Encoder test results. The baseline models are both encoder-decoder models, one based on Longformer (LED) and the other based on BART. The input length is truncated. #Please see the original paper for more information. Experimental results
The above is the detailed content of Pre-training requires no attention, and scaling to 4096 tokens is no problem, which is comparable to BERT.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



