


Currently, Transformers have become a powerful neural network architecture for sequence modeling. A notable property of pretrained transformers is their ability to adapt to downstream tasks through cue conditioning or contextual learning. After pre-training on large offline datasets, large-scale transformers have been shown to efficiently generalize to downstream tasks in text completion, language understanding, and image generation.
Recent work has shown that transformers can also learn policies from offline data by treating offline reinforcement learning (RL) as a sequential prediction problem. Work by Chen et al. (2021) showed that transformers can learn single-task policies from offline RL data through imitation learning, and subsequent work showed that transformers can extract multi-task policies in both same-domain and cross-domain settings. These works all demonstrate a paradigm for extracting general multi-task policies, i.e. first collecting large-scale and diverse environmental interaction data sets, and then extracting policies from the data through sequential modeling. This method of learning policies from offline RL data through imitation learning is called offline policy distillation (Offline Policy Distillation) or policy distillation (Policy Distillation, PD).
PD offers simplicity and scalability, but one of its major drawbacks is that the generated policies do not progressively improve with additional interactions with the environment. For example, Google's generalist agent Multi-Game Decision Transformers learned a return-conditioned policy that can play many Atari games, while DeepMind's generalist agent Gato learned a solution to diverse problems through contextual task reasoning. Strategies for tasks in the environment. Unfortunately, neither agent can improve the policy in context through trial and error. Therefore, the PD method learns policies rather than reinforcement learning algorithms.
In a recent DeepMind paper, researchers hypothesized that the reason PD failed to improve through trial and error was that the data used for training could not show learning progress. Current methods either learn a policy from data that does not contain learning (e.g. fixed expert policy via distillation) or learn a policy from data that does contain learning (e.g. the replay buffer of an RL agent), but the context size of the latter (too Small) Failure to capture policy improvements.

##Paper address: https://arxiv.org/pdf/2210.14215.pdf
The researchers’ main observation is that the sequential nature of learning in the training of RL algorithms allows, in principle, to model reinforcement learning itself as a causal sequence prediction problem. Specifically, if the context of a transformer is long enough to include the policy improvements brought about by learning updates, then it should not only be able to represent a fixed policy, but also be able to represent a policy improvement algorithm by focusing on the states, actions, and rewards of previous episodes. son. This opens up the possibility that any RL algorithm can be distilled into sufficiently powerful sequence models such as transformers through imitation learning, and these models can be converted into contextual RL algorithms.
The researchers proposed Algorithm Distillation (AD), which is an improved operator for learning contextual strategies by optimizing the causal sequence prediction loss in the RL algorithm learning history. Methods. As shown in Figure 1 below, AD consists of two parts. A large multi-task dataset is first generated by saving the training history of an RL algorithm on a large number of individual tasks, and then the transformer model causally models actions by using the previous learning history as its context. Because the policy continues to improve during the training of the source RL algorithm, AD has to learn improved operators in order to accurately model the actions at any given point in the training history. Crucially, the transformer context must be large enough (i.e., across-episodic) to capture improvements in the training data.
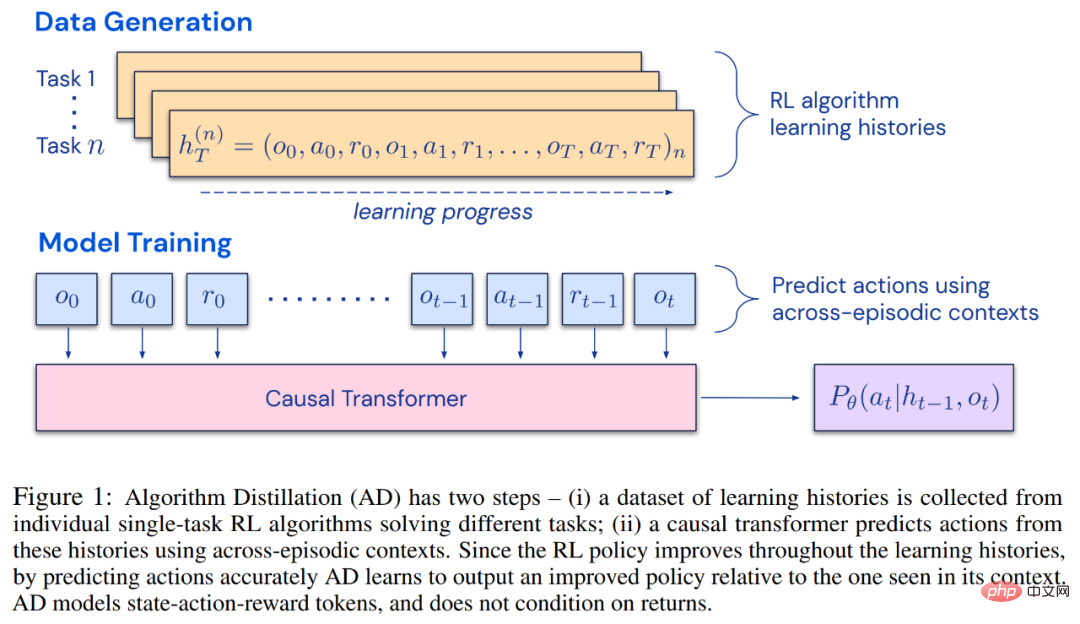
The researchers stated that by using a causal transformer with a large enough context to imitate the gradient-based RL algorithm, AD can fully strengthen new tasks in the context. study. We evaluated AD in a number of partially observable environments requiring exploration, including pixel-based Watermaze from DMLab, and showed that AD is capable of contextual exploration, temporal confidence assignment, and generalization. Additionally, the algorithm learned by AD is more efficient than the algorithm that generated the transformer training source data.
Finally, it is worth noting that AD is the first method to demonstrate contextual reinforcement learning by sequentially modeling offline data with imitation loss.
During its lifetime, a reinforcement learning agent needs to perform well at performing complex actions. For an intelligent agent, regardless of its environment, internal structure and execution, it can be regarded as completed on the basis of past experience. It can be expressed in the following form:
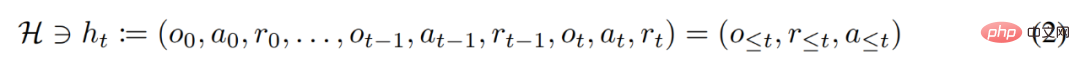
The researcher also regarded the "long history-conditioned" strategy as an algorithm and concluded:

where Δ(A) represents the probability distribution space on action space A. Equation (3) shows that the algorithm can be unfolded in the environment to generate sequences of observations, rewards, and actions. For the sake of simplicity, this study represents the algorithm as P and the environment (i.e. task) as  . The learning history is represented by the algorithm
. The learning history is represented by the algorithm  , so that for any given task
, so that for any given task  Generated. You can get
Generated. You can get
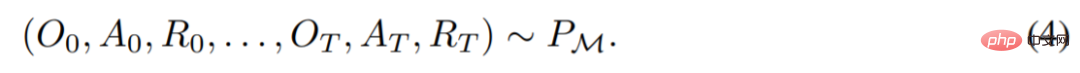
The researcher uses uppercase Latin letters to represent random variables, such as O, A, R and their corresponding lowercase forms o, α, r . By viewing algorithms as long-term history-conditioned policies, they hypothesized that any algorithm that generates a learning history can be converted into a neural network by performing behavioral cloning of actions. Next, the study proposes an approach that provides agents with lifetime learning of sequence models with behavioral clones to map long-term history to action distributions.
In practice, this research implements algorithm distillation (AD) as a two-step process. First, a learning history dataset is collected by running individual gradient-based RL algorithms on many different tasks. Next, a sequence model with multi-episode context is trained to predict actions in history. The specific algorithm is as follows:

The experiment requires that the environment used supports many tasks that cannot be obtained from Inferences are easily made from observations, and episodes are short enough to efficiently train cross-episode causal transformers. The main aim of this work was to investigate the extent to which AD reinforcement is learned in context relative to previous work. The experiment compared AD, ED (Expert Distillation), RL^2, etc.
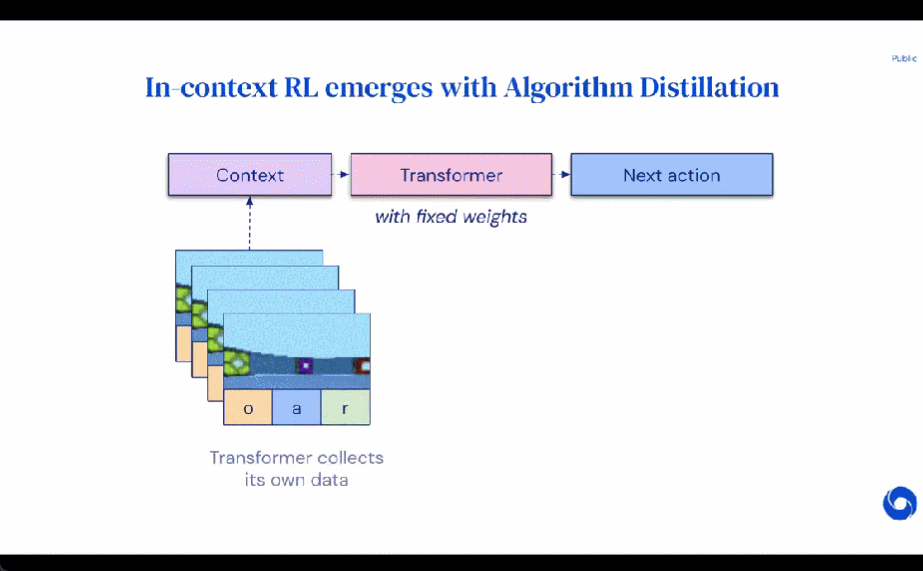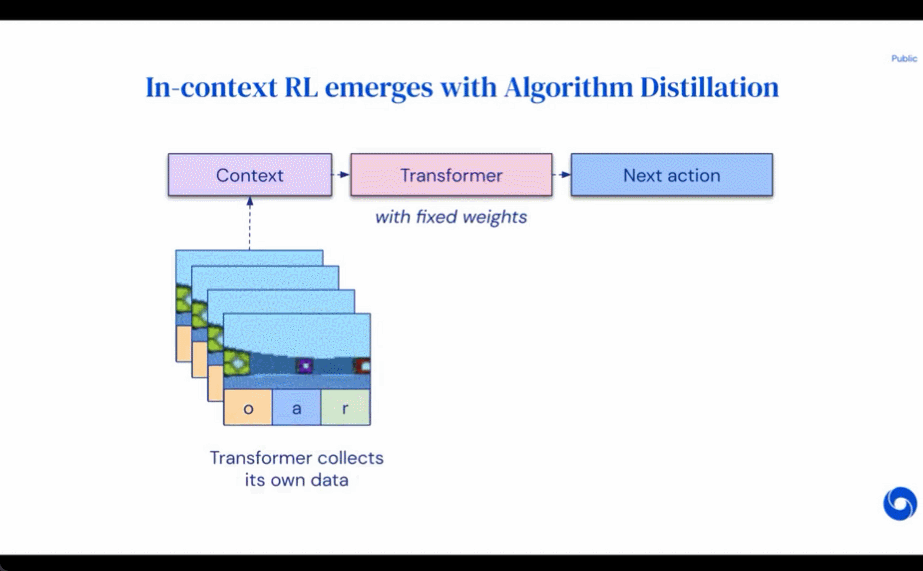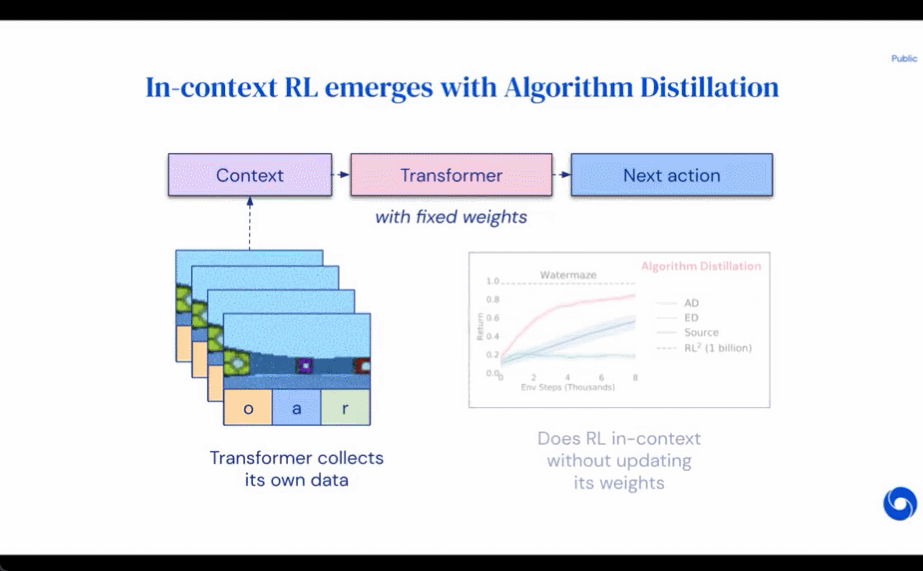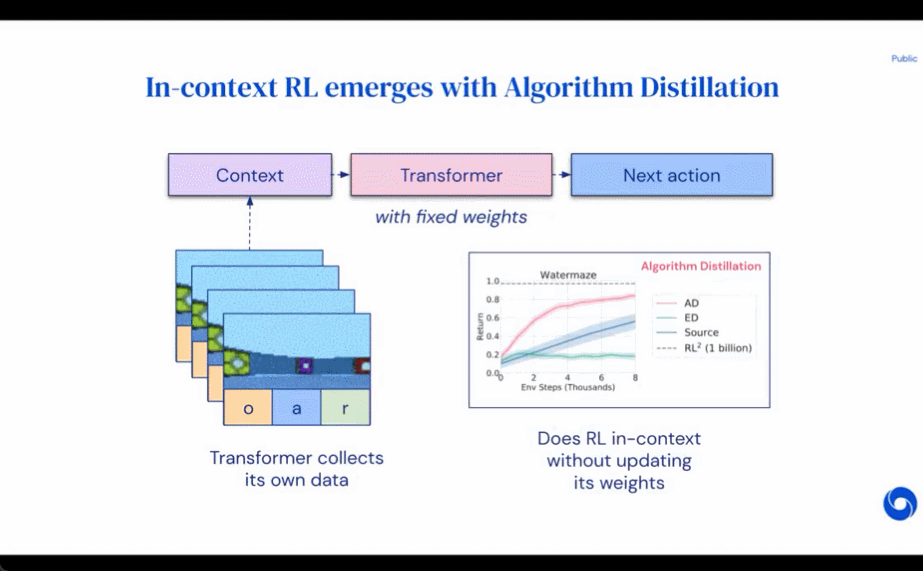
The results of evaluating AD, ED, and RL^2 are shown in Figure 3. The study found that both AD and RL^2 can learn contextually on tasks sampled from a training distribution, while ED cannot, although ED does do better than random guessing when evaluated within a distribution.
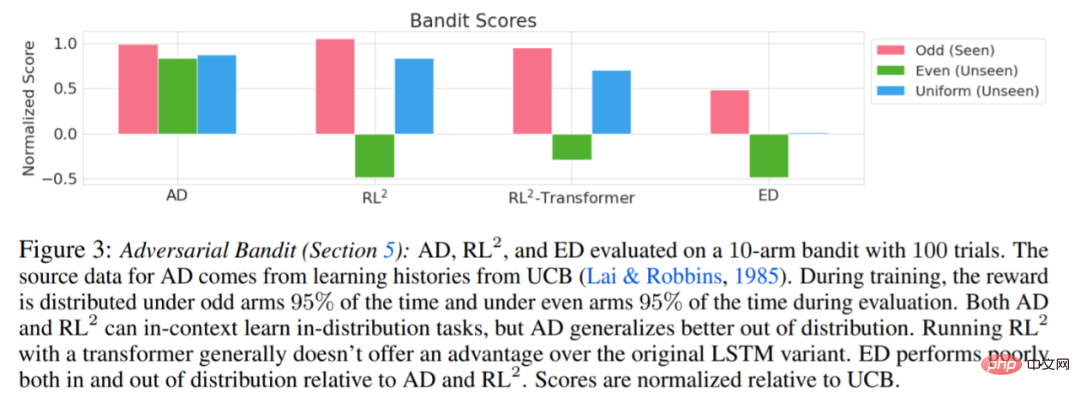
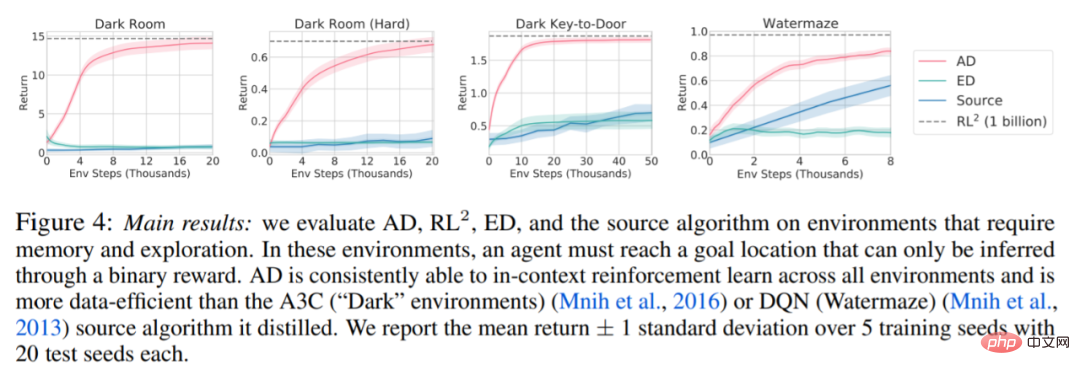
Regarding Figure 4 below, the researcher answered a series of questions. Does AD exhibit contextual reinforcement learning? The results show that AD contextual reinforcement learning can learn in all environments, in contrast, ED cannot explore and learn in context in most situations.
Can AD learn from pixel-based observations? The results show that AD maximizes episodic regression via contextual RL, while ED fails to learn.
AD Is it possible to learn an RL algorithm that is more efficient than the algorithm that generated the source data? The results show that the data efficiency of AD is significantly higher than the source algorithms (A3C and DQN).
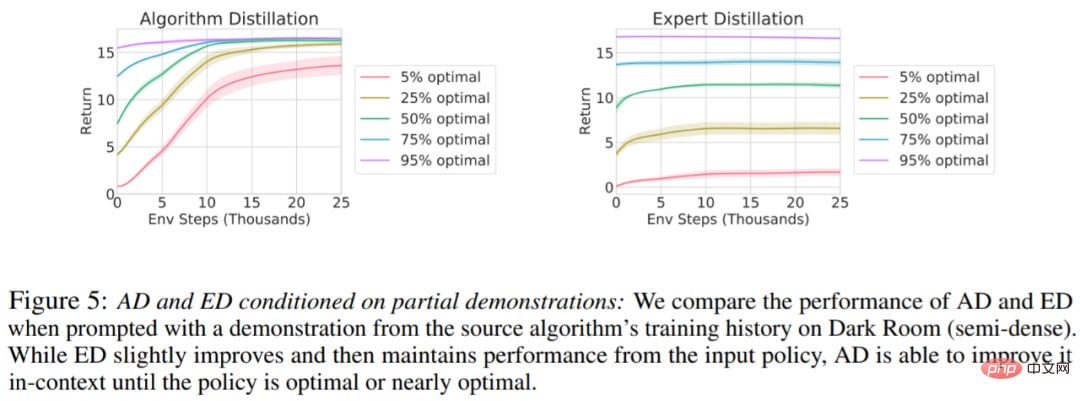
Is it possible to speed up AD by demo? To answer this question, this study retains the sampling strategy at different points along the history of the source algorithm in the test set data, then, uses this strategy data to pre-populate the context of AD and ED, and runs both methods in the context of Dark Room, The results are plotted in Figure 5. While ED maintains the performance of the input policy, AD improves each policy in context until it is close to optimal. Importantly, the more optimized the input strategy is, the faster AD improves it until it reaches optimality.
For more details, please refer to the original paper.
The above is the detailed content of New DeepMind research: transformer can improve itself without human intervention. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



