


The main bottleneck of the cluster is: disk. When we face a swarm operation, what we want is to read it immediately. But in the face of big data, reading data requires disk IO. Here IO can be understood as a water pipe. The larger and stronger the pipeline, the faster we can read T-level data. Therefore, the quality of IO directly affects the cluster's data processing.

#There are many opinions on the bottleneck of the cluster, among which network and disk io are more controversial. What needs to be explained here is that thenetwork is a scarce resource, not a bottleneck.
For disk IO: (Disk IO: Disk output output)
When we face cluster operations, what we want is immediate readability. But in the face of big data, reading data requires IO. Here IO can be understood as a water pipe. The larger and stronger the pipeline, the faster we can read T-level data. Therefore, the quality of IO directly affects the cluster's data processing.
Here are a few examples for your reference.
Case 1
Since using Alibaba Cloud, we have encountered three failures (one, two, and three). These three failures are all related to high disk IO.
The first failure occurred in the cloud running the zzk.cnblogs.com indexing service On the server, the Avg.Disk Read Queue Length is as high as more than 200;
The second failure occurred on the cloud server running images.cnblogs.com static files. At that time, Avg.Disk Read Queue Length is about 2 (later analysis, for applications such as picture sites that directly read files and respond, Disk Read Queue Length reaching this value will significantly affect the response speed);
The third failure occurred on the cloud server running the database service. At that time, Avg. Disk Write Queue Length reaches 4~5, causing many database write operations to time out.
(Here we mention both "hard disk" and "disk". We define it this way: the hard disk seen in the cloud server is called a disk [virtual hard disk], and the physical hard disk in the cluster is Called hard disk)
These three times of high disk IO were not caused by the applications in our cloud server. The most direct evidence is that after migrating the cloud service to another cluster, the problem was solved immediately. In other words, the cloud server’s disk IO is high because The hard disk IO of the cluster where it is located is high.
The hard disk IO of the cluster is the accumulation of the disk IO of all cloud servers in the cluster. The high hard disk IO of the cluster is because the disk IO of some cloud servers in the cluster is too high. And we since The disk IO generated by the applications in our cloud server is within the normal range. The problem is that other users' cloud servers generate too much disk IO, causing the entire cluster hard disk IO to be high, thus affecting us.
Why do hard disk IO problems caused by other cloud servers affect us? The root of the problem is that the hard disk IO of the cluster is shared by all cloud servers in the cluster, and this sharing is not effectively restricted or Being effectively isolated, everyone is competing for this resource. If there are too many people competing for it at the same time, there will be long queues.
And for each cloud server, I don’t know how many cloud servers are competing for it. From the perspective of cloud server users, There is no way to avoid this competition; just like during the World Expo, no matter how early you get up to queue up, you will still have to wait in an extremely long queue.
If the hard disk IO resources used by each cloud server are restricted or isolated, other cloud servers will Excessive disk IO will not affect our cloud servers; just like in a community, if you rent a house by yourself, even if 100 people live in another house, it will not affect you.
You can buyCPU, memory, bandwidth, and hard disk space, but you can’t buy hard disk IO that serves you wholeheartedly.This is the current Alibaba Cloud Virtualization An important issue that was not considered when designing the platform.
After communicating with Alibaba Cloud technical staff, I learned that they are aware of this problem and hope that this problem can be solved as soon as possible.
-------------------------------------------------- -------------------------------------------------- -------------------------------------
Case 2
The Road to Cloud Computing - After Moving to Alibaba Cloud: 20130314 Cloud Server Failure
First of all, I would like to apologize to everyone. This cloud server failure was discovered around 17:30. It returns to normal around 18:30, which has caused trouble to everyone. Please forgive me!
The cause of the failure was that the cluster load of the cloud server was too high, and the disk writing performance dropped sharply, causing many database write operations to time out. The solution that later returned to normal was to migrate the cloud server to another cluster.
The following is the main process of the failure:
At around 9:15 this morning, a gardener reported via email that he encountered a 502 Bad Gateway error when visiting the garden.
This is an error returned by Alibaba Cloud Load Balancer, Tegine is an open source web server developed by Alibaba. We speculate that the load balancing service provided by Alibaba Cloud may be implemented through Tegine reverse proxy.
This error page indicates that the load balancer detected that the cloud server in the load balancing returned an invalid response, such as a 500 series error.
We reported this situation to Alibaba Cloud through a work order, and the feedback we received was to continue to observe. It may be caused by a temporary problem with the user's network line.
Since we have not encountered this problem during this time period, and no other users have reported this problem, we have also approved the handling method of continuing to observe.
(According to our later analysis, the occurrence of 502 Bad Gateway error may be caused by a high instantaneous load on the cluster)
At around 17:20 pm, we ourselves also encountered a 502 Bad Gateway error , lasted about 1-2 minutes. See the picture below: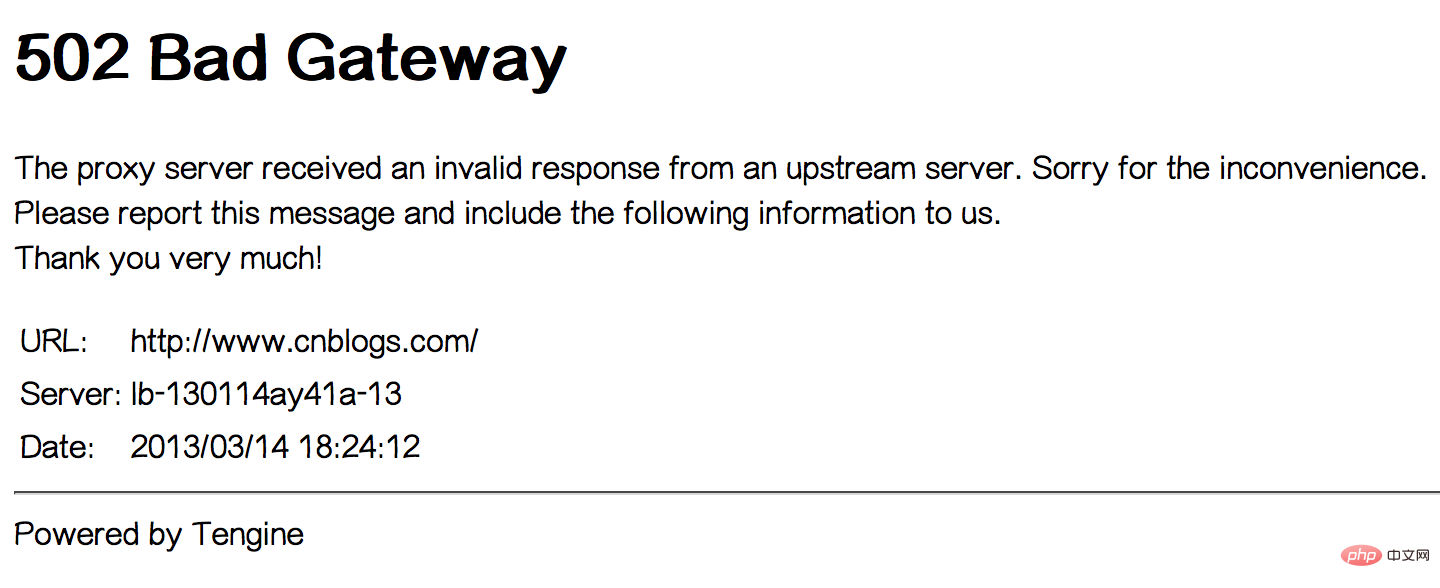
During the problem, we quickly logged in to the two cloud servers to check the situation and found that the number of concurrent IIS connections increased to more than 30 times, while Bytes Send/sec is 0, and the situation is the same on both cloud servers. We concluded at that time that there should be no problem with the two cloud servers themselves. The problem may lie in the network communication between them and the database server. letter. We will continue to report this situation to Alibaba Cloud through work orders.
As soon as we filled out the work order, we received a call from a garden friend saying that the blog backend could not publish articles. When we tested it, it was indeed impossible to publish, and a database timeout error was reported, as shown in the picture below:
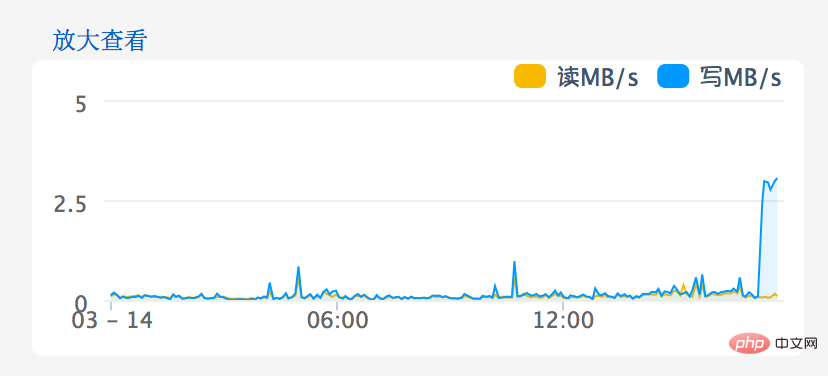
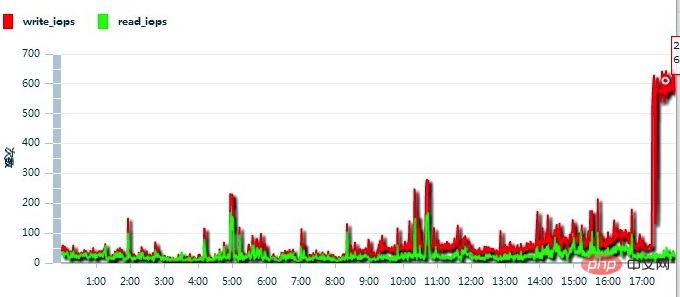
Butopening existing articles is very fast, which means reading is normal but writing is problematic. Quickly log in to the database server and check the disk IO status through the performance monitor. Sure enough, there is a problem with the disk write performance, see the picture below: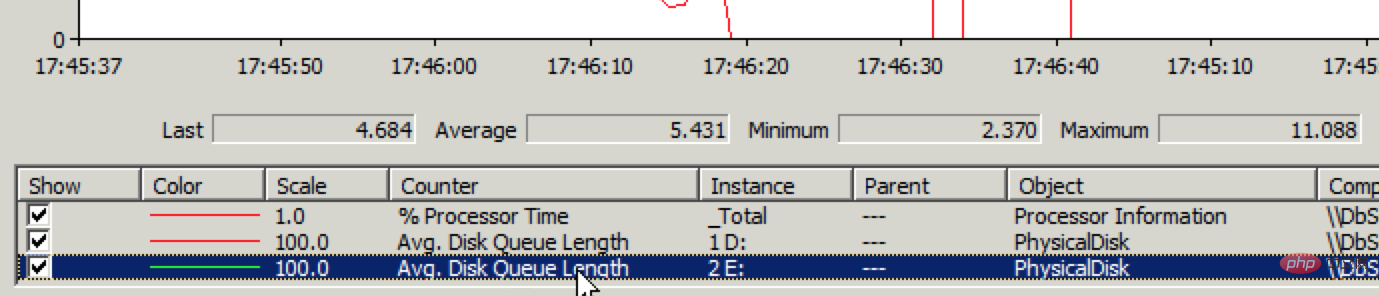

-------------------------------------------------- -------------------------------------------------- ---------------------------------------
Case 3

This is a database write timeout error. We still remember this error message. I have encountered this twice before (March 14th and April 2nd), both caused by disk IO problems on the cloud server where the database server is located.
14:19, we submitted a work order to Alibaba Cloud, specifically adding "urgent" in the title;
14:42, there was no further news from Alibaba Cloud customer service, so we replied that "if it cannot be solved in a short time, we hope to carry out cluster migration as soon as possible" (this problem was solved through cluster migration on March 14, Alibaba Cloud's Technical staff also said that for disk IO problems caused by high cluster load, the only solution at present is cluster migration);
14:47, Alibaba Cloud customer service only replied that it is being processed;
At 14:59, there was still no news. We were very anxious (40 minutes had passed and there was no explanation). We asked in the work order: "Can we do cluster migration first?";
Then, we received the call from Ali The cloud customer service called us and said that the high disk IO occupied by other cloud servers in the cluster affected us, and they were dealing with it. . .
After a while, Alibaba Cloud customer service called again and said that it might be the system or application in our cloud server that caused the server disk write to become stuck. Let us restart the cloud server. (This consideration may be because the cluster load has dropped at this time, but our cloud server disk IO is still high.)
Around 15:23, we restarted the database server, but the problem remained.
15:30, Alibaba Cloud customer service finally decided to migrate the cluster (it took 1 hour and 10 minutes from submitting the work order to deciding on cluster migration)
15:45, the cluster migration was completed (last time The migration took less than 5 minutes, this time it took 15 minutes, which is also the longest time required for cluster migration according to Alibaba Cloud customer service)
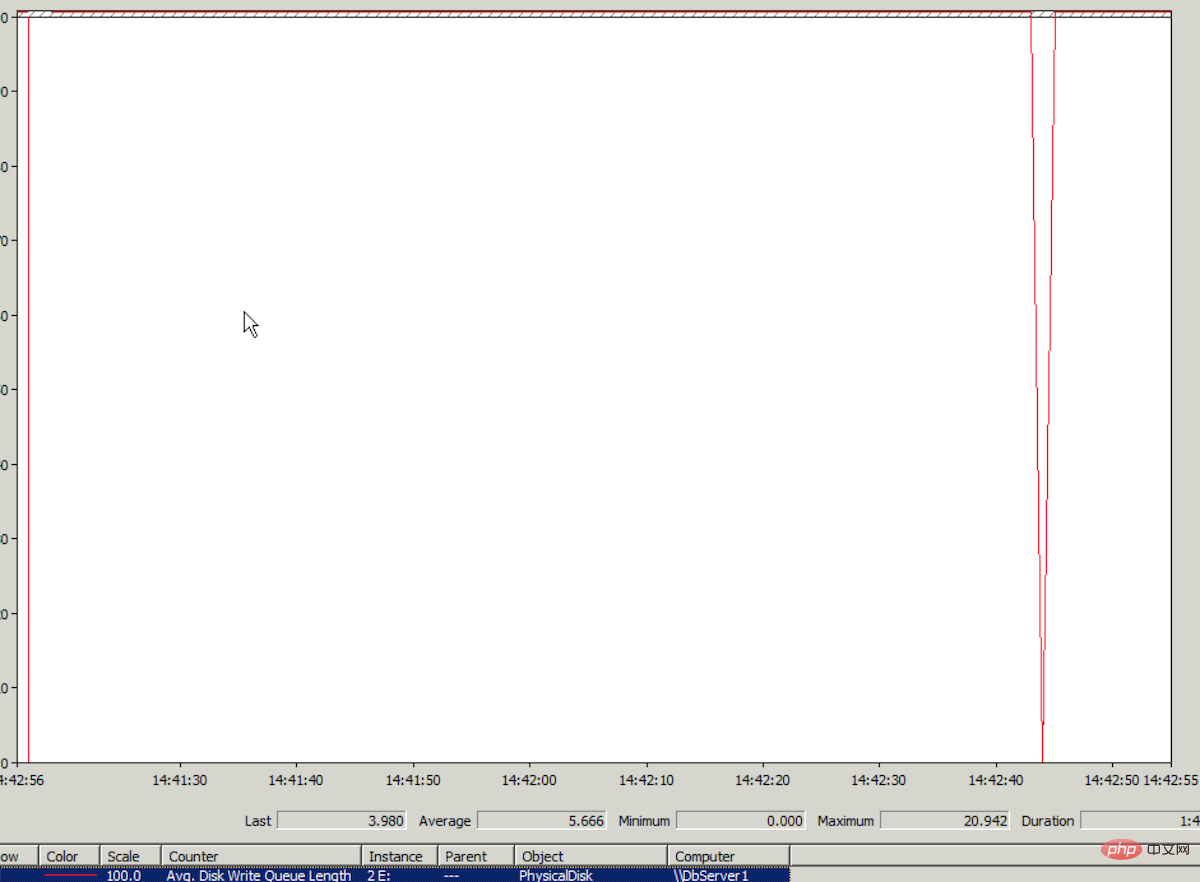
After the migration, I was dumbfounded. Disk IO (Avg.Disk Write Queue Length) is still so high!
Why can’t this cluster migration solve the problem immediately like last time? We guess there are two possible reasons:
1. The cluster disk IO load is still high after migration;
2. The partition with high disk IO on the cloud server contains database log files. Maybe log writing operations are more frequent than usual during this period (but a surge is almost impossible) and all log files are in the same partition. area, exceeding a certain limit of the cloud server's disk IO, causing the disk IO performance to drop sharply (the possibility is relatively high, based on the road to cloud computing - After entering Alibaba Cloud: Solve images.cnblogs.com Weird problem with slow response speed). Although when using a physical server before, the log files were placed in the same partition and this problem never occurred, but now the disk IO capability of the cloud server cannot be compared with that of the physical server. ratio, and the disk IO will be competed by other cloud servers on the cluster (for details, see the road to cloud computing - after moving to Alibaba Cloud: the root of the problem - buying her "people", but not her "heart" ).
No matter which reason it is, there is only one and the last resort to solve the problem - reduce the IO pressure on the disk partition where the log file is located.
How to reduce stress? According to the "Small Recipes to Improve Overall Disk IO Performance" in the article "Some Experiences after Moving to Alibaba Cloud", purchase another piece of disk space, and then write the database CNBlogsText (large text data) that stores blog content, which will cause disk IO (high pressure) log files to a separate disk partition.
In SQL Server, moving database log files from one disk partition to another cannot be done online. You need to detach the database first, then copy the log file to the target partition, and then attach the database; when attaching, change the location of the log file to a new path.
So, with no choice, our CNBlogsText database performed a detach operation and chose to drop connections. Unexpectedly, tragedy happened during the detach process. The detach failed and the error was:
Transaction (Process ID 124) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
在 A deadlock occurred during the detach process, and then it was "sacrificed". What is confusing is that if connections are not dropped, how can a deadlock still occur? May drop connections is before the detach operation officially starts. During the detach process, a database write operation will also occur. The write operation at this time triggers a deadlock. why Why should detach be sacrificed? Unconscionable.
After detach fails, the CNBlogsText database is in the Single User state. Continue detach, same error, same "sacrificed".
So, restarted the SQL Server service. After restarting, the status of the CNBlogsText database changes to In Recovery.
The time has reached 16:45.
I have never encountered such an In Recovery state before, I don’t know how to deal with it, and I don’t dare to act rashly.
After a while, I refreshed the Databases list of SQL Server, and the CNBlogsText database was displayed in the previous Single User state. (It turns out that after restarting SQL Server, it will automatically enter the In Recovery state first, and then enter the Single User state)
Regarding the Single User status problem, I consulted Alibaba Cloud customer service in the work order, and Alibaba Cloud customer service contacted the database The engineer was advised to perform the following operation: alter database $db_name SET multi_user
So, the following SQL was executed:
exec sp_dboption 'CNBlogsText', N'single', N'false'
An error message appeared:
Database 'CNBlogsText' is already open and can only have one user at a time.
Single The User status remains. This error may occur because the database is constantly having write operations, preempting only the only database connection allowed in the Single User status.
(更新:后来从阿里云DBA那学习到解决这个问题的方法:
select spid from sys.sysprocesses where dbid=DB_ID('dbname'); --得到当前占用数据库的进程id kill [spid] go alter login [username] disable --禁用新的访问 go use cnblogstext go alter database cnblogstext set multi_user with rollback immediate go
)
当时的情形下,我们不够冷静,急着想完成detach操作。觉得屏蔽CNBlogsText数据库的所有写入操作可能需要禁止这台服务器的所有数据库连接,这样会影响整站的正常访问,所以没从这个角度下手。
这时时间已经到了17:08。
我们也准备了最最后一招,假如实在detach不了,假如日志文件也出了问题,我们可以通过数据文件恢复这个数据库。这个场景我们遇到过,也实际成功操作过,详见:SQL Server 2005数据库日志文件损坏的情况下如何恢复数据库。所需的SQL语句如下:
use master alter database dbname set emergency declare @databasename varchar(255) set @databasename='dbname' exec sp_dboption @databasename, N'single', N'true' --将目标数据库置为单用户状态 dbcc checkdb(@databasename,REPAIR_ALLOW_DATA_LOSS) dbcc checkdb(@databasename,REPAIR_REBUILD) exec sp_dboption @databasename, N'single', N'false'--将目标数据库置为多用户状态
即使最最后一招也失败了,我们在另外一台云服务器上有备份,在异地也有备份,都有办法恢复,只不过需要的恢复时间更长一些。
想到这些,内心平静了一些,认识到当前最重要的是抛开内疚、紧张、着急,冷静面对。
我们在工单中继续咨询阿里云客服,阿里云客服联系了数据库工程师,让我们加一下这位工程师的阿里旺旺。
我们的电脑上没装阿里旺旺,于是打算自己再试试,如果还是解决不了,再求助阿里云的数据库工程师。
在网上找了一个方法:SET DEADLOCK_PRIORITY NORMAL(来源),没有效果。
时间已经到了17:38。
这时,我们冷静地分析一下:detach时,因为死锁“被牺牲”;从单用户改为多用户时,提示“Database 'CNBlogsText' is already open and can only have one user at a time.”。可能都是因为程序中不断地对这个数据库有写入操作。试试修改一下程序,看看能不能屏蔽所有对这个数据库的写入操作,然后再将数据库恢复为多 用户状态。
修改好程序,18:00之后进行了更新。没想到更新之后,将单用户改为多用户的SQL就能执行了:
exec sp_dboption 'CNBlogsText', N'single', N'false'
于是,Single User状态消失,CNBlogsText数据库恢复了正常状态,然后尝试detach,一次成功。
接着将日志文件复制到新购的磁盘分区中,以新的日志路径attach数据库。attach成功之后,CNBlogsText数据库恢复正常,博客后台可以正常发布博文,CNBlogsText数据库日志文件所在分区的磁盘IO(单独的磁盘分区)也正常。问题就这么解决了。
当全部恢复正常,如释重负的时候,时间已经到了18:35。
原以为可以用更多的内存弥补云服务器磁盘IO性能低的不足。但万万没想到,云服务器的硬伤不是在磁盘IO性能低,而是在磁盘IO不稳定。
更多相关知识,请访问:PHP中文网!
The above is the detailed content of What is the main bottleneck of the cluster?. For more information, please follow other related articles on the PHP Chinese website!

































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



