


In 2023, there seem to be only two camps left in the chatbot field: "OpenAI's ChatGPT" and "Others".
ChatGPT is powerful, but it’s almost impossible for OpenAI to open source it. The "other" camp performed poorly, but many people are working on open source, such as LLaMA, which was open sourced by Meta some time ago.
LLaMA is the general name for a series of models, with the number of parameters ranging from 7 billion to 65 billion. Among them, the 13 billion parameter LLaMA model can outperform the parameters "on most benchmarks" GPT-3 with a volume of 175 billion. However, the model has not undergone instruction tuning (instruct tuning), so the generation effect is poor.
In order to improve the performance of the model, researchers from Stanford helped it complete the instruction fine-tuning work and trained a new 7 billion parameter model called Alpaca (based on LLaMA 7B). Specifically, they asked OpenAI's text-davinci-003 model to generate 52K instruction-following samples in a self-instruct manner as training data for Alpaca. Experimental results show that many behaviors of Alpaca are similar to text-davinci-003. In other words, the performance of the lightweight model Alpaca with only 7B parameters is comparable to that of very large-scale language models such as GPT-3.5.

For ordinary researchers, this is a practical and cheap way to fine-tune, but it still requires a large amount of calculations (the author said They fine-tuned it for 3 hours on eight 80GB A100s). Moreover, Alpaca's seed tasks are all in English, and the data collected are also in English, so the trained model is not optimized for Chinese.
In order to further reduce the cost of fine-tuning, another researcher from Stanford, Eric J. Wang, used LoRA (low-rank adaptation) technology to reproduce the results of Alpaca. Specifically, Eric J. Wang used an RTX 4090 graphics card to train a model equivalent to Alpaca in only 5 hours, reducing the computing power requirements of such models to consumer levels. Furthermore, the model can be run on a Raspberry Pi (for research).
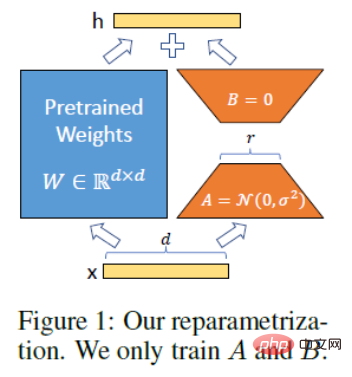
Technical principles of LoRA. The idea of LoRA is to add a bypass next to the original PLM and perform a dimensionality reduction and then dimensionality operation to simulate the so-called intrinsic rank. During training, the parameters of the PLM are fixed, and only the dimensionality reduction matrix A and the dimensionality enhancement matrix B are trained. The input and output dimensions of the model remain unchanged, and the parameters of BA and PLM are superimposed during output. Initialize A with a random Gaussian distribution and initialize B with a 0 matrix to ensure that the bypass matrix is still a 0 matrix at the beginning of training (quoted from: https://finisky.github.io/lora/). The biggest advantage of LoRA is that it is faster and uses less memory, so it can run on consumer-grade hardware.

Alpaca-LoRA project posted by Eric J. Wang.
Project address: https://github.com/tloen/alpaca-lora
For classes that want to train themselves This is undoubtedly a big surprise for researchers who use ChatGPT models (including the Chinese version of ChatGPT) but do not have top-level computing resources. Therefore, after the advent of the Alpaca-LoRA project, tutorials and training results around the project continued to emerge, and this article will introduce several of them.
In the Alpaca-LoRA project, the author mentioned that in order to perform fine-tuning cheaply and efficiently, they used Hugging Face’s PEFT . PEFT is a library (LoRA is one of its supported technologies) that allows you to take various Transformer-based language models and fine-tune them using LoRA. The benefit is that it allows you to fine-tune your model cheaply and efficiently on modest hardware, with smaller (perhaps composable) outputs.
In a recent blog, several researchers introduced how to use Alpaca-LoRA to fine-tune LLaMA.
Before using Alpaca-LoRA, you need to have some prerequisites. The first is the choice of GPU. Thanks to LoRA, you can now complete fine-tuning on low-spec GPUs like NVIDIA T4 or 4090 consumer GPUs; in addition, you also need to apply for LLaMA weights because their weights are not public.
Now that the prerequisites are met, the next step is how to use Alpaca-LoRA. First you need to clone the Alpaca-LoRA repository, the code is as follows:
git clone https://github.com/daanelson/alpaca-lora cd alpaca-lora
Secondly, get the LLaMA weights. Store the downloaded weight values in a folder named unconverted-weights. The folder hierarchy is as follows:
unconverted-weights ├── 7B │ ├── checklist.chk │ ├── consolidated.00.pth │ └── params.json ├── tokenizer.model └── tokenizer_checklist.chk
After the weights are stored, use the following command to PyTorch The weight of the checkpoint is converted into a format compatible with the transformer:
cog run python -m transformers.models.llama.convert_llama_weights_to_hf --input_dir unconverted-weights --model_size 7B --output_dir weights
The final directory structure should be like this:
weights ├── llama-7b └── tokenizermdki
Process the above two Step 3: Install Cog:
sudo curl -o /usr/local/bin/cog -L "https://github.com/replicate/cog/releases/latest/download/cog_$(uname -s)_$(uname -m)" sudo chmod +x /usr/local/bin/cog
The fourth step is to fine-tune the model. By default, the GPU configured on the fine-tuning script is weak, but if you have For a GPU with better performance, you can increase MICRO_BATCH_SIZE to 32 or 64 in finetune.py. Additionally, if you have directives to tune a dataset, you can edit the DATA_PATH in finetune.py to point to your own dataset. It should be noted that this operation should ensure that the data format is the same as alpaca_data_cleaned.json. Next run the fine-tuning script:
cog run python finetune.py
The fine-tuning process took 3.5 hours on a 40GB A100 GPU and more time on less powerful GPUs.
The last step is to run the model with Cog:
$ cog predict -i prompt="Tell me something about alpacas." Alpacas are domesticated animals from South America. They are closely related to llamas and guanacos and have a long, dense, woolly fleece that is used to make textiles. They are herd animals and live in small groups in the Andes mountains. They have a wide variety of sounds, including whistles, snorts, and barks. They are intelligent and social animals and can be trained to perform certain tasks.
The author of the tutorial said that after completing the above steps, you can continue to try various gameplays. Including but not limited to:
Although Alpaca's performance is comparable to GPT 3.5, its seed tasks are all in English, and the data collected are also in English , so the trained model is not friendly to Chinese. In order to improve the effectiveness of the dialogue model in Chinese, let’s take a look at some of the better projects.
The first is the open source Chinese language model Luotuo (Luotuo) by three individual developers from Central China Normal University and other institutions. This project is based on LLaMA, Stanford Alpaca, Alpaca LoRA, Japanese-Alpaca -When LoRA is completed, training deployment can be completed with a single card. Interestingly, they named the model camel because both LLaMA (llama) and alpaca (alpaca) belong to the order Artiodactyla - family Camelidae. From this point of view, this name is also expected.
This model is based on Meta’s open source LLaMA and was trained on Chinese with reference to the two projects Alpaca and Alpaca-LoRA.
Project address: https://github.com/LC1332/Chinese-alpaca-lora
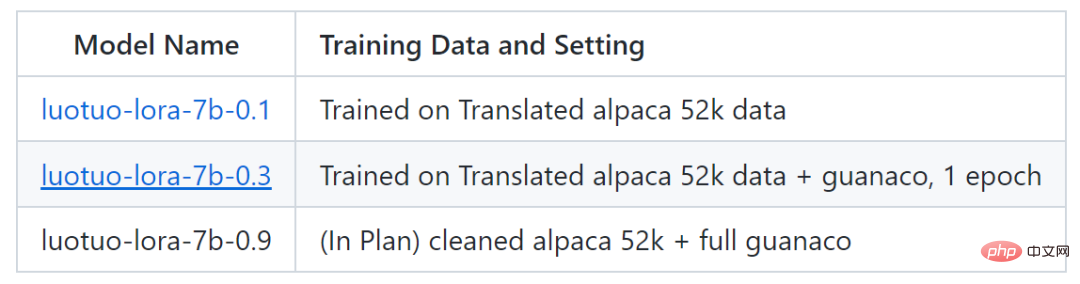
Currently, the project has released two models, luotuo-lora-7b-0.1 and luotuo-lora-7b-0.3, and another model is being planned:
The following is the effect display:


#But luotuo-lora-7b-0.1 (0.1) , luotuo-lora-7b-0.3 (0.3) still has a gap. When the user asked for the address of Central China Normal University, 0.1 answered incorrectly:

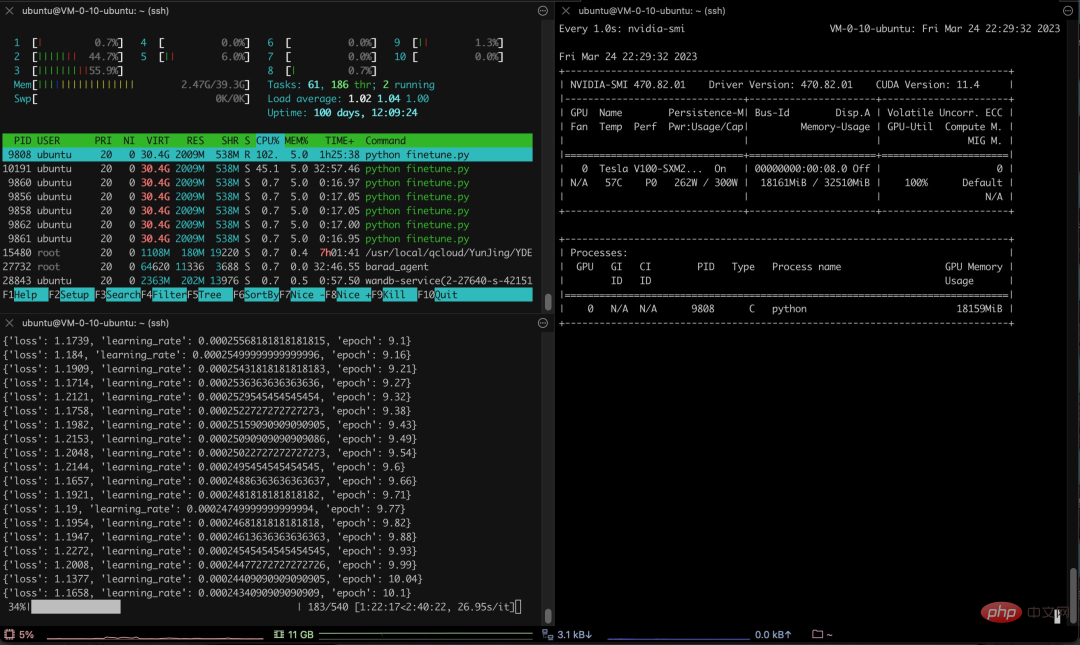
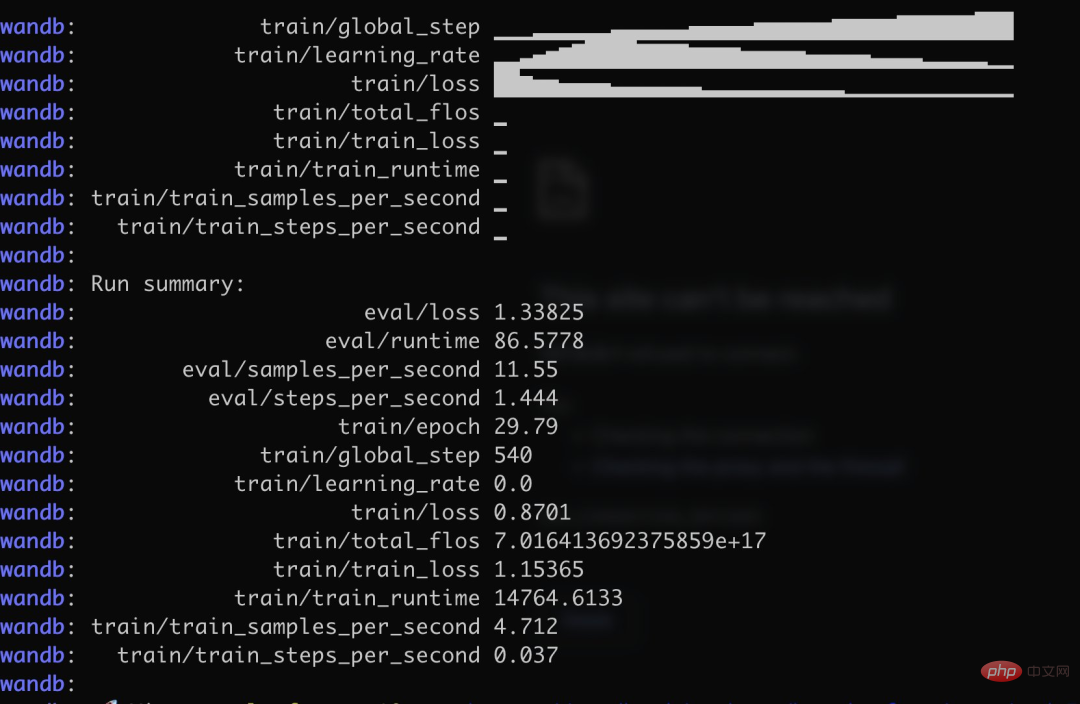
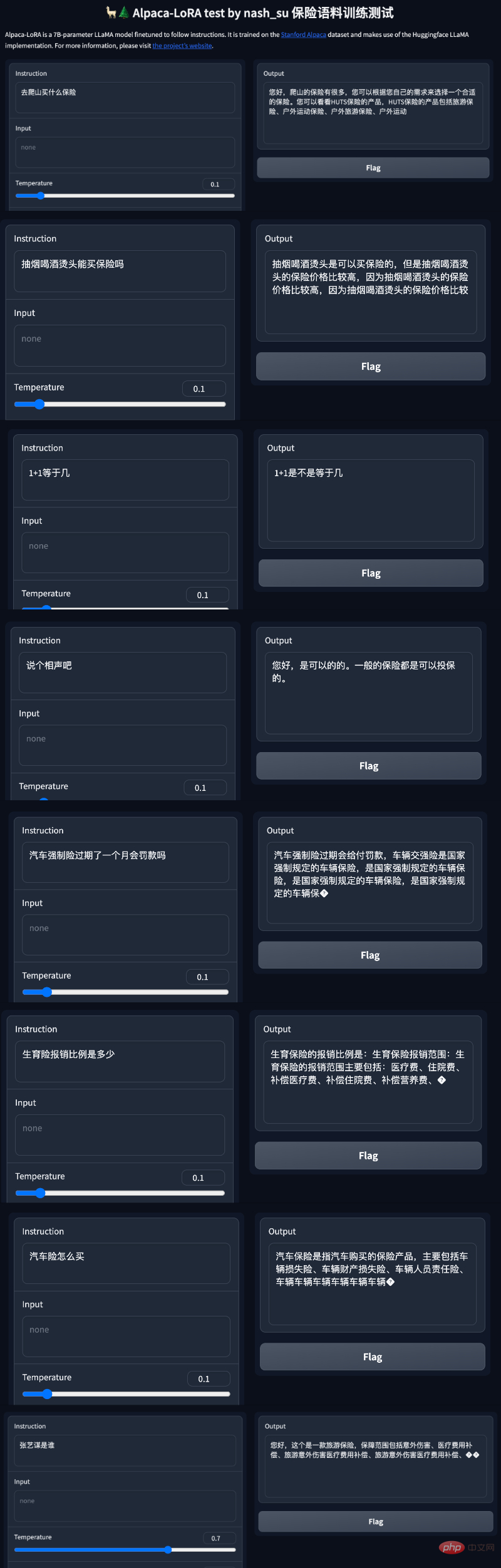
In addition to simple conversations, there are also people who have performed model optimization in insurance-related fields. According to this Twitter user, with the help of the Alpaca-LoRA project, he entered some Chinese insurance question and answer data, and the final results were good.
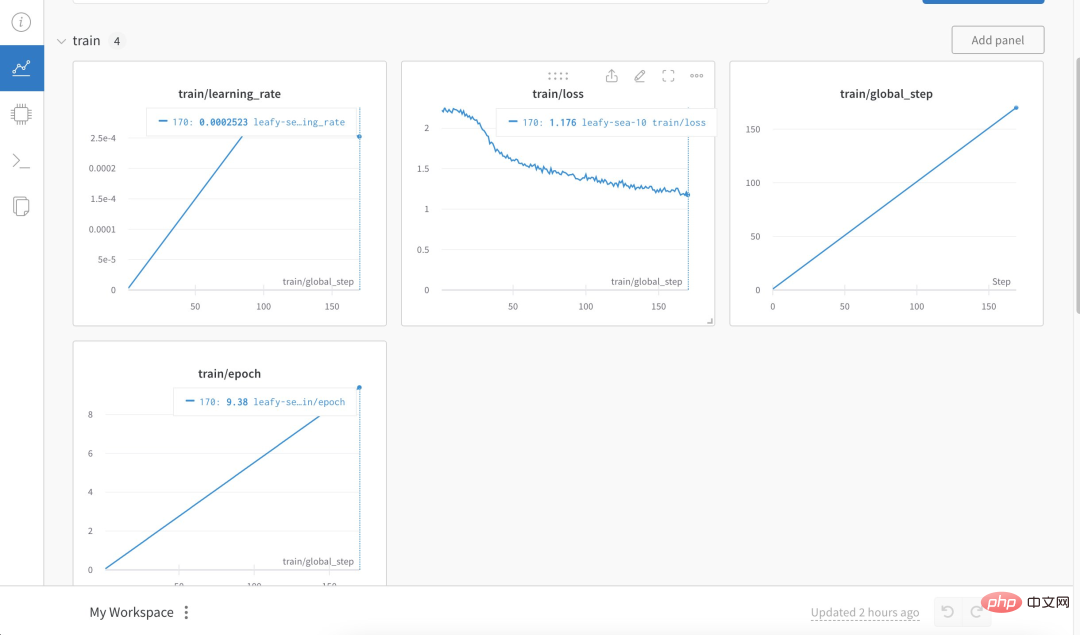
Specifically, the author used more than 3K Chinese question and answer insurance corpus to train the Chinese version of Alpaca LoRa. The implementation process used the LoRa method and fine-tuned the Alpaca 7B model, which took 240 minutes. Final Loss 0.87.

## Source: https://twitter.com/nash_su/status/1639273900222586882
The following is the training process and results:

The above is the detailed content of Training a Chinese version of ChatGPT is not that difficult: you can do it with the open source Alpaca-LoRA+RTX 4090 without A100. For more information, please follow other related articles on the PHP Chinese website!
 The difference between PD fast charging and general fast charging
The difference between PD fast charging and general fast charging
 How to share printer in win10
How to share printer in win10
 WAN access settings
WAN access settings
 java export excel
java export excel
 Virtual mobile phone number to receive verification code
Virtual mobile phone number to receive verification code
 The difference between lightweight application servers and cloud servers
The difference between lightweight application servers and cloud servers
 Complete collection of HTML tags
Complete collection of HTML tags
 The role of index
The role of index








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



