


In this article, we’ll explore two methods to remove duplicate elements from a stack in Java. We’ll compare a straightforward approach with nested loops and a more efficient method using a HashSet. The goal is to demonstrate how to optimize duplicate removal and to evaluate the performance of each approach.
Write a Java program to remove the duplicate element from the stack.
Input
Stack<Integer> data = initData(10L);
Output
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
To remove duplicates from a given stack, we have 2 approaches −
Below is the Java program first builds a random stack and then creates a duplicate of it for further use −
private static Stack initData(Long size) {
Stack stack = new Stack < > ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack < Integer > manualCloneStack(Stack < Integer > stack) {
Stack < Integer > newStack = new Stack < > ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}initData helps create a Stack with a specified size and random elements ranging from 1 to 100.
manualCloneStack helps generate data by copying data from another stack, using it for performance comparison between the two ideas.
Following are the step to remove duplicates from a given stack using Naïve approach −
Below is the Java program to remove duplicates from a given stack using Naïve approach −
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack < > ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}For Naive approach, we use
<code>while (!stack.isEmpty())</code>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">resultStack.contains(element)</pre><div class="contentsignin">Copy after login</div></div>
to check if the element is already present.Following are the step to remove duplicates from a given stack using optimized approach −
Below is the Java program to remove duplicates from a given stack using HashSet −
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start));
return tempStack;
}For optimized approach, we use
<code>Set<Integer> seen</code>
Below are the step to remove duplicates from a given stack using both approaches mentioned above −
Below is the Java program that removes duplicate elements from a stack using both approaches mentioned above −
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack<Integer> initData(Long size) {
Stack<Integer> stack = new Stack<>();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack<Integer> cloneStack(Stack<Integer> stack) {
Stack<Integer> newStack = new Stack<>();
newStack.addAll(stack);
return newStack;
}
public static Stack<Integer> idea1(Stack<Integer> stack) {
long start = System.nanoTime();
Stack<Integer> resultStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack<Integer> data1 = initData(10L);
Stack<Integer> data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " + idea1(data1));
System.out.println("Unique elements using idea2: " + idea2(data2));
}
}Output
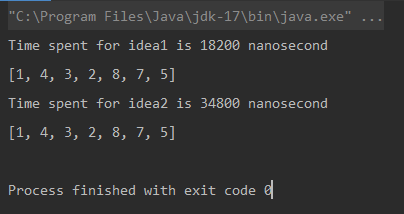
* The unit of measurement is nanosecond.
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}| Method | 100 elements | 1000 elements |
10000 elements |
100000 elements |
1000000 elements |
| Idea 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idea 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
As observed, the time running for Idea 2 is shorter than for Idea 1 because the complexity of Idea 1 is O(n²), while the complexity of Idea 2 is O(n). So, when the number of stacks increases, the time spent on calculations also increases based on it.
The above is the detailed content of Java program to remove duplicates from a given stack. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



