

The following column Redis Tutorial will introduce to you how to ensure high concurrency of Redis. I hope it will be helpful to friends in need!
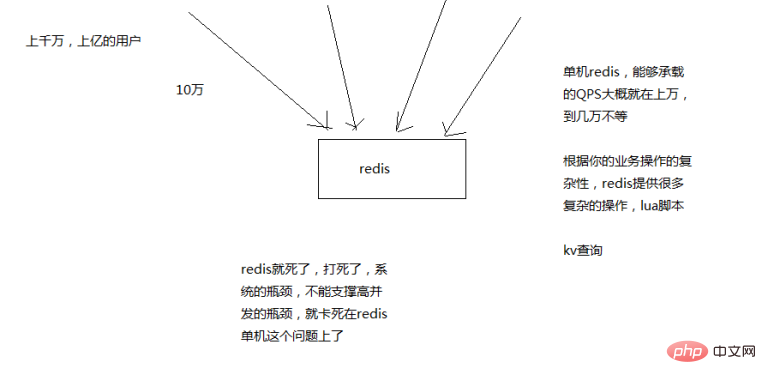
It is almost impossible for a stand-alone redis to have a QPS of more than 100,000, usually in the tens of thousands.
Unless there are some special circumstances, such as your machine performance is particularly good, the configuration is particularly high, the physical machine is well maintained, and your overall operation is not too complicated.
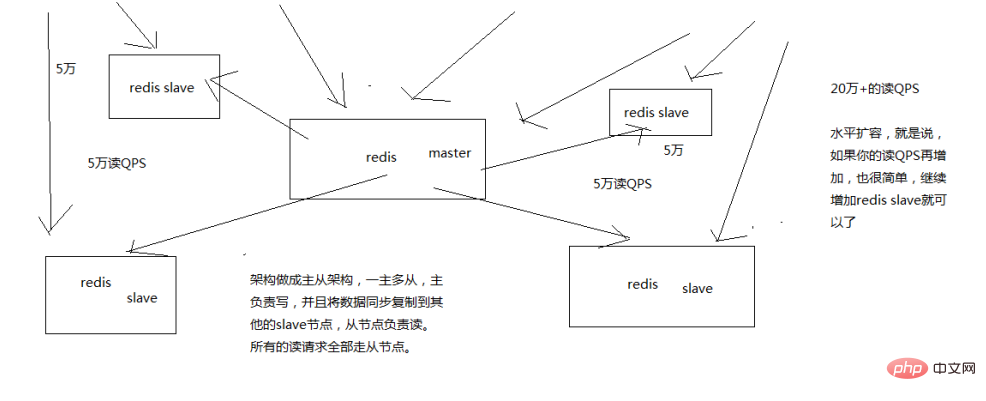
Redis implements read-write separation through a master-slave architecture. The master node is responsible for writing and synchronizing data to other slaves. Node, the slave node is responsible for reading, thereby achieving high concurrency.
While Redis has high concurrency, it also needs to accommodate a large amount of data: one master and multiple slaves, and each instance accommodates complete data. For example, the redis master With 10G of memory, you can actually only hold 10G of data. If your cache needs to accommodate a large amount of data, reaching tens of gigabytes, or even hundreds of gigabytes, or several tons, then you need a redis cluster, and with redis cluster, you can provide hundreds of thousands of data per second. Read and write concurrently.
The core mechanism of replication
Redis uses an asynchronous method to copy data to the slave node. However, starting from redis 2.8, the slave node will periodically confirm the amount of data copied each time
A master node can be configured with multiple slave nodes
slave node You can also connect to other slave nodes
When the slave node replicates, it will not block the normal work of the master node
When the slave node replicates, It will not block its own query operations. It will use the old data set to provide services; but when the copy is completed, the old data set needs to be deleted and the new data set loaded. At this time, external services will be suspended
The slave node is mainly used for horizontal expansion and separation of reading and writing. The expanded slave node can improve the read throughput
The significance of master persistence for the security of the master-slave architecture
If a master-slave architecture is adopted, it is recommended that the persistence of the master node must be turned on!
It is not recommended to use the slave node as the data hot backup of the master node, because in that case, if you turn off the persistence of the master, the data may be empty when the master crashes and restarts. , and then the salve node data may be lost as soon as it is copied
Second, do you want to do various backup plans for the master, in case all the local files are lost; Select an rdb from the backup to restore the master; this will ensure that there is data when the master starts.
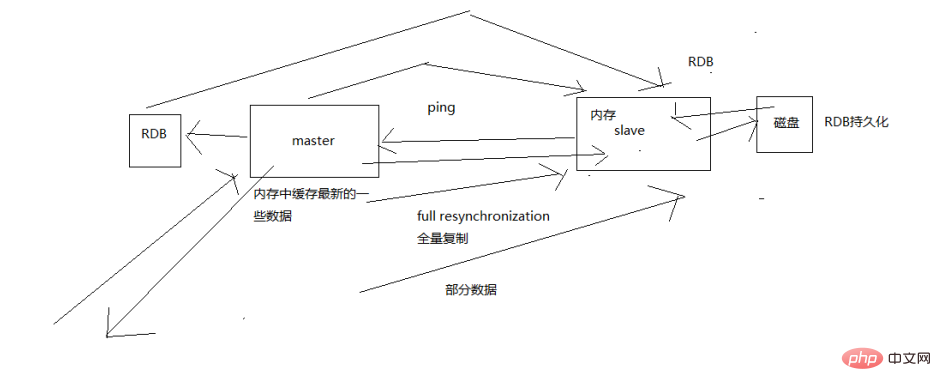
The process of master synchronizing data to slave
When starting a slave node, it will send a PSYNC command to the master node
If this is the slave node reconnecting to the master node, then the master node will only copy the missing data to the slave; otherwise, if the slave node connects to the master node for the first time, a full resynchronization will be triggered
When starting full resynchronization, the master will start a background thread and start generating an RDB snapshot file. At the same time, all write commands received from the client will be cached in memory.
After the RDB file is generated, the master will send the RDB to the slave. The slave will first write it to the local disk and then load it from the local disk into the memory. Then the master will send the write commands cached in the memory to the slave, and the slave will also synchronize the data.
If the slave node has a network failure with the master node and is disconnected, it will automatically reconnect. If the master finds that multiple slave nodes are reconnecting, it will only start an rdb save operation and use a copy of data to serve all slave nodes.
Resume the breakpoint of master-slave replication
Starting from redis 2.8, breakpoint resumption of master-slave replication is supported. If the network connection is disconnected during the master-slave replication process, you can continue the replication from the last replication point, instead of Make a copy from scratch
The master node will have a backlog in the memory. Both the master and the slave will save a replica offset and a master id. The offset is saved in the backlog.
If the network connection between the master and the slave is disconnected, the slave will let the master continue replicating from the last replica offset
But if not If the corresponding offset is found, a resynchronization will be performed
Diskless copy
The master will be directly in the memory Create rdb and then send it to the slave. The disk will not be landed locally
repl-diskless-sync
repl-diskless-sync-delay, Wait for a certain period of time before starting replication, because you have to wait for more slaves to reconnect
Expired key processing
slave The key will not expire, but will only wait for the master to expire the key.
If the master expires a key, or eliminates a key through LRU, a del command will be simulated and sent to the slave.
The complete process of replication
The slave node starts and only saves the information of the master node , including the host and IP of the master node (configured by slaveof in redis.conf), but the replication process has not started
There is a scheduled task inside the slave node, which checks whether there is new data every second The master node needs to be connected and replicated. If found, it will establish a socket network connection with the master node
The slave node sends a ping command to the master node
Password authentication, if the master If requirepass is set, then the slave node must send the masterauth password for authentication
The master node performs full replication for the first time and sends all data to the slave node
The master The node will continue to write commands and asynchronously copy them to the slave node
The core mechanism related to data synchronization
refers to That is, when the slave connects to msater for the first time, the full copy is performed. In that process, you have some detailed mechanisms
(1) Both the master and the slave will maintain an offset
The master will continuously accumulate offsets on itself, and the slave will also continuously accumulate offsets on itself
The slave will report its own offset to the master every second, and the master will also save each The offset of each slave
This does not mean that it is specifically used for full replication. The main reason is that both the master and the slave need to know the offset of their own data to know that the data between them is inconsistent. Situation
(2) backlog
The master node has a backlog, the default size is 1MB
master When the node copies data to the slave node, it will also write a copy of the data synchronously in the backlog
The backlog is mainly used for incremental copying when full replication is interrupted
(3) master run id
Info server, you can see the master run id
If you locate the master node based on the host ip, yes It’s unreliable. If the master node restarts or the data changes, the slave node should be distinguished according to different run ids. If the run ids are different, make a full copy
If you need to restart redis without changing the run id , you can use the redis-cli debug reload command
(4) psync
The slave node uses psync to copy from the master node, psync runid offset
The master node will return response information according to its own situation. It may be FULLRESYNC runid offset that triggers full copy, or CONTINUE that triggers incremental copy
Full copy
The master executes bgsave and generates an rdb snapshot file locally.
The master node sends the rdb snapshot file to the salve node. If the rdb copy time exceeds 60 seconds (repl-timeout) , then the slave node will think that the copy has failed, and you can adjust this parameter appropriately
For machines with Gigabit network cards, generally 100MB, 6G files are transferred per second, which is likely to exceed 60s
When the master node generates the rdb, it will cache all new write commands in the memory. After the salve node saves the rdb, it will copy the new write commands to the salve node
client-output-buffer-limit slave 256MB 64MB 60. If during replication, the memory buffer continues to consume more than 64MB, or exceeds 256MB at one time, then the replication will stop and the replication will fail.
The slave node receives After rdb, clear its own old data, then reload rdb into its own memory, and at the same time provide external services based on the old data version
If the slave node turns on AOF, then BGREWRITEAOF will be executed immediately. Rewrite AOF
Incremental copy
If the full copy is in progress, master- If the slave network connection is disconnected, then when the slave reconnects to the master, incremental replication will be triggered
The master directly obtains part of the lost data from its own backlog and sends it to the slave node. The default backlog is 1MB
msater is to obtain data from the backlog based on the offset in psync sent by the slave
heartbeat
The master and slave nodes will send heartbeat information to each other
The master sends a heartbeat every 10 seconds by default, and the salve node sends a heartbeat every 1 second
Asynchronous replication
Each time the master receives a write command, it now writes data internally and then sends it asynchronously to the slave node
The above is the detailed content of Do you know how to ensure high concurrency of Redis?. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis










![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



