


In recent years, language models have had a revolutionary impact on natural language processing (NLP). It is known that extending language models, such as parameters, can lead to better performance and sample efficiency on a range of downstream NLP tasks. In many cases, the impact of scaling on performance can often be predicted by scaling laws, and most researchers have been studying predictable phenomena.
On the contrary, 16 researchers including Jeff Dean, Percy Liang, etc. collaborated on the paper "Emergent Abilities of Large Language Models". They discussed the phenomenon of large model unpredictability and This is called the emergent abilities of large language models. The so-called emergence means that some phenomena do not exist in the smaller model but exist in the larger model. They believe that this ability of the model is emergent.
Emergence as an idea has been discussed for a long time in fields such as physics, biology, and computer science. This paper starts with a general definition of emergence, adapted from Steinhardt's research, and is rooted in an article titled More Is Different by Nobel Prize winner and physicist Philip Anderson in 1972.
This article explores the emergence of model size, as measured by training calculations and model parameters. Specifically, this paper defines the emergent capabilities of large language models as capabilities that are not present in small-scale models but are present in large-scale models; therefore, large-scale models cannot be predicted by simply extrapolating the performance improvements of small-scale models . This study investigates the emergent capabilities of models observed in a range of previous work and classifies them into settings such as small-shot cueing and boosted cueing.
This emergent capability of the model inspires future research into why these capabilities are acquired and whether larger scales acquire more emergent capabilities and highlights this The importance of research.

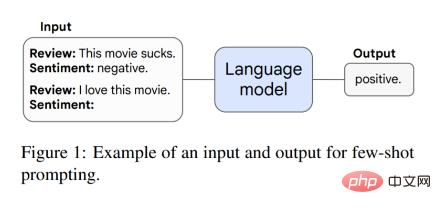



Currently, although small sample hints are the most common way to interact with large language models, recent work has proposed several other hints and fine-tuning strategies to further enhance the capabilities of language models. This article also considers a technology to be an emergent capability if it does not show improvement or is harmful before being applied to a large enough model.
Multi-step reasoning: For language models and NLP models, reasoning tasks, especially those involving multi-step reasoning, have always been a big challenge. . A recent prompting strategy called chain-of-thought enables language models to solve this type of problem by guiding them to generate a series of intermediate steps before giving a final answer. As shown in Figure 3A, when scaling to 1023 training FLOPs (~100B parameters), the thought chain prompt only surpassed the standard prompt with no intermediate steps.
Instruction (Instruction following): As shown in Figure 3B, Wei et al. found that when the training FLOP is 7·10^21 (8B parameters) or smaller, the instruction fine-tuning (instruction following) -finetuning) technique hurts model performance and only improves performance when extending training FLOPs to 10^23 (~100B parameters).
Program execution: As shown in Figure 3C, in the in-domain evaluation of 8-bit addition, using scratchpad only helps ∼9 · 10^19 training FLOP (40M parameters) or larger models. Figure 3D shows that these models can also generalize to out-of-domain 9-bit addition, which occurs in ∼1.3 · 10^20 training FLOPs (100M parameters).

This article discusses the emergent power of language models, which so far has only been observed at certain computational scales Meaningful performance. This emergent capability of models can span a variety of language models, task types, and experimental scenarios. The existence of this emergence means that additional scaling can further expand the capabilities of language models. This ability is the result of recently discovered language model extensions. How they emerged and whether more extensions will bring more emergent capabilities may be important future research directions in the field of NLP.
For more information, please refer to the original paper.
The above is the detailed content of New work by Jeff Dean and others: Looking at language models from another angle, the scale is not large enough and cannot be discovered. For more information, please follow other related articles on the PHP Chinese website!
 How to use label label
How to use label label Introduction to the main work content of front-end engineers
Introduction to the main work content of front-end engineers What is an empty array in php
What is an empty array in php cloud computing technology
cloud computing technology What are the access modifiers for classes in php
What are the access modifiers for classes in php The difference between css3.0 and css2.0
The difference between css3.0 and css2.0 Complement algorithm for negative numbers
Complement algorithm for negative numbers What are the linux shutdown and restart commands?
What are the linux shutdown and restart commands?




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



