


This paper is about the work of deep reinforcement learning to resist attacks. In this paper, the author studies the robustness of deep reinforcement learning strategies to adversarial attacks from the perspective of robust optimization. Under the framework of robust optimization, the optimal adversarial attack is given by minimizing the expected return of the strategy, and accordingly, a good defense mechanism is achieved by improving the performance of the strategy in coping with the worst case scenario.
Considering that attackers are usually unable to attack in the training environment, the author proposes a greedy attack algorithm that attempts to minimize the expected return of the strategy without interacting with the environment; in addition, the author also proposes a A defense algorithm that uses max-min games to conduct adversarial training of deep reinforcement learning algorithms.
The experimental results in the Atari game environment show that the adversarial attack algorithm proposed by the author is more effective than the existing attack algorithm, and the strategy return rate is worse. The strategies generated by the adversarial defense algorithm proposed in the paper are more robust to a range of adversarial attacks than existing defense methods.
Given any sample (x, y) and neural network f, the optimization goal of generating an adversarial sample is:
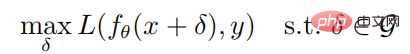
where is the parameter of the neural network f, L is the loss function, is the adversarial perturbation set,  is the norm constraint ball with x as the center and as the radius. The calculation formula for generating adversarial samples through PGD attacks is as follows:
is the norm constraint ball with x as the center and as the radius. The calculation formula for generating adversarial samples through PGD attacks is as follows:
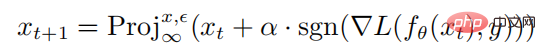
where  represents the projection operation. If the input is outside the norm sphere, the input will be projected On the sphere with x center and as the radius, represents the single-step disturbance size of the PGD attack.
represents the projection operation. If the input is outside the norm sphere, the input will be projected On the sphere with x center and as the radius, represents the single-step disturbance size of the PGD attack.
2.2 Reinforcement Learning and Policy Gradients
A reinforcement learning problem can be described as a Markov decision process. The Markov decision process can be defined as a 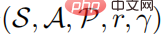 quintuple, where S represents a state space, A represents an action space,
quintuple, where S represents a state space, A represents an action space, 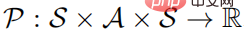 represents the state transition probability, and r represents The reward function represents the discount factor. The goal of strong learning learning is to learn a parameter policy distribution
represents the state transition probability, and r represents The reward function represents the discount factor. The goal of strong learning learning is to learn a parameter policy distribution to maximize the value function
to maximize the value function
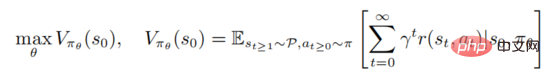
where represents the initial state. Strong learning involves evaluating the action value function
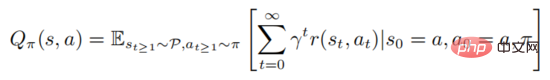
The above formula describes the mathematical expectation of obeying the policy after the state is executed. It can be seen from the definition that the value function and the action value function satisfy the following relationship:
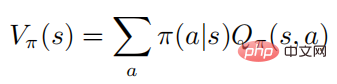
#For ease of expression, the author mainly focuses on the Markov process of the discrete action space, but all algorithms and results can be applied directly to successive settings.
The adversarial attack and defense of deep reinforcement learning strategies are based on the framework of robust optimization PGD
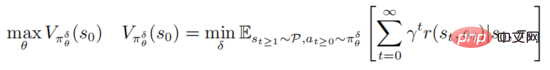
where represents  , represents the set of adversarial perturbation sequences
, represents the set of adversarial perturbation sequences  , and for all
, and for all 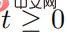 , satisfying
, satisfying 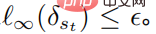 The above formula provides a unified framework for deep reinforcement learning to combat attacks and defenses.
The above formula provides a unified framework for deep reinforcement learning to combat attacks and defenses.
On the one hand, internal minimization optimization seeks to find confrontational perturbation sequences that make the current strategy make wrong decisions. On the other hand, the purpose of external maximization is to find the strategy distribution parameters to maximize the expected return under the perturbation strategy. After the above adversarial attacks and defense games, the strategy parameters during the training process will be more resistant to adversarial attacks.
The purpose of internal minimization of the objective function is to generate adversarial perturbations, but for reinforcement learning algorithms to learn the optimal adversarial perturbations is very time-consuming and labor-intensive, and because the training environment is a threat to the attacker It is black box, so in this paper, the author considers a practical setting, that is, the attacker injects perturbations in different states. In the supervised learning attack scenario, the attacker only needs to trick the classifier model to make it misclassify and produce wrong labels; in the reinforcement learning attack scenario, the action value function provides the attacker with additional information, that is, a small behavior value will Resulting in a small expected return. Correspondingly, the author defines the optimal adversarial perturbation in deep reinforcement learning as follows
Definition 1: An optimal adversarial perturbation on state s can minimize the expected return of the state
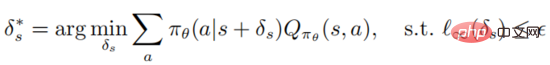
It should be noted that optimizing and solving the above formula is very tricky. It needs to ensure that the attacker can deceive the agent into choosing the worst decision-making behavior. However, for the attacker, the agent The action value function is agnostic, so there is no guarantee that it will be optimal against perturbations. The following theorem can show that if the policy is optimal, the optimal adversarial perturbation can be generated without accessing the action value function
Theorem 1: When the control strategy 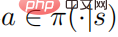 is optimal, the action value The function and strategy satisfy the following relationship
is optimal, the action value The function and strategy satisfy the following relationship
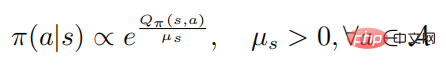
where represents the policy entropy, is a state-dependent constant, and when changes to 0, it will also change to 0, Furthermore, the following formula
proves: When the random strategy 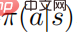 reaches the optimal, the value function
reaches the optimal, the value function 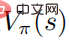 also reaches the optimal, which means that in each state s, it is impossible to find to any other behavioral distribution such that the value function
also reaches the optimal, which means that in each state s, it is impossible to find to any other behavioral distribution such that the value function 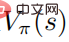 increases. Correspondingly, given the optimal action value function
increases. Correspondingly, given the optimal action value function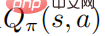 , the optimal strategy can be obtained by solving the constrained optimization problem
, the optimal strategy can be obtained by solving the constrained optimization problem
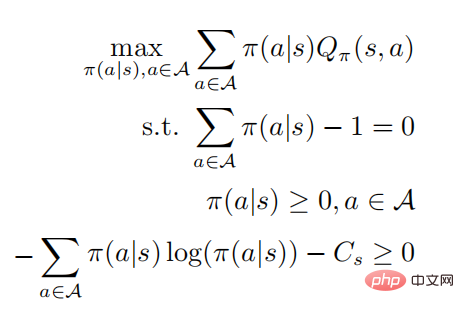
The second and third lines represents a probability distribution, and the last line represents that the strategy is a random strategy. According to the KKT condition, the above optimization problem can be transformed into the following form:
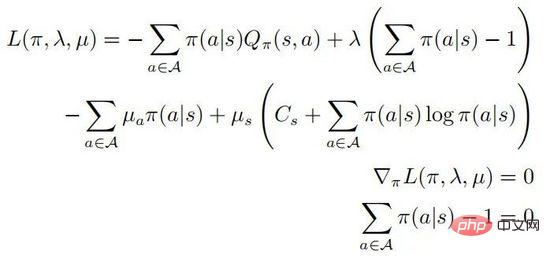
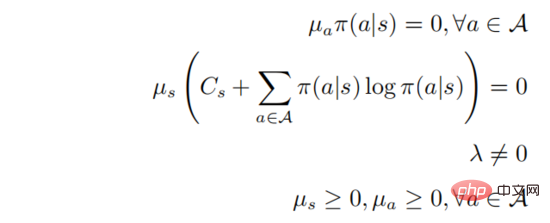
in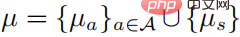 . Assume that
. Assume that 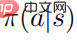 is positive definite for all actions
is positive definite for all actions 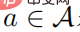 , then:
, then:
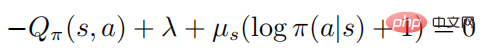
When 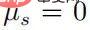 , then there must be
, then there must be 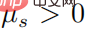 , and then for any ’s
, and then for any ’s 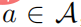 , then there is
, then there is 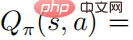 , thus we will get the relationship between the action value function and the softmax of the strategy
, thus we will get the relationship between the action value function and the softmax of the strategy
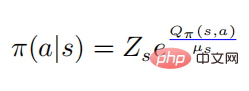
 , and then there is
, and then there is
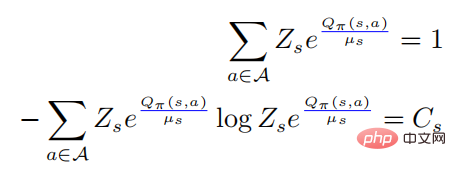
Bringing the first equation above into the second equation, we have
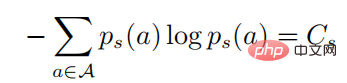
where
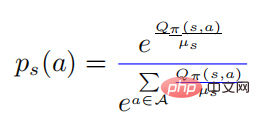
In the above formula, 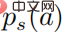 represents a probability distribution in the form of softmax, and its entropy is equal to . When is equal to 0, also becomes 0. In this case, is greater than 0, then
represents a probability distribution in the form of softmax, and its entropy is equal to . When is equal to 0, also becomes 0. In this case, is greater than 0, then  at this time.
at this time.
Theorem 1 shows that if the strategy is optimal, the optimal perturbation can be obtained by maximizing the cross-entropy of the perturbation strategy and the original strategy. For the simplicity of discussion, the author calls the attack of Theorem 1 a strategic attack, and the author uses the PGD algorithm framework to calculate the optimal strategic attack. The specific algorithm flow chart is shown in Algorithm 1 below.

The flow chart of the robust optimization algorithm for defense against perturbation proposed by the author is shown in Algorithm 2 below. This algorithm is called strategic attack adversarial training. During the training phase, the perturbation policy is used to interact with the environment, while the action value function 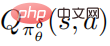 of the perturbation policy is estimated to aid policy training.
of the perturbation policy is estimated to aid policy training.
The specific details are that the author first uses strategic attacks to generate perturbations during the training phase, even though the value function is not guaranteed to be reduced. In the early stages of training, the policy may not be related to the action value function. As training progresses, they will gradually satisfy the softmax relationship.
On the other hand the authors need to accurately estimate the action value function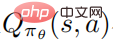 It is difficult to handle because the trajectories are collected by running the perturbed policy, and using these data to estimate the action value function of the unperturbed policy can be very Inaccurate.
It is difficult to handle because the trajectories are collected by running the perturbed policy, and using these data to estimate the action value function of the unperturbed policy can be very Inaccurate.

The objective function of the optimized perturbation strategy 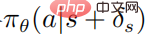 using PPO is
using PPO is
where 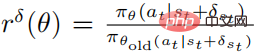 , and
, and 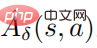 is an estimate of the average function
is an estimate of the average function 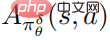 of the perturbation strategy. In practice,
of the perturbation strategy. In practice, 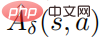 is estimated by the method GAE. The specific algorithm flow chart is shown in the figure below.
is estimated by the method GAE. The specific algorithm flow chart is shown in the figure below.

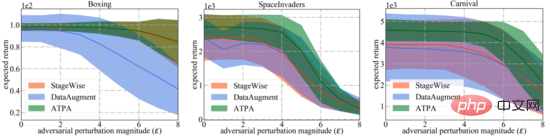
The three sub-figures on the right below show the results of different attack perturbations. It can be found that both the inversely trained policy and the standard policy are resistant to random perturbations. In contrast, adversarial attacks degrade the performance of different strategies. The results depend on the test environment and defense algorithm, and further it can be found that the performance gap between the three adversarial attack algorithms is small.
In contrast, in relatively difficult settings, the strategy proposed by the paper's authors to attack algorithm interference produces much lower returns. Overall, the strategic attack algorithm proposed in the paper produces the lowest reward in most cases, indicating that it is indeed the most efficient of all tested adversarial attack algorithms.

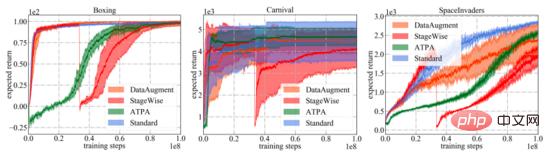
The following figure shows the learning curves of different defense algorithms and standard PPO. It is important to note that the performance curve only represents the expected return of the strategy used to interact with the environment. Among all training algorithms, ATPA proposed in the paper has the lowest training variance and is therefore more stable than other algorithms. Also notice that ATPA progresses much slower than standard PPO, especially in the early training stages. This leads to the fact that in the early stages of training, being disturbed by adverse factors can make policy training very unstable.
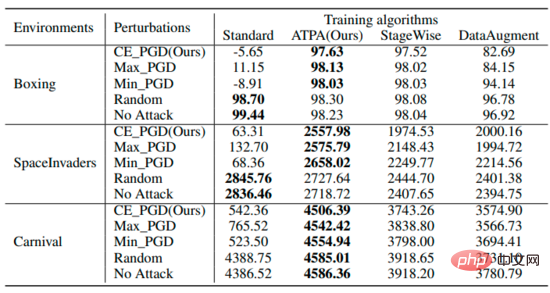
#The table summarizes the expected returns of the strategy under different perturbations using different algorithms. It can be found that ATPA-trained strategies are resistant to various adversarial interferences. In comparison, although StageWise and DataAugment have learned to handle adversarial attacks to some extent, they are not as effective as ATPA in all cases.
For a broader comparison, the authors also evaluate the robustness of these defense algorithms to varying degrees of adversarial interference generated by the most effective strategic attack algorithms. As shown below, ATPA once again received the highest scores in all cases. In addition, the evaluation variance of ATPA is much smaller than that of StageWise and DataAugment, indicating that ATPA has stronger generative ability.
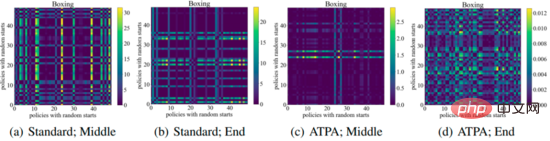
To achieve similar performance, ATPA requires more training data than the standard PPO algorithm. The authors delve into this issue by studying the stability of the perturbation strategy. The authors calculated the KL divergence values of the perturbation policy obtained by performing policy attacks using PGD with different random initial points in the middle and at the end of the training process. As shown in the figure below, without adversarial training, large KL divergence values are continuously observed even if the standard PPO has converged, indicating that the policy is very unstable to the perturbations produced by performing PGD with different initial points.
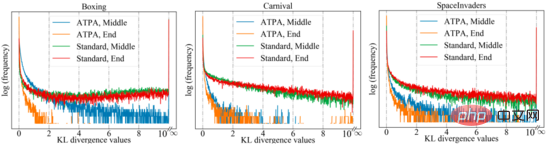
The following figure shows the KL divergence plot of the perturbation strategy with different initial points. It can be found that each pixel in the figure represents the KL divergence value of the two perturbation strategies. , these two perturbation strategies are given by maximizing the core formula of the ATPA algorithm. Note that since KL divergence is an asymmetric metric, these mappings are also asymmetric.
The above is the detailed content of Adversarial attacks and defenses in deep reinforcement learning. For more information, please follow other related articles on the PHP Chinese website!
 Solution to Win7 folder properties not sharing tab page
Solution to Win7 folder properties not sharing tab page
 what is vuex
what is vuex
 How to clean the computer's C drive that is too full
How to clean the computer's C drive that is too full
 Mathematical modeling software
Mathematical modeling software
 The difference between vscode and vs
The difference between vscode and vs
 How to type the inscription on the coin circle?
How to type the inscription on the coin circle?
 How to decrypt bitlocker encryption
How to decrypt bitlocker encryption
 How to solve the slow download problem of Baidu Netdisk
How to solve the slow download problem of Baidu Netdisk








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



