


ChatGPT and other generative AI (GAI) technologies fall under the category of Artificial Intelligence Generated Content (AIGC), which involves the creation of digital content such as images, music, and natural language through AI models. AIGC's goal is to make the content creation process more efficient and accessible, allowing for the production of high-quality content at a faster rate. AIGC is achieved by extracting and understanding intent information from instructions provided by humans, and generating content based on their knowledge and intent information.
In recent years, large-scale models have become increasingly important in AIGC as they provide better intent extraction, thus improving the generation results. As data and model size grow, the distributions that models can learn become more comprehensive and closer to reality, resulting in more realistic and high-quality content.
This article provides a comprehensive review of the history, basic components, and recent progress of AIGC, from single-modal interaction to multi-modal interaction. From a single-modal perspective, the text and image generation tasks and related models are introduced. From a multimodal perspective, the cross-applications between the above modalities are introduced. Finally, the open issues and future challenges of AIGC are discussed.

##Paper address: https://arxiv.org/abs/2303.04226
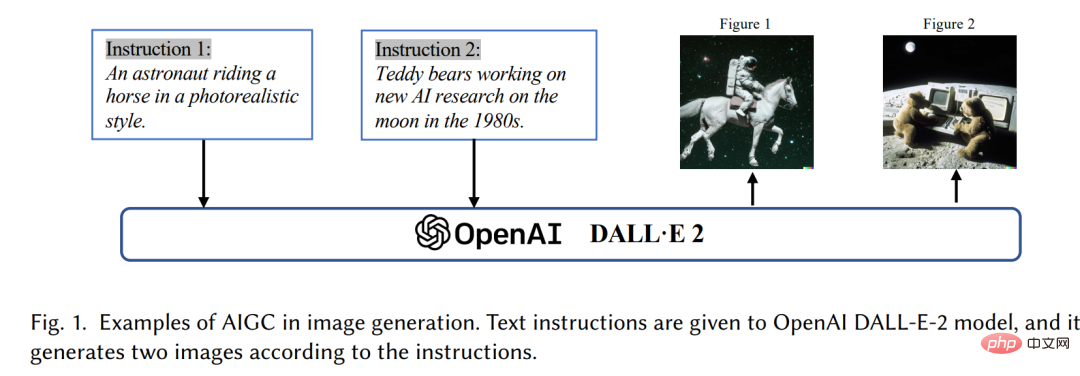
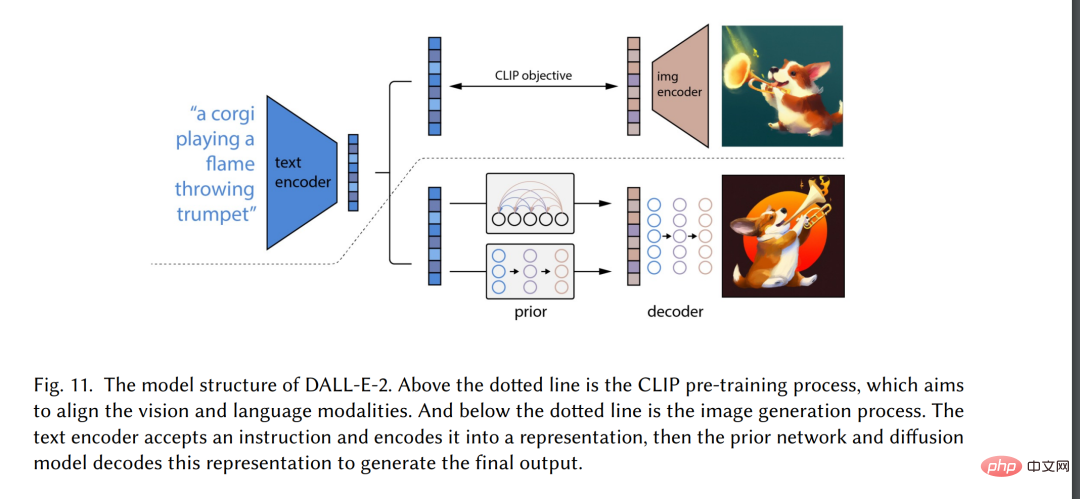
IntroductionIn recent years, Artificial Intelligence Generated Content (AIGC) has received widespread attention outside the computer science community, and the whole society has begun to pay attention to large technology companies[3 ] built various content generation products, such as ChatGPT[4] and DALL-E2[5]. AIGC refers to content generated using advanced generative AI (GAI) technology, rather than content created by human authors. AIGC can automatically create large amounts of content in a short period of time. For example, ChatGPT is a language model developed by OpenAI for building conversational artificial intelligence systems that can effectively understand and respond to human language input in a meaningful way. In addition, DALL-E-2 is another state-of-the-art GAI model, also developed by OpenAI, which is able to create unique high-quality images from text descriptions in minutes, as shown in Figure 1 "An astronaut with a Horse riding in realistic style". With the outstanding achievements of AIGC, many people believe that this will be a new era of artificial intelligence and will have a significant impact on the entire world.
Technically speaking, AIGC refers to given human instructions that can help teach and guide the model to complete Task, use GAI algorithm to generate content that satisfies instructions. The generation process usually includes two steps: extracting intent information from human instructions and generating content based on the extracted intent. However, as shown in previous studies [6,7], the paradigm of the GAI model containing the above two steps is not entirely novel. Compared with previous work, the core progress of recent AIGC is to train more complex generative models on larger data sets, use larger base model architectures, and have access to a wide range of computing resources. For example, the main framework of GPT-3 remains the same as GPT-2, but the pre-training data size increases from WebText [8] (38GB) to CommonCrawl [9] (570GB after filtering), and the base model size increases from 1.5B to 175B. Therefore, GPT-3 has better generalization ability than GPT-2 on tasks such as human intention extraction.
In addition to the benefits of increased data volumes and computing power, researchers are also exploring ways to integrate new technologies with GAI algorithms. For example, ChatGPT utilizes reinforcement learning from human feedback (RLHF) [10-12] to determine the most appropriate response to a given instruction, thereby improving the model's reliability and accuracy over time. This approach enables ChatGPT to better understand human preferences in long conversations. At the same time, in the field of computer vision, stable diffusion was proposed by Stability [13]. AI has also achieved great success in image generation in 2022. Unlike previous methods, generative diffusion models can help generate high-resolution images by controlling the trade-off between exploration and exploitation, thereby harmoniously combining the diversity of generated images and their similarity to the training data.
Combining these advances, the model has made significant progress on AIGC tasks and has been applied to various industries, including art [14], advertising [15], education [16], etc. In the near future, AIGC will continue to become an important research area in machine learning. Therefore, it is crucial to conduct an extensive survey of past research and identify open questions in the field. The core technologies and applications in the field of AIGC are reviewed.
This is the first comprehensive review of AIGC, summarizing GAI from both technical and application aspects. Previous research has focused on GAI from different perspectives, including natural language generation [17], image generation [18], and generation in multi-modal machine learning [7, 19]. However, previous work only focused on specific parts of AIGC. This article first reviews the basic techniques commonly used in AIGC. A comprehensive summary of the advanced GAI algorithm is further provided, including single-peak generation and multi-peak generation, as shown in Figure 2. Additionally, the applications and potential challenges of AIGC are discussed. Finally, existing problems and future research directions in this field are pointed out. In summary, the main contributions of this paper are as follows:
The remainder of the survey is organized as follows. Section 2 mainly reviews the history of AIGC from two aspects: visual modality and language modality. Section 3 introduces the basic components currently widely used in GAI model training. Section 4 summarizes the recent progress in GAI models, in which Section 4.1 reviews the progress from a single-modal perspective and Section 4.2 reviews the progress from a multi-modal generation perspective. In multimodal generation, visual language models, text audio models, text graph models, and text code models are introduced. Sections 5 and 6 introduce the application of the GAI model in AIGC and some important research related to this field. Sections 7 and 8 reveal the risks, existing problems and future development directions of AIGC technology. Finally, we summarize our study in 9.
Generative models have a long history in the field of artificial intelligence, dating back to the 1950s, with the Hidden Markov Model (HMM) )[20] and the development of Gaussian mixture models (GMMs)[21]. These models generate sequential data such as speech and time series. However, it was not until the advent of deep learning that generative models saw significant improvements in performance.
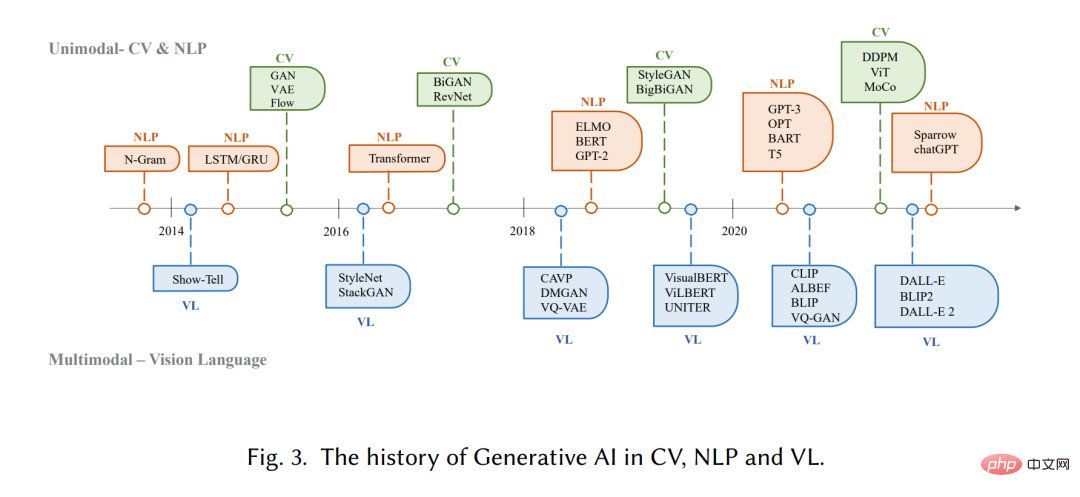
In early deep generative models, different domains usually did not overlap much. In natural language processing (NLP), the traditional method of generating sentences is to use N-gram language modeling [22] to learn the word distribution and then search for the best sequence. However, this method cannot effectively adapt to long sentences. To solve this problem, Recurrent Neural Networks (RNN) [23] were later introduced to language modeling tasks, allowing relatively long dependencies to be modeled. Subsequently, the development of long short-term memory (LSTM) [24] and gated recurrent units (GRU) [25], which utilize gating mechanisms to control memory during training. These methods are able to handle ~200 tokens in the sample [26], which is a significant improvement compared to N-gram language models.
Meanwhile, in the field of computer vision (CV), before the emergence of deep learning-based methods, traditional image generation algorithms used techniques such as texture synthesis [27] and texture mapping [28] . These algorithms are based on hand-designed features and have limited capabilities in generating complex and diverse images. In 2014, Generative Adversarial Networks (GANs) [29] were first proposed and achieved impressive results in various applications, which is an important milestone in this field. Variational autoencoders (VAE) [30] and other methods, such as diffusion generative models [31], have also been developed for finer-grained control of the image generation process and the ability to generate high-quality images
The development of generative models in different fields follows different paths, but eventually a cross-cutting problem arises: transformer architecture [32]. Vaswani et al. introduced the NLP task in 2017, and Transformer was later applied to CV, and then became the main backbone of many generative models in different fields [9, 33, 34]. In the field of NLP, many well-known large-scale language models, such as BERT and GPT, adopt the transformer architecture as their main building block, which has advantages over previous building blocks such as LSTM and GRU. In CV, Vision Transformer (ViT) [35] and Swin Transformer [36] later developed this concept further by combining the Transformer architecture with a vision component so that it can be applied to image-based downstream. In addition to the improvements brought by transformers to individual modalities, this crossover also enables models from different domains to be fused together to complete multi-modal tasks. An example of a multimodal model is CLIP [37]. CLIP is a joint vision-language model that combines a transformer architecture with a vision component, allowing it to be trained on large amounts of text and image data. Since it combines visual and linguistic knowledge during pre-training, it can also be used as an image encoder in multi-modal cue generation. All in all, the emergence of transformer-based models has revolutionized the production of artificial intelligence and led to the possibility of large-scale training.
In recent years, researchers have also begun to introduce new technologies based on these models. For example, in NLP, people sometimes prefer few-shot hints [38] to fine-tuning, which refers to including a few examples selected from the dataset in the hint to help the model better understand the task requirements. In visual languages, researchers often combine modality-specific models with self-supervised contrastive learning objectives to provide more robust representations. In the future, as AIGC becomes more and more important, more and more technologies will be introduced, making this field full of vitality.
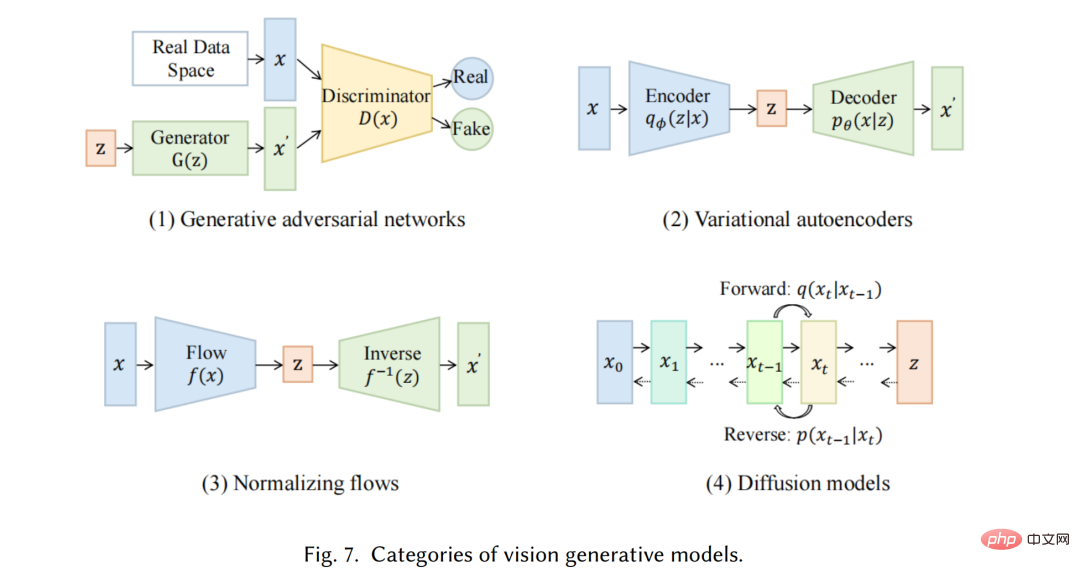
We will introduce the state-of-the-art single-modal generative models. These models are designed to accept a specific raw data modality as input, such as text or images, and then generate predictions in the same modality as the input. We will discuss some of the most promising methods and techniques used in these models, including generative language models such as GPT3 [9], BART [34], T5 [56] and generative vision models such as GAN [29], VAE [ 30] and normalized flow [57].
Multimodal generation is today’s AIGC important parts of. The goal of multimodal generation is to learn to generate models of original modalities by learning multimodal connections and interactions of data [7]. Such connections and interactions between modalities are sometimes very complex, which makes multimodal representation spaces difficult to learn compared to single-modal representation spaces. However, with the emergence of the powerful pattern-specific infrastructure mentioned earlier, more and more methods are being proposed to address this challenge. In this section, we introduce state-of-the-art multimodal models in visual language generation, textual audio generation, textual graphics generation, and textual code generation. Since most multimodal generative models are always highly relevant to practical applications, this section mainly introduces them from the perspective of downstream tasks.
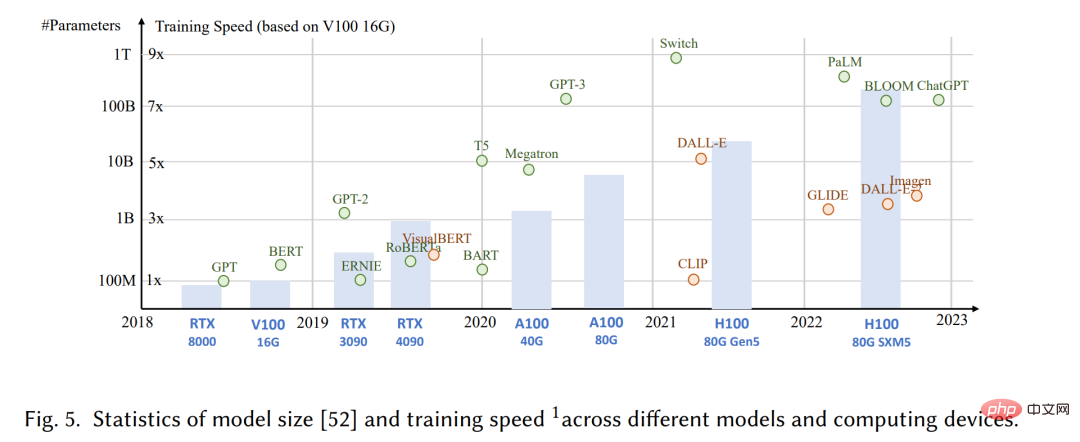
Over the past decade, deep generative artificial intelligence models with neural networks have dominated the field of machine learning, with their rise attributed to the 2012 ImageNet competition [210 ], which has led to a race to create deeper and more complex models. This trend has also appeared in the field of natural language understanding, where models like BERT and GPT-3 have developed a large number of parameters. However, the increasing model footprint and complexity, as well as the cost and resources required for training and deployment, pose challenges for practical deployment in the real world. The core challenge is efficiency, which can be broken down as follows:
The above is the detailed content of 'From GAN to ChatGPT: Lehigh University details the development of AI-generated content'. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



