


Analyze common factors that affect http performance

The main content of this article is to introduce the common factors that affect HTTP performance. It has certain reference value. Interested friends can learn about it.
The HTTP performance we discuss here is based on the simplest model, which is the HTTP performance of a single server. Of course, it is also applicable to large-scale load balancing clusters. After all, this cluster is also composed of multiple HTTP servers. composition. In addition, we also exclude that the load on the client or server itself is too high or that the software implementing the HTTP protocol uses different IO models. In addition, we also ignore defects in the DNS resolution process and web application development itself.
From the perspective of the TCP/IP model, the lower layer of HTTP is the TCP layer, so the performance of HTTP depends largely on the performance of TCP. Of course, if it is HTTPS, the TLS/SSL layer must be added, but it can It is certain that the performance of HTTPS is definitely worse than that of HTTP. The communication process will not be discussed here. In short, the more layers there are, the more serious the performance loss will be.
Under the above conditions, the most common factors that affect HTTP performance include:
TCP connection establishment, which is the three-way handshake phase
-
TCP slow start
TCP delayed confirmation
Nagle algorithm
TIME_WAIT accumulation and Port exhausted
Server port exhausted
The number of files opened by the server HTTP process reached the maximum
TCP connection establishment
Usually if the network is stable, TCP connection establishment will not take a lot of time and will complete the three-way handshake process within a reasonable time-consuming range. However, since HTTP is stateless and belongs to a short connection, once After the HTTP session is accepted, the TCP connection will be disconnected. A web page usually has many resources, which means that there will be many HTTP sessions. Compared with the HTTP session, the TCP three-way handshake to establish the connection will be too time-consuming. Of course, you can use Reuse existing connections to reduce the number of TCP connection establishment times.
TCP slow start
TCP congestion control method1, in the initial transmission stage after TCP is established, the maximum transmission speed of the connection will be limited. If the data transmission is successful, The transmission speed will be gradually increased in the future, which is called TCP slow start. Slow start limits the number of IP packets2 that can be transmitted at a certain time. So why is there slow start? The main purpose is to prevent the network from being paralyzed due to large-scale data transmission. A very important link in data transmission on the Internet is the router, and the router itself is not fast. In addition, a lot of traffic on the Internet may be sent over and require it to be routed and forwarded. If the amount of data arriving at the router in a certain period of time is much greater than the amount it sends, the router will discard the data packets when the local cache is exhausted. This discarding behavior is called congestion. If a router encounters this situation, it will It affects many links and can lead to widespread paralysis in severe cases. Therefore, any party in TCP communication needs to perform congestion control, and slow start is one of the algorithms or mechanisms of congestion control.
You imagine a situation. We know that TCP has a retransmission mechanism. Assume that a router in the network experiences large-scale packet loss due to congestion. As the sender of data, its TCP protocol stack will definitely detect this situation. Then it will start the TCP retransmission mechanism, and the sender affected by this router must be more than just you. Then a large number of sender TCP protocol stacks have started retransmitting, which is equivalent to sending more data on the originally congested network. Bao, this is tantamount to adding fuel to the fire.
Through the above description, it can be concluded that even in a normal network environment, as the sender of HTTP messages and each request to establish a TCP connection will be affected by slow start, then according to HTTP is a short connection one session It will be disconnected when it is finished. You can imagine that the client initiated an HTTP request and just obtained a resource on the web page, and the HTTP was disconnected. It is possible that the TCP connection was disconnected before the TCP slow start process was completed. Then the other web pages Subsequent resources will continue to establish TCP connections, and each TCP connection will have a slow start phase. This performance can be imagined, so in order to improve performance, we can enable HTTP persistent connections, which is the keepalive mentioned later.
In addition, we know that there is the concept of a window in TCP. This window exists on both the sender and the receiver. The role of the window ensures that the sender and receiver become orderly when managing the packet; on the other hand, when there is Multiple packets can be sent on the basis of sequence, thereby improving throughput; another point is that the window size can be adjusted, the purpose is to prevent the sender from sending data faster than the receiver can receive it. Although the window solves the problem of double-sending communication speed, other network devices will pass through the network. How does the sender know the receiving capability of the router? So there is the congestion control introduced above.
TCP Delayed Confirmation
First of all, you must know what a confirmation is. It means that the sender sends a TCP segment to the receiver. After receiving it, the receiver must send back a confirmation to indicate receipt. , if the sender does not receive the confirmation within a certain period of time, the TCP segment needs to be resent.
Confirmation messages are usually relatively small, that is, one IP group can carry multiple confirmation messages, so in order to avoid sending too many small messages, the receiver will wait and see when sending back the confirmation message. Is there any other data sent to the receiver? If so, put the confirmation message and the data together in a TCP segment and send it over. If there is no other data that needs to be sent within a certain period of time, usually 100-200 milliseconds, then Send the confirmation message in a separate packet. In fact, the purpose of doing this is to reduce the network burden as much as possible.
A common example is logistics. The load capacity of a truck is certain. If it has a load capacity of 10 tons, and you are going from city A to city B, you definitely want it to be as full as possible instead of coming. With a small package, you immediately get up and drive to city B.
So TCP is not designed to immediately return an ACK confirmation when a data packet comes. It usually accumulates in the cache for a period of time. If there is still data in the same direction, it will send back the previous ACK confirmation. But you can't wait too long, otherwise the other party will think that the packet has been lost and trigger a retransmission from the other party.
Different operating systems will have different opinions on whether and how to use delayed confirmation. For example, Linux can be enabled or disabled. Disabling it means confirming each one as it comes. This is also the fast confirmation mode.
It should be noted that whether it is enabled or how many milliseconds to set depends on the scenario. For example, in online gaming scenarios, confirmation must be done as soon as possible, and delayed confirmation can be used for SSH sessions.
For HTTP we can turn off or adjust TCP delayed confirmation.
Nagle algorithm
This algorithm is actually designed to improve IP packet utilization and reduce network burden. It still involves small packets and full-size packets (according to Ethernet standards MTU is 1500 bytes per message, and any message less than 1500 is considered a non-full-size message), but no matter how small the small message is, it will not be less than 40 bytes, because the IP header and TCP header each occupy 20 bytes . If you send a small message of 50 bytes, it actually means that there is too little valid data. Just like delayed acknowledgment, small-size packets are not a big problem in the LAN, but mainly affect the WAN.
This algorithm is actually that if the sender has sent a message in the current TCP connection but has not yet received a confirmation, then if the sender still has small messages to send, it cannot send them. It is to be placed in the buffer to wait for the confirmation of the previously sent message. After receiving the confirmation, the sender will collect the small messages in the same direction in the cache and assemble them into one message for sending. In fact, this means that the faster the receiver returns ACK confirmation, the faster the sender can send data.
Now let’s talk about the problems that the combination of delayed confirmation and Nagle’s algorithm will bring. In fact, it is easy to see that because of delayed confirmation, the receiver will accumulate ACK confirmations for a period of time, and the sender will not continue to send the remaining non-full-size data if it does not receive ACK during this period. Packets (the data is divided into multiple IP packets. The number of response data packets to be sent by the sender cannot be an integral multiple of 1500. There is a high probability that some data at the end of the data is small-sized IP packets), so you can see The contradiction here is that this kind of problem will affect the transmission performance in TCP transmission. Then HTTP depends on TCP, so it will naturally affect HTTP performance. Usually we will disable the algorithm on the server side. We can disable it on the operating system or in HTTP Set TCP_NODELAY in the program to disable this algorithm. For example, in Nginx you can use tcp_nodelay on; to disable it.
TIME_WAIT accumulation and port exhaustion3
This refers to the party that is the client or the party that actively closes the TCP connection, although the server can also take the initiative Initiate closing, but what we are discussing here is HTTP performance. Due to the characteristics of HTTP connections, the client usually initiates active closing.
The client initiates an HTTP request (here we are talking about a specific resource request instead of opening a so-called homepage. A homepage has N resources, so N HTTP requests will be initiated.) After this request is completed, the TCP connection will be disconnected, and the TCP status of the connection on the client will appear. A state called TIME_WAIT. From this state to the final shutdown, it usually takes 2MSL4. We know that when the client accesses the HTTP service of the server, it will use its own random high-bit port to connect to the server's 80 or 443 port to establish HTTP communication (its essence is TCP communication), which means that the number of available ports on the client will be consumed. Although the client disconnects, this random port will be released. However, after the client actively disconnects, the TCP status During the 2MSL period between TIME_WAIT and actual CLOSED, the random port will not be used (if the client initiates HTTP access to the same server again). One of its purposes is to prevent dirty data on the same TCP socket. . From the above conclusion, we know that if the client's HTTP access to the server is too intensive, the port usage speed may be higher than the port release speed, which will eventually lead to the failure to establish a connection because there is no available random port.
We said above that usually the client actively closes the connection,
TCP/IP Detailed Explanation Volume 1 Second Edition, P442, the last paragraph writes that for interactive applications, the client usually performs an active shutdown operation and enters the TIME_WAIT state, and the server usually performs a passive shutdown operation and It will not directly enter the TIME_WAIT state.
However, if the web server has keep-alive enabled, the server will automatically shut down when the timeout is reached. (I am not saying that the detailed explanation of TCP/IP is wrong here, but it is mainly for TCP in that section, and does not introduce HTTP, and it says usually rather than necessarily)
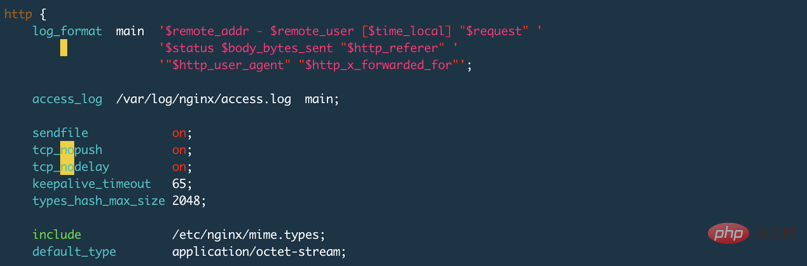
I use Nginx did a test and set keepalive_timeout 65s; in the configuration file. The default setting of Nginx is 75s. Setting it to 0 means disabling keepalive, as shown below:
Below I use the Chrom browser to access the homepage provided by Nginx by default, and monitor the entire communication process through the packet capture program, as shown below:
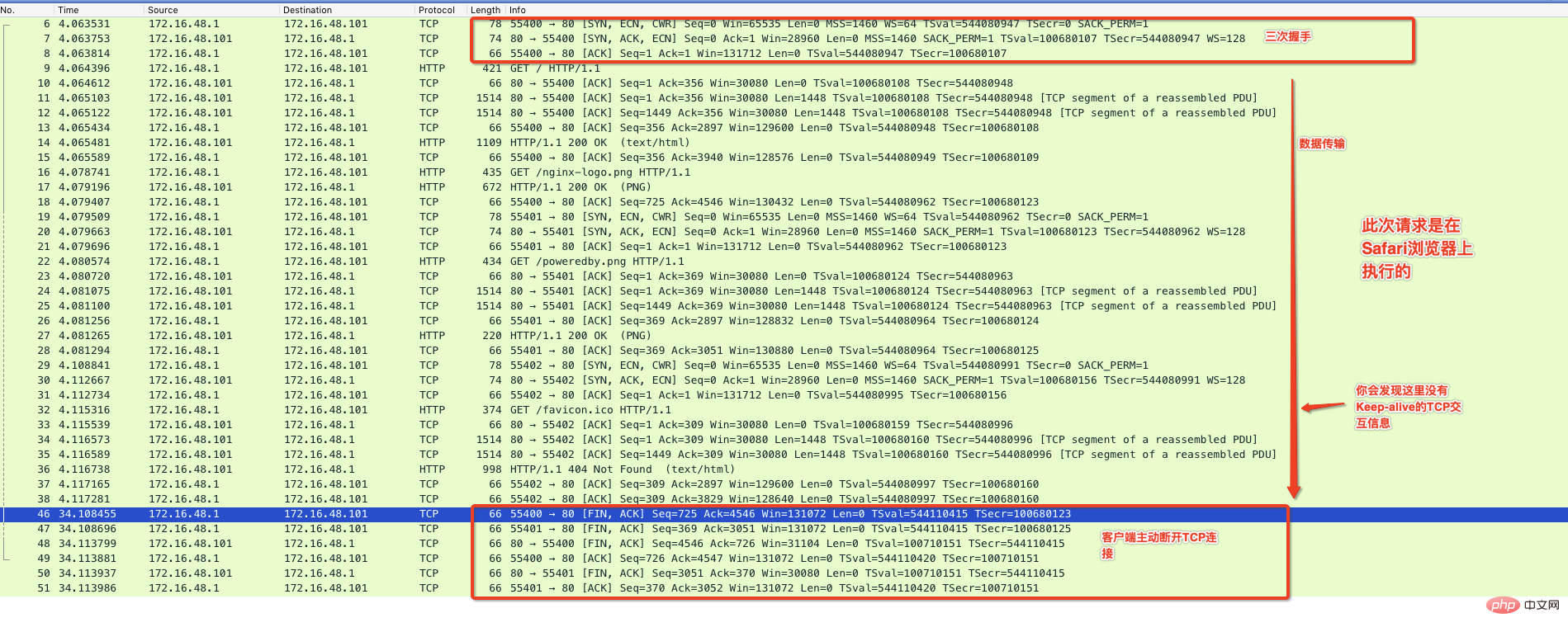
From the above picture you can It can be seen that after the effective data transmission is completed, the Keep-Alive marked communication appears in the middle, and the server actively disconnects after there is no request within 65 seconds. In this case, you will see the TIME_WAIT status on the Nginx server.
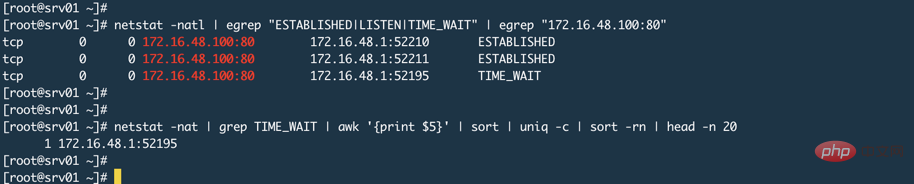
Server port exhausted
Some people say that Nginx listens to 80 or 443. The client always connects to this port. How can the server end the port? Just like the picture below (ignoring TIME_WAIT in the picture, the reason for this has been mentioned above and is caused by Nginx's keepalive_timeout setting)
In fact, it depends Nginx working mode, when we use Nginx, we usually make it work in proxy mode, which means that the real resources or data are on the back-end web application, such as Tomcat. The characteristic of the proxy mode is that the proxy server goes to the backend to obtain data on behalf of the user. At this time, compared to the backend server, Nginx is a client. At this time, Nginx will use a random port to initiate a request to the backend, and the system is available The random port range is certain. You can use the sysctl net.ipv4.ip_local_port_range command to view the random port range on the server.
Through the delayed confirmation, Nagle algorithm and proxy mode we introduced before, Nginx acts as the client of the backend and uses a random port to connect to the backend, which means that the risk of port exhaustion on the server side exists. Random port release speed may occur if it is slower than the speed of establishing a connection with the backend. However, this situation generally does not occur. At least I have not found this phenomenon in our company's Nginx. Because first of all, static resources are on CDN; secondly, most of the backend uses REST interfaces to provide user authentication or database operations. In fact, these operations are basically very fast if there are no bottlenecks on the backend. But having said that, if the backend really has a bottleneck and the cost of expanding or changing the architecture is relatively high, then what you should do when facing a large amount of concurrency is to limit the flow to prevent the backend from being killed.
The number of files opened by the server-side HTTP process reaches the maximum
We have said that HTTP communication relies on TCP connections. A TCP connection is a socket. For Unix-like systems, opening a socket The word is to open a file. If there are 100 requests to connect to the server, then the server will open 100 files once the connection is established successfully. However, the number of files that can be opened by a process in the Linux system is limitedulimit -f, so if this value is set too small, it will also affect the HTTP connection. For Nginx or other HTTP programs running in proxy mode, usually one connection will open two sockets and occupy two files (except when it hits the Nginx local cache or Nginx returns data directly). Therefore, the number of files that can be opened by the proxy server process must also be set larger.
Persistent Connection Keepalive
First of all, we need to know that keepalive can be set on two levels, and the two levels have different meanings. TCP's keepalive is a detection mechanism. For example, the heartbeat information we often say indicates that the other party is still online. This heartbeat information is sent with a time interval, which means that the TCP connection between each other must always remain open; Keep-alive in HTTP is a mechanism for reusing TCP connections to avoid frequent establishment of TCP connections. So you must understand that TCP Keepalive and HTTP Keep-alive are not the same thing.
HTTP keep-alive mechanism
Non-persistent connections will disconnect the TCP connection after each HTTP transaction is completed, and the next HTTP transaction will re-establish the TCP connection. This is obviously not a problem. This is an efficient mechanism, so in the enhanced version of HTTP/1.1 and HTTP/1.0, HTTP is allowed to keep the TCP connection open after the transaction ends, so that subsequent HTTP transactions can reuse the connection until the client or server actively closes the connection. . Persistent connections reduce the number of TCP connection establishments and also minimize the traffic restrictions caused by TCP slow start.
Related tutorials: HTTP video tutorial

Look at this picture again, the keepalive_timeout 65s in the picture is set Turn on the keep-alive feature of http and set the timeout to 65 seconds. In fact, another more important option is keepalive_requests 100;It indicates the maximum number of HTTP requests that can be initiated by the same TCP connection. The default is 100 indivual.
Keep-alive is not used by default in HTTP/1.0. The client must send an HTTP request with the header Connection: Keep-alive to try to activate keep-alive. If If the server does not support it, it will not be used. All requests will be made in the normal form. If the server supports it, the response header will also include Connection: Keep-alive information.
Keep-alive is used by default in HTTP/1.1. Unless otherwise specified, all connections are persistent. If you want to close the connection after a transaction ends, the HTTP response header must contain the Connection: CLose header, otherwise the connection will always remain open. Of course, it cannot always be open, and idle connections must also be closed. , just like the Nginx setting above, the idle connection can be maintained for up to 65 seconds. After that, the server will actively disconnect the connection.
TCP keepalive
There is no unified switch on Linux to turn on or off the TCP keepalive function. Check the system keepalive settingssysctl -a | grep tcp_keepalive, If you have not modified it, it will display on the Centos system:
net.ipv4.tcp_keepalive_intvl = 75 # 两次探测直接间隔多少秒 net.ipv4.tcp_keepalive_probes = 9 # 探测频率 net.ipv4.tcp_keepalive_time = 7200 # 表示多长时间进行一次探测,单位秒,这里也就是2小时
According to the default settings, the overall meaning of the above is to detect once every 2 hours. If the first detection fails, then detect again after 75 seconds. Once, if it fails 9 times, it will actively disconnect.
How to enable Keepalive at the TCP level on Nginx. There is a statement in Nginx called listen. It is a statement in the server section that is used to set the port on which Nginx listens. In fact, it is followed by There are other parameters used to set socket properties. See the following settings:
# 表示开启,TCP的keepalive参数使用系统默认的 listen 80 default_server so_keepalive=on; # 表示显式关闭TCP的keepalive listen 80 default_server so_keepalive=off; # 表示开启,设置30分钟探测一次,探测间隔使用系统默认设置,总共探测10次,这里的设 # 置将会覆盖上面系统默认设置 listen 80 default_server so_keepalive=30m::10;
So whether to set this so_keepalive on Nginx depends on the specific scenario. Do not combine TCP keepalive and HTTP Keepalive is confusing, because Nginx does not enable so_keepalive and it does not affect the use of the keep-alive feature in your HTTP requests. If there is a load balancing device between the client and Nginx directly or between Nginx and the backend server and responses and requests will pass through this load balancing device, then you should pay attention to this so_keepalive. For example, it will not be affected in the direct routing mode of LVS because the response does not go through
LVS. However, if it is in NAT mode, you need to pay attention because LVS also has a duration to maintain the TCP session. If the duration is less than the duration of the backend to return data, then LVS will disconnect the TCP connection before the client receives the data.
TCP congestion control has some algorithms, including TCP slow start, congestion avoidance and other algorithms ↩
Some It is also called IP fragmentation but it all means the same thing. As for why fragmentation is simply limited by the data link layer, different data links have different MTUs. Ethernet’s is 1500 bytes. In some scenarios, it will It is 1492 bytes; the MTU of FDDI is another size. Simply considering the IP layer, the maximum IP data packet is 65535 bytes ↩
In the "HTTP Authoritative Guide" page P90 It is not made very clear whether this situation is relative to the client or the server, because it is very likely to be misunderstood. Of course, it does not mean that the server will not run out of ports, so I added it here. 2 items of content ↩
The maximum length shall not exceed 2 minutes ↩
The above is the detailed content of Analyze common factors that affect http performance. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 Performance analysis of Kirin 8000 and Snapdragon processors: detailed comparison of strengths and weaknesses
Mar 24, 2024 pm 06:09 PM
Performance analysis of Kirin 8000 and Snapdragon processors: detailed comparison of strengths and weaknesses
Mar 24, 2024 pm 06:09 PM
Kirin 8000 and Snapdragon processor performance analysis: detailed comparison of strengths and weaknesses. With the popularity of smartphones and their increasing functionality, processors, as the core components of mobile phones, have also attracted much attention. One of the most common and excellent processor brands currently on the market is Huawei's Kirin series and Qualcomm's Snapdragon series. This article will focus on the performance analysis of Kirin 8000 and Snapdragon processors, and explore the comparison of the strengths and weaknesses of the two in various aspects. First, let’s take a look at the Kirin 8000 processor. As Huawei’s latest flagship processor, Kirin 8000
 Understand common application scenarios of web page redirection and understand the HTTP 301 status code
Feb 18, 2024 pm 08:41 PM
Understand common application scenarios of web page redirection and understand the HTTP 301 status code
Feb 18, 2024 pm 08:41 PM
Understand the meaning of HTTP 301 status code: common application scenarios of web page redirection. With the rapid development of the Internet, people's requirements for web page interaction are becoming higher and higher. In the field of web design, web page redirection is a common and important technology, implemented through the HTTP 301 status code. This article will explore the meaning of HTTP 301 status code and common application scenarios in web page redirection. HTTP301 status code refers to permanent redirect (PermanentRedirect). When the server receives the client's
 Performance comparison: speed and efficiency of Go language and C language
Mar 10, 2024 pm 02:30 PM
Performance comparison: speed and efficiency of Go language and C language
Mar 10, 2024 pm 02:30 PM
Performance comparison: speed and efficiency of Go language and C language In the field of computer programming, performance has always been an important indicator that developers pay attention to. When choosing a programming language, developers usually focus on its speed and efficiency. Go language and C language, as two popular programming languages, are widely used for system-level programming and high-performance applications. This article will compare the performance of Go language and C language in terms of speed and efficiency, and demonstrate the differences between them through specific code examples. First, let's take a look at the overview of Go language and C language. Go language is developed by G
 HTTP 200 OK: Understand the meaning and purpose of a successful response
Dec 26, 2023 am 10:25 AM
HTTP 200 OK: Understand the meaning and purpose of a successful response
Dec 26, 2023 am 10:25 AM
HTTP Status Code 200: Explore the Meaning and Purpose of Successful Responses HTTP status codes are numeric codes used to indicate the status of a server's response. Among them, status code 200 indicates that the request has been successfully processed by the server. This article will explore the specific meaning and use of HTTP status code 200. First, let us understand the classification of HTTP status codes. Status codes are divided into five categories, namely 1xx, 2xx, 3xx, 4xx and 5xx. Among them, 2xx indicates a successful response. And 200 is the most common status code in 2xx
 An in-depth study of the causes and solutions of 404 errors
Feb 25, 2024 pm 12:21 PM
An in-depth study of the causes and solutions of 404 errors
Feb 25, 2024 pm 12:21 PM
Explore the causes and solutions of HTTP status code 404 Introduction: In the process of browsing the web, we often encounter HTTP status code 404. This status code indicates that the server was unable to find the requested resource. In this article, we will explore the causes of HTTP status code 404 and share some solutions. 1. Reasons for HTTP status code 404: 1.1 Resource does not exist: The most common reason is that the requested resource does not exist on the server. This may be caused by the file being accidentally deleted, incorrectly named, incorrectly pathed, etc.
 How to implement HTTP streaming using C++?
May 31, 2024 am 11:06 AM
How to implement HTTP streaming using C++?
May 31, 2024 am 11:06 AM
How to implement HTTP streaming in C++? Create an SSL stream socket using Boost.Asio and the asiohttps client library. Connect to the server and send an HTTP request. Receive HTTP response headers and print them. Receives the HTTP response body and prints it.
 Analysis and optimization strategies for Java Queue queue performance
Jan 09, 2024 pm 05:02 PM
Analysis and optimization strategies for Java Queue queue performance
Jan 09, 2024 pm 05:02 PM
Performance Analysis and Optimization Strategy of JavaQueue Queue Summary: Queue (Queue) is one of the commonly used data structures in Java and is widely used in various scenarios. This article will discuss the performance issues of JavaQueue queues from two aspects: performance analysis and optimization strategies, and give specific code examples. Introduction Queue is a first-in-first-out (FIFO) data structure that can be used to implement producer-consumer mode, thread pool task queue and other scenarios. Java provides a variety of queue implementations, such as Arr
 C++ development advice: How to perform performance analysis of C++ code
Nov 22, 2023 pm 08:25 PM
C++ development advice: How to perform performance analysis of C++ code
Nov 22, 2023 pm 08:25 PM
As a C++ developer, performance optimization is one of our inevitable tasks. In order to improve the execution efficiency and response speed of the code, we need to understand the performance analysis methods of C++ code in order to better debug and optimize the code. In this article, we will introduce you to some commonly used C++ code performance analysis tools and techniques. Compilation options The C++ compiler provides some compilation options that can be used to optimize the execution efficiency of the code. Among them, the most commonly used option is -O, which tells the compiler to optimize the code. Normally, we would set
