


In the past ten years, connectionists, with the support of various deep learning models, have taken the lead in symbolism on the artificial intelligence track by leveraging the power of big data and high computing power.
But every time a new deep learning model is released, such as the recently popular ChatGPT, after praising its powerful performance, there is a heated discussion about the research method itself, and the loopholes and defects of the model itself are also discussed. will emerge.
Recently, Dr. Qian Xiaoyi from Beiming Laboratory, as a scientist and entrepreneur who has adhered to the symbolic school for ten years, published a relatively calm and objective evaluation of the ChatGPT model.
Overall, we think ChatGPT is a landmark event.
The pre-training model began to show powerful effects a year ago. This time it has reached a new level and attracted more attention; and after this milestone, many working models related to human natural language will begin. Change, and even a large number of them are replaced by machines.
No technology is achieved overnight. Rather than seeing its shortcomings, a scientific worker should be more sensitive to its potential.
Our team pays special attention to ChatGPT this time, not because of the amazing effects seen by the public, because we can still understand many seemingly amazing effects at a technical level. .
What really impacts our senses is that some of its tasks break through the boundaries between the symbolic genre and the neural genre - logical ability. ChatGPT seems to embody this ability in several tasks such as self-coding and evaluation code.
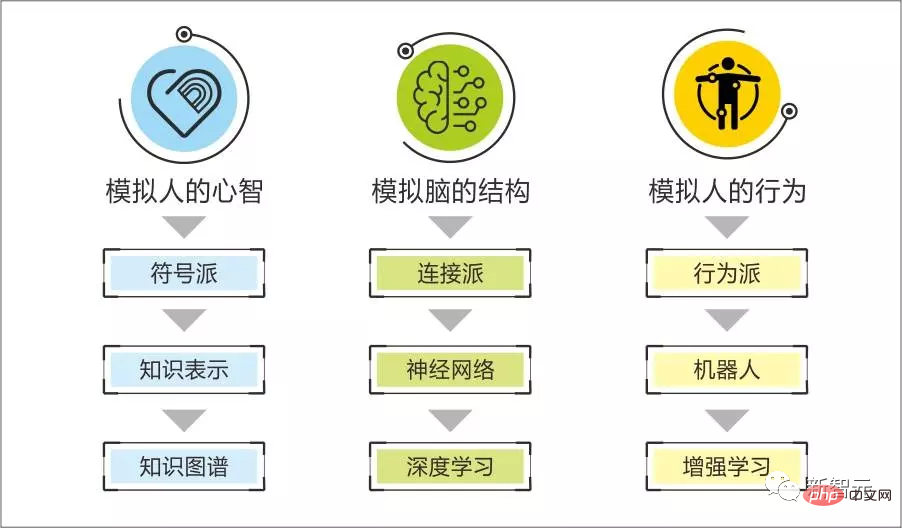
We have always believed that the symbolic genre is good at reproducing the strong logical intelligence of humans, such as how to solve a problem, analyze the cause of a problem, create a tool, etc.;
The essence of connectionism is a statistical algorithm, which is used to find smooth patterns from samples, such as finding the pattern of what to say in the next sentence through enough human conversations; finding the correspondence through descriptive text The rules of image recognition and generation...
We can understand these abilities and become very outstanding through larger models, more high-quality data, and reinforcement learning loop enhancements.
We believe that human beings have the characteristics of both symbolic and neural technical paths, such as all reflective cognitive processes, knowledge learning and application processes, a large number of reflective thinking, behaviors, expression patterns, reflective Motives and emotions are easily explained and reproduced systematically based on symbolic representation.
When you see enough foreign faces, you will have the ability to recognize foreign faces, and you can’t explain why;
You will be able to recognize foreign faces naturally after watching the first TV series The ability to imitate the male protagonist's speech;
After experiencing enough conversations, being able to chat without thinking are all neurological characteristics.
We can compare the strong logical part to growing bones, and the "non-logical law grasping ability" to growing flesh.
It is difficult to "grow flesh" with the ability of symbols to "grow a skeleton", and it is also difficult for nerves to "grow a skeleton" with the ability of "growing flesh".
Just as we accompany the AI building process, the symbol system is good at grasping the specific dimensions of the interlocutor's information, analyzing the intentions behind it, inferring related events, and giving precise suggestions, but it is not good at creating smooth and natural conversations.
We also see that although the dialogue generation model represented by GPT can create smooth dialogue, it uses long-term memory to create coherent companionship, generate reasonable emotional motivations, and complete logical reasoning with a certain depth in the dialogue. It is difficult to implement analytical suggestions in these aspects.
The "bigness" of a large model is not an advantage, but the price paid by statistical algorithms for trying to grasp part of the strong logic-led rules inherent in surface data. It embodies the boundary between symbols and nerves. .
After having a deeper understanding of the principles of ChatGPT, we found that it only regards relatively simple logical operations as a regular training generation, and does not break through the scope of the original statistical algorithm - also That is, the system consumption will still increase geometrically as the depth of logical tasks increases.
But why can ChatGPT break through the limits of the original large model?
Let us explain in non-technical language the principles behind how ChatGPT breaks through the limits of other large models.
GPT3 demonstrated an experience that surpassed other large models when it appeared. This is related to self-supervision, that is, self-labeling of data.
Still taking dialogue generation as an example: a large model was trained with massive data to master the rules of 60 rounds of dialogue and the next sentence.
Why do we need so much data? Why can humans imitate the speech of the male protagonist after watching a TV series?

Because humans do not use the previous rounds of dialogue as input to grasp the rules of what to say in the next sentence, but form an understanding of the context during the subjective dialogue process: the personality of the speaker, what kind of current emotions he has, Motivation, what kind of knowledge is associated with it, plus previous rounds of dialogue to grasp the rules of what to say in the next sentence.
We can imagine that if the large model first identifies the contextual elements of the dialogue and then uses it to generate the rules of the next sentence, compared with using the original dialogue, the data requirements to achieve the same effect can be greatly reduced. Therefore, how well self-supervision is done is an important factor affecting the "model efficiency" of large models.
To examine whether a large model service has self-labeled certain types of contextual information during training, you can examine whether dialogue generation is sensitive to such contextual information (whether the generated dialogue reflects this Consideration of contextual information) to judge.
Manually writing the desired output is the second point where it comes into play.
ChatGPT uses manually written output in several types of tasks to fine-tune the large model of GPT3.5 that has learned the general rules of dialogue generation.
This is the spirit of the pre-training model - the dialogue rules of a closed scene may actually reflect more than 99% of the general rules of human dialogue generation, while the scene-specific rules are less than 1%. Therefore, a large model that has been trained to grasp the general rules of human dialogue and an additional small model for closed scenes can be used to achieve the effect, and the samples used to train the specific rules of the scene can be very small.

The next mechanism that comes into play is that ChatGPT integrates reinforcement learning. The whole process is roughly like this:
Starting preparation: a pre-training model (GPT-3.5), a group of well-trained labers, a series of prompts (instructions or questions, collected from the use process of a large number of users and the design of the laber).
Step1: Randomly sample and obtain a large number of prompts, and the data staff (laber) provides standardized responses based on the prompts. Data scientists can input prompts into GPT-3.5 and refer to the output of the model to assist in providing canonical answers.
Data can be collected
Based on this data set, the GPT-3.5 model is fine-tuned through supervised learning. The model obtained after fine-tuning is temporarily called GPT-3.X.
Step2: Randomly sample some prompts (most of them were sampled in step1), and generate K answers (K>=2) through GPT-3.X for each prompt.
Laber sorts the K responses. A large amount of sorted comparison data can form a data set, and a scoring model can be trained based on this data set.
Step3: Use the reinforcement learning strategy PPO to iteratively update GPT-3.X and the scoring model, and finally obtain the strategy model. GPT-3.X initializes the parameters of the policy model, samples some prompts that have not been sampled in step1 and step2, generates output through the policy model, and scores the output by the scoring model.
Update the parameters of the policy model based on the policy gradient generated by the scoring to obtain a more capable policy model.
Let a stronger strategy model participate in step 2, obtain a new data set through laber sorting and annotation, and update it to obtain a more reasonable scoring model.
When the updated scoring model participates in step 3, an updated strategy model will be obtained. Perform step2 and step3 iteratively, and the final policy model is ChatGPT.
If you are not familiar with the above language, here is an easy-to-understand metaphor: This is like asking ChatGPT to learn martial arts. The human response is the master's routine. GPT3.5 is the routine of a martial arts enthusiast. The scoring neural network is an evaluator, telling ChatGPT who performed better in each game.
So ChatGPT can observe the comparison between human masters and GPT3.5 for the first time, improve it a little in the direction of human masters on the basis of GPT3.5, and then let the evolved ChatGPT be used as a martial art Enthusiasts participate in comparisons with human masters, and the scoring neural network tells it again where the gap is, so that it can become better again.
What is the difference between this and traditional neural network?
The traditional neural network directly allows a neural network to imitate a human master, and this new model allows the neural network to grasp the difference between a good martial arts enthusiast and a master, so that it can learn from human beings on the basis of the existing Make subtle adjustments to the master's direction and keep improving.
It can be seen from the above principle that the large model generated in this way uses human labeled samples as the performance limit.
In other words, it only masters the response patterns of human labeled samples to the extreme, but it does not have the ability to create new response patterns; secondly, as a statistical algorithm, the sample quality will affect the accuracy of the model output. Sex, this is the fatal flaw of ChatGPT in the search and consultation scenarios.
The requirements for similar health consultation are rigorous, which is not suitable for this type of model to be completed independently.
The coding capabilities and code evaluation capabilities embodied by ChatGPT come from a large number of codes, code description annotations, and modification records on github. This is still within the reach of statistical algorithms.
A good signal sent by ChatGPT is that we can indeed use more ideas such as "human focus" and "reinforcement learning" to improve "model efficiency".
"Big" is no longer the only indicator linked to model capabilities. For example, InstructGPT with 1.3 billion parameters is better than GPT-3 with 17.5 billion parameters.
Despite this, because the consumption of computing resources by training is only one of the thresholds for large models, followed by high-quality and large-scale data, we believe that the early business landscape is still: the basis for large manufacturers to provide large models Facilities construction, small factories make super applications based on this. The small factories that have become giants will then train their own large models.
We believe that the potential of the combination of symbols and nerves is reflected in two points: training "meat" on "bones" and using "meat" on "bones".
If there are strong logical contexts (bones) under the surface samples, such as in the previous example of dialogue training, the contextual elements are bones, then it will be very expensive to simply train the rules containing bones from the surface samples. This is reflected in the demand for samples and the cost of higher model training, that is, the "bigness" of large models.
If we use a symbolic system to generate context and use it as a sample input for the neural network, it is equivalent to finding patterns in the background conditions of strong logical recognition and training "meat" on the "bones".
If a large model is trained in this way, its output will be sensitive to strong logical conditions.
For example, in the dialogue generation task, we input the current emotions, motivations, associated knowledge, and related events of both parties participating in the dialogue. The dialogue generated by the large model can reflect the response to these contextual information with a certain probability. . This is using "meat" on the "bones" of strong logic.
Previously, we encountered the problem that symbols cannot create smooth conversations in the development of companion-level AI. If the user is unwilling to talk to the AI, all the logic and emotional capabilities behind the AI cannot be displayed, and there is no way to continuously optimize and iterate. Conditions, we solved the smoothness of the dialogue by combining it with the pre-trained model similar to the above.
From the perspective of large models, simply creating AI with large models lacks integrity and three-dimensionality.
"Holisticity" is mainly reflected in whether context-related long-term memory is considered in dialogue generation.
For example, in the chat between the AI and the user the previous day, they talked about the user having a cold, going to the hospital, having various symptoms, and how long they lasted...; the next day the user suddenly expressed, "My sore throat is fine." pain".
In a simple large model, AI will respond to the content in the context, and will express "Why does my throat hurt?", "Did you go to the hospital?"... These expressions will be immediately associated with long-term memory. contradiction, reflecting long-term memory inconsistency.
By combining it with the symbol system, AI can associate from "the user still has a sore throat the next day" to "the user had a cold yesterday" to "the user has been to the hospital", "the user has other symptoms"... Putting this information into context can use the context consistency ability of large models to reflect the consistency of long-term memory.
The "three-dimensional sense" is reflected in whether the AI has obsession.
Whether you will be obsessed with your own emotions, motivations, and ideas like humans. The AI created by a simple large model will randomly remind a person to drink less when socializing, but when combined with the symbol system, it will know that the user's liver is not good in long-term memory, and combined with the common sense that the user's liver is not good and cannot drink, a strong and continuous message will be generated to prevent the user from drinking. It is recommended to follow up whether the user drinks alcohol after socializing, and the user's lack of self-discipline will affect the mood, thus affecting the subsequent conversation. This is a reflection of the three-dimensional sense.
Judging from the implementation mechanism of the pre-training model, it does not break through the ability of statistical algorithms to "grasp sample patterns". It just takes advantage of the carrier of computers to bring this ability to a very high level, even It reflects the illusion that it has certain logical ability and solving ability.
A simple pre-trained model will not possess human creativity, in-depth logical reasoning capabilities, and the ability to solve complex tasks.
So the pre-trained model has a certain degree of versatility due to low-cost migration to specific scenarios, but it does not have the general intelligence of humans that "generalizes the ever-changing intelligent representations of the upper layer through limited underlying intelligence mechanisms."
Secondly, we want to talk about "emergence". In the study of large models, researchers will find that when the model parameter scale and data scale exceed certain critical values, some capability indicators increase rapidly, showing an emergence effect. .
In fact, any system with abstract learning capabilities will show "emergence".
This is related to the nature of abstract operations - "not obsessed with the correctness of individual samples or guesses, but based on the statistical correctness of the overall sample or guess."
So when the sample size is sufficient and the model can support the discovery of detailed patterns in the samples, a certain ability will suddenly be formed.
In the semi-symbolic thinking project, we see that the process of language learning of symbolic AI will also "emerge" like the language acquisition of human children. After listening and reading to a certain extent, listening and reading will no longer Your understanding and ability to speak will improve by leaps and bounds.
In short, it is okay for us to regard emergence as a phenomenon, but we should interpret all system function mutations with unclear mechanisms as emergence, and expect that a simple algorithm can emerge with the overall intelligence of human beings at a certain scale. This is not a rigorous scientific attitude.
The concept of artificial intelligence emerged almost with the emergence of computers. At that time, it was a simple idea, transplanting human intelligence into computers. This is the concept of artificial intelligence. Starting point, the earliest concept of artificial intelligence refers to "general artificial intelligence".
The human intelligence model is general intelligence, and transplanting this intelligence model to a computer is general artificial intelligence.
Since then, many schools have appeared that try to reproduce the mechanism of human intelligence, but none of these schools have created outstanding results. As a result, Rich Sutton, an outstanding scientist at Deepmind and the founder of reinforcement learning, strongly expressed a point of view:
The biggest lesson that can be learned from the past 70 years of artificial intelligence research is that in order to seek to achieve results in the short term, researchers prefer to use human experience and knowledge of the field (imitate human mechanisms), In the long run, utilizing scalable general computing methods is ultimately what will be effective.
The outstanding achievements of today's large model prove the correctness of his proposition of "algorithmism", but it does not mean that the path of creating intelligent agents by "imitating creation and creating humans" is necessarily wrong.
So why did the previous schools of imitating human beings suffer setbacks one after another? This is related to the integrity of the core of human intelligence.
Simply put, the subsystems formed by human language, cognition, emotional decision-making, and learning abilities support each other in the realization of most tasks, and no subsystem can run independently.
As a highly integrated system, an upper-level appearance comes from the cooperation of many underlying mechanisms. As long as one is defective, it will affect the appearance of this surface effect.
Just like the human body, it is also a highly complex system. There may be slight differences between a healthy person and a sick person, but this subtle pathological difference inhibits a person's functions in all dimensions.
Similarly, for general artificial intelligence, the effect of the first 99 steps may be very limited. When we complete the last piece of the puzzle, the functions of the first 99 steps will become apparent.
Previous schools have seen part of the overall human intelligence from their own perspective, and have also achieved certain results in imitating humans, but this is only a fraction compared to the energy that the overall system can release.
Every local intelligence of human beings has been or is being far surpassed by computers, but even when all local intelligences are surpassed by computers, we can still assert that only Human beings can create civilization, computers are just tools.
Why?
Because behind the creation of civilization is the process of various human intelligent activities, which means that human civilization comes from "process intelligence". This is a direction that is currently severely neglected.
"Cognitive process" is not a task, it is the organization of many tasks in a process.
For example, if AI wants to cure the symptoms of patients, it is a "goal solving" task.
First of all, we need to switch to attribution solving. This is a cognitive task. After finding the possible causes, it becomes the task of "solving specific events" to determine whether a possible disease has occurred. This task will continue again. Decompose and transfer to other tasks. If there is a lack of knowledge in the process, it will become a task of "knowledge solving".
You can obtain existing knowledge through inquiry, search, and reading, or you can use "statistical cognition"; after statistical cognition discovers correlations, you can further gain insight into the causal chain behind it to achieve better intervention. This step often turns to the solution of knowledge due to lack of knowledge. In order to verify the conjecture, it is necessary to design experiments to solve the occurrence of specific events...
After having the causal chain, you can try to achieve the goal again and carry out the causal chain. Intervention turns the original goal into creating, terminating, preventing, and maintaining events in the causal chain. This is back to a process of "goal solving"...

From this perspective, technologies like ChatGPT are used to implement tasks, and the partial symbolic general artificial intelligence framework organizes these local task capabilities to support the process of human-like intelligent activities.
General artificial intelligence is the ontology of "human". It can use internalized abilities and externalized tools to complete tasks, and organize these tasks to support the process of intelligent activities.
Human beings have a strong herding effect, and a school in a period of high productivity will attract the vast majority of researchers.
It is rare to independently reflect on the natural capability boundaries of a technical path, and to independently look for research directions of greater value at the macro level.
We can imagine that if we can reproduce the overall intelligence of human beings on computers, so that machines can support the process of independently exploring cognition, creating tools, solving problems and achieving goals, with the carrier advantage of computers, the overall intelligence of human beings and When process intelligence is amplified as before, only then can we truly unleash the power of artificial intelligence and support human civilization to new heights.

The author Dr. Qian Xiaoyi is a symbolic artificial intelligence scientist, senior engineer, high-level certified talent in Hangzhou, and an early developer of the logic bionic framework. Explorer, creator of the first edition of M language symbology. Founder, CEO and Chairman of Bei Mingxing Mou.
Ph.D. in Applied Economics from Shanghai Jiao Tong University, Master of Financial Engineering from CGU Drucker School of Business, USA, and double bachelor's degree in Mathematics and Finance from Qiu Chengtong Mathematics Elite Class of Zhejiang University Zhu Kezhen College. He has been researching in the field of general AI for 11 years and has led the team in engineering practice for 7 years.
The above is the detailed content of How to treat ChatGPT reasonably: an in-depth discussion by a ten-year symbolism scholar.. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 ChatGPT registration
ChatGPT registration
 Domestic free ChatGPT encyclopedia
Domestic free ChatGPT encyclopedia
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?
 How to install chatgpt on mobile phone
How to install chatgpt on mobile phone
 Can chatgpt be used in China?
Can chatgpt be used in China?
 Android voice playback function implementation method
Android voice playback function implementation method








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



