


Author | Cui Hao
Reviewer| Chonglou
A revolutionary technology upgrade, the release of ChatGPT 4.0 shocked the entire AI industry. Now, not only can computers recognize and answer everyday natural language questions, ChatGPT can also provide more accurate solutions by modeling industry data. This article will give you an in-depth understanding of ChatGPT’s architectural principles and its development prospects. It will also introduce how to use ChatGPT’s API to train industry data. Let us explore this new and promising field together and create a new era of AI.
ChatGPT 4.0 has been officially released! This version of ChatGPT introduces leaps and bounds of innovation. Compared with the previous ChatGPT 3.5, it has a huge improvement in model performance and speed. Before the release of ChatGPT 4.0, many people had paid attention to ChatGPT and realized its importance in the field of natural language processing. However, in 3.5 and previous versions, the limitations of ChatGPT still exist because its training data is mainly concentrated in the general domain In the language model, it is difficult to generate content related to specific industries. However, with the release of ChatGPT 4.0, more and more people have begun to use it to train their own industry data, and it has been widely used in various industries. This has caused more and more people to pay attention to and use ChatGPT. Next, I will introduce to you the architectural principles, development prospects and application of ChatGPT in training industry data.
ChatGPT## The architecture of # is based on deep learning neural network, which is a natural language processing technology. Its principle is to use a pre-trained large-scale language model to generate text, so that the machine can understand and generate natural language. The model principle of ChatGPT is based on the Transformer network, which is trained using unsupervised language modeling technology to predict the probability distribution of the next word to generate continuous text. The parameters used include the number of layers of the network, the number of neurons in each layer, Dropout probability, Batch Size, etc. The scope of learning involves general language models and domain-specific language models. Domain-general models can be used to generate a variety of texts, while domain-specific models can be fine-tuned and optimized for specific tasks.
OpenAI uses massive text data as training data for GPT-3. Specifically, they used more than 45TB of English text data and some other language data, including web text, e-books, encyclopedias, Wikipedia, forums, blogs, etc. They also used some very large data sets such as Common Crawl, WebText, BooksCorpus, etc. These data sets contain trillions of words and billions of different sentences, providing very rich information for model training.
Since you have to learn so much content, the computing power used is also considerable. ChatGPT consumes relatively high computing power and requires a large amount of GPU resources for training. According to a technical report by OpenAI in 2020, GPT-3 consumed approximately 17.5 billion parameters and 28,500 TPU v3 processors during training.
From the introduction above#, we know that ChatGPT has powerful capabilities , and also requires a huge calculation and resource consumption, trainingthis Large language models require high costs. But the AIGC tools produced at such a high cost#exist Itslimitations,It does not have knowledge about certain professional fields Get involved. For example, when it comes to professional fields like medicine or law, ChatGPT is unable to generate accurate answers. This is because the learning data of ChatGPT comes from the general corpus on the Internet, and these data do not include professional terms and knowledge in certain specific fields. Therefore, if you want ChatGPT to have better performance in certain professional fields, you need to use professional corpora in that field for training. Knowledge"Teach" ChatGPT to learn. However, ChatGPT did not disappoint us. If you apply ChatGPT to a certain industry, you need to extract the professional data of the industry first and perform preprocessing. Specifically, a series of processes such as cleaning, deduplication, segmentation, and labeling of data need to be performed. Afterwards, the processed data is formatted and converted into a data format that meets the input requirements of the ChatGPT model. Then, you can use the API interface of ChatGPT to input the processed data into the model for training. The time and cost of training depend on the amount of data and computing power. After training is completed, the model can be applied to actual scenarios to answer user questions.
Use ChatGPT to train professional domain knowledge! In fact, it is not difficult to establish a knowledge base in a professional field.
Specific operationsIt is to convert industry data into question and answer format , and then Model the question and answer format through Natural Language Processing (NLP) technology to answer the question question. Using OpenAI’s GPT-3 API (as GPT3 Example)You can create a question and answer model that can generate answers based on the questions you provide by simply providing some examples. The general steps to create a question and answer model using the GPT-3 API are as follows:

, which# provides different types of API subscription plans, including Developer, Production, and Custom plans. Each plan offers different features and API access, and comes at different prices. Because is not the focus of this article, I will not elaborate here. Create a data setFrom the above steps, 2-step conversion into Q&A format was a challenge for us.
Assume that has
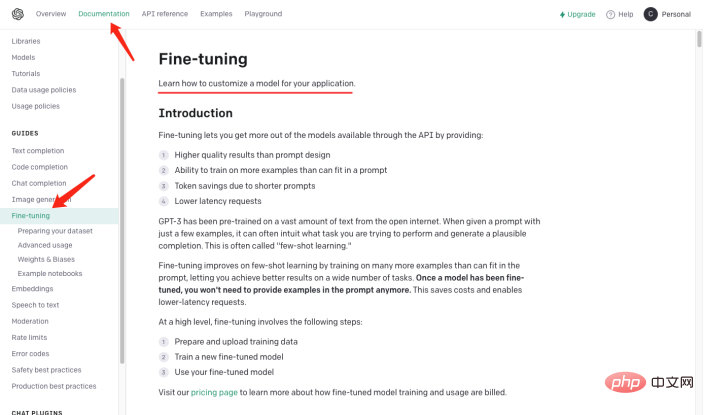
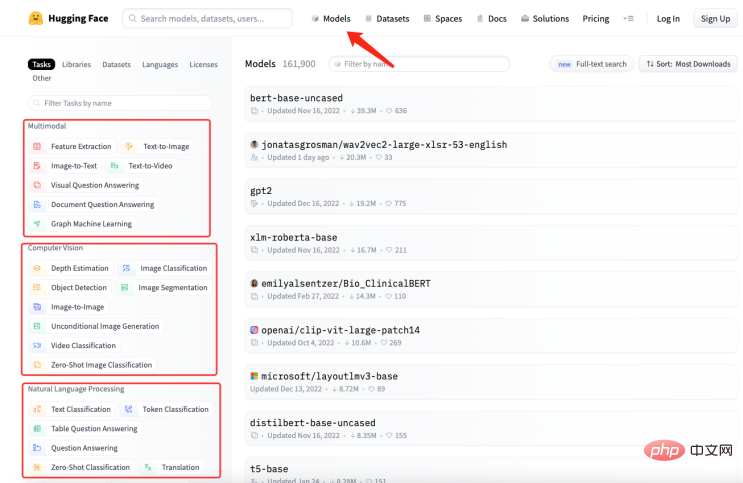
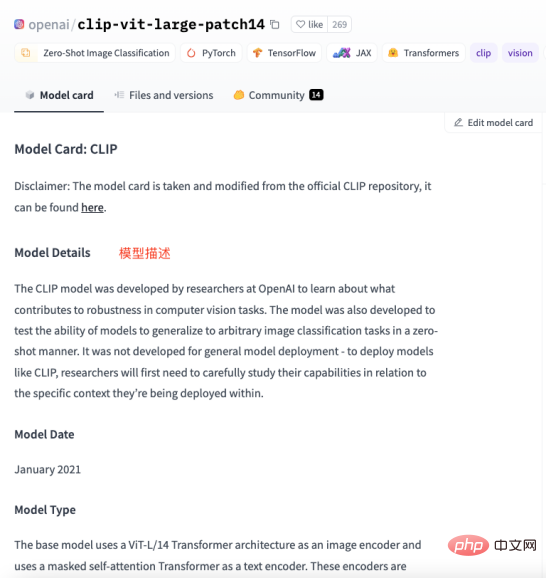
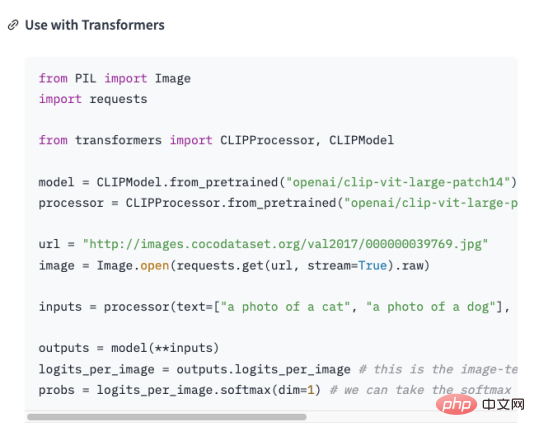
The domain knowledge about the history of artificial intelligence needs to be taught to GPT, And transform this knowledge into models that answer relevant questions. Then it must be converted into the following form: ##Of course it is not enough to organize it into a question and answer format. It needs to be in a format that GPT can understand, as shown below : In fact, "\n\n"## is added after the question #, and added "\n## after the answer #”. A model that quickly generates question and answer format solves the problem of question and answer format, A new question comes again, how do we organize industry knowledge into a question and answer format? In most cases, we crawl a lot of domain knowledge from the Internet, or find a lot of domain documents. No matter what the case is, inputting documents is the most convenient for us. . However, it is obviously unrealistic to use regular expressions or manual methods to process a large amount of text into a question and answer format. Therefore, it is necessary to introduce a method called Automatic summarization technology can extract key information from an article and generate a short summary. There are two types of automatic summarization: extractive automatic summary and generative automatic summary. Extractive automatic summarization extracts the most representative sentences from the original text to generate a summary, while generative automatic summarization extracts important information from the original text through model learning and generates a summary based on this information. In fact, Automatic summary is to generate a question and answer mode from the input text. #After the problem is clarified, the next step is to install the tools. We use NLTK to do things, NLTK It is the abbreviation of Natural Language Toolkit and is a Python library mainly used in the field of natural language processing. It includes various tools and libraries for processing natural language, such as text preprocessing, part-of-speech tagging, named entity recognition, syntax analysis, sentiment analysis, etc. #We only need to hand the text to NLTK, which will perform data preprocessing operations on the text. Including removal of stop words, word segmentation, part-of-speech tagging, etc. After preprocessing, the text summary generation module in NLTK can be used to generate summaries. You can choose different algorithms, such as based on word frequency, based on TF-IDF, etc. While generating the summary, the question template can be combined to generate a question-and-answer summary, making the generated summary more readable and understandable. At the same time, the summary can also be fine-tuned, such as sentences that are not coherent, answers that are inaccurate, etc. can be adjusted. Look at the following code: ##from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline import nltk # Enter text## ##text = """Natural Language Toolkit (NLTK) is a set of Python libraries used to solve human language data processing problems, such as: ##Participle Part-of-speech tagging Syntactic analysis ## Speech recognition Text generation etc. """ sentences = nltk.sent_tokenize(text) ## summary = " ".join(sentences[:2]) # Take the first two sentences as summary print("Summary:", summary) # Use the generated summary to Fine-t##uning, get model #tokenizer = AutoTokenizer.from_pretrained("t5-base ") ##model = AutoModelForSeq2SeqLM.from_pretrained ("t5-base") ##qa = pipeline("question-answering", model=model_name, tokenizer=model_name) context = "What is NLTK used for?" # Questions to be answered ##answer = qa(questinotallow=context, cnotallow= text["input_ids"]) print("Question:", context) print("Answer:", answer["answer"]) ## The output results are as follows: ##Abstract: Natural Language Toolkit (NLTK) is a set of Python libraries used to solve human language data processing problems, such as : - Word segmentation - Part-of-speech tagging Question : NLTKWhat is it used for? Answer:Natural Language Processing Toolkit The above code uses the nltk.sent_tokenize method to extract the summary of the input text, that is, to format the question and answer. Then , calls F# #ine-tuning's AutoModelForSeq2SeqLM.from_pretrained method models it, thenchanges the model named "first-model" to save. Finally, call the trained model to test the results. The above is not only passedNLTK To generate a summary of the question and answer, you also need to use Fine- tuning function. Fine-tuning is based on the pre-trained model and fine-tunes the model through a small amount of labeled data to adapt to Specific tasks. In fact is to use the original model to install your data to form your model. Of course, you can also adjust the internal results of the model. For example, hidden layer settings and parameters, etc. Here we justuseits simplest function, You can learn more about Fine-tuning through the picture below. ##It should be noted that :AutoModelForSeq2SeqLM class, loads the Tokenizer and model from the pre-trained model "t5-base". AutoTokenizer is a class in the Hugging Face Transformers library that can automatically select and Load the appropriate Tokenizer. T The function of the okenizer is to encode the input text into a format that the model can understand for subsequent model input. AutoModelForSeq2SeqLM is also a class in the Hugging Face Transformers library that automatically selects and loads appropriate sequences based on pre-trained models into the sequence model. Here, a sequence-to-sequence model based on the T5 architecture is used for tasks such as summarization or translation. After loading a pretrained model, you can use this model for Fine-tuning or generating task-related output. We explained the modeling code above, involving Fine-# #tunning and Hugging The part about Face may sound confusing. Here is an example to help you understand. SupposeYou want to cook, although You already have the ingredients (industry knowledge), but don’t know how to make it. So you ask your chef friend for advice. You tell him what ingredients you have (industry knowledge) and what dish you want to cook (solved question), your friend gives you ## based on his experience and knowledge (general model) #Provide some suggestions, this process isFine-tuning (Put industry knowledge into a general model for training) . Your friend’s experience and knowledge isPre-trained model,You need to input the industry knowledge and the problem to be solved, and use the pre-trained Model, Of course, you can fine-tune this model, such as the content of seasonings and the heat of cooking. The purpose is to solve the problems of your industry. And Hugging Face is the warehouse of recipes ("t5-base" in the code is a recipe) , which contains many defined recipes (models), such as: fish-flavored shredded pork, Kung Pao chicken, and boiled pork slices. These ready-made recipes can be used to create our recipes based on the ingredients we provide and the dishes we need to cook. We just need to adjust these recipes and then train them, and shape becomes our own recipes. From now on, we can use our own recipes to cook (solve industry problems). How to choose a model that suits you? You can search for the model you need in Hugging Face’s model library. As shown in the figure below, on the official website of Hugging Face, click "Models" to see the classification of models, and you can also use the search box to search for model names. #As shown in the figure below, each model page will provide a description of the model, usage examples, pre-training weight download links and other related information. Here we will walk through the entire industry knowledge process from collection, transformation, training and use to everyone. As shown in the figure below:
##What is the history of artificial intelligence? \n\nArtificial Intelligence originated in the 1950s and is a branch of computer science that aims to study how to enable computers to think and act like humans. \n
# Generate summary
What is the relationship between Fine-tunning and Hugging Face?
##Introduction to the author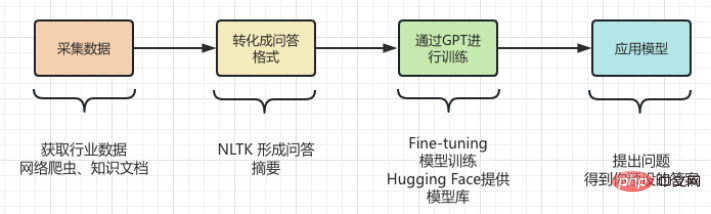
Cui Hao, 51CTO community editor, senior architect, has 18 years of experience in software development and architecture, and 10 years of experience in distributed architecture.
The above is the detailed content of A 20-year IT veteran shares how to use ChatGPT to create domain knowledge. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 ChatGPT registration
ChatGPT registration
 Domestic free ChatGPT encyclopedia
Domestic free ChatGPT encyclopedia
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 How to install chatgpt on mobile phone
How to install chatgpt on mobile phone
 Can chatgpt be used in China?
Can chatgpt be used in China?
 What is the difference between php5 and php7
What is the difference between php5 and php7
 How to change pycharm to Chinese
How to change pycharm to Chinese








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



