

分类模型可以分为两大类:生成式模型与辨别式模型。本文解释了这两种模型类型之间的区别,并讨论了每种方法的优缺点。
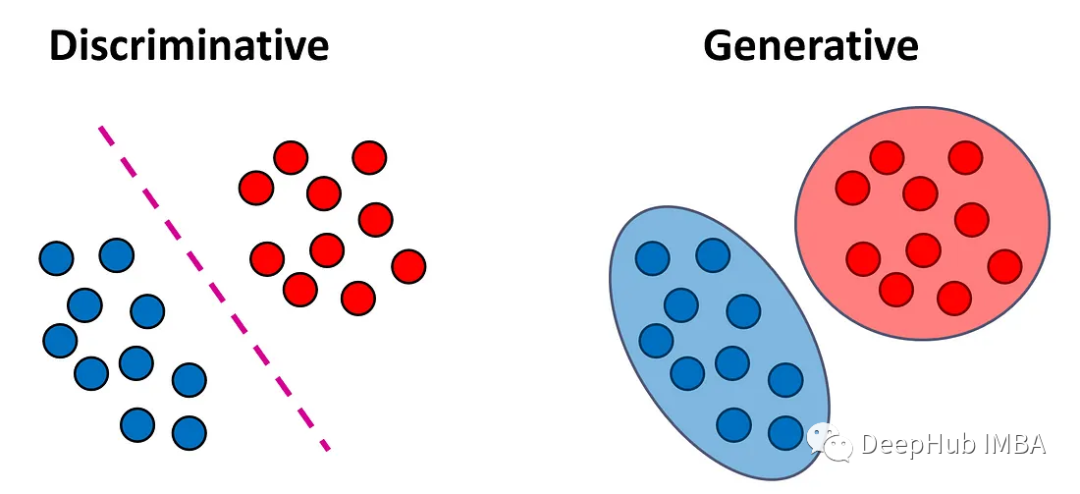
辨别式模型是一种能够学习输入数据和输出标签之间关系的模型,它通过学习输入数据的特征来预测输出标签。在分类问题中,我们的目标是将每个输入向量x分配给标签y。判别模型试图直接学习将输入向量映射到标签的函数f(x)。这些模型可以进一步分为两个子类型:
分类器试图找到f(x)而不使用任何概率分布。这些分类器直接为每个样本输出一个标签,而不提供类的概率估计。这些分类器通常称为确定性分类器或无分布分类器。此类分类器的例子包括k近邻、决策树和SVM。
分类器首先从训练数据中学习后验类概率P(y = k|x),并根据这些概率将一个新样本x分配给其中一个类(通常是后验概率最高的类)。
这些分类器通常被称为概率分类器。这种分类器的例子包括逻辑回归和在输出层中使用sigmoid或softmax函数的神经网络。
在所有条件相同的情况下,我一般都使用概率分类器而不是确定性分类器,因为这个分类器提供了关于将样本分配给特定类的置信度的额外信息。
一般的判别式模型包括:
生成式模型在估计类概率之前学习输入的分布。生成式模型是一种能够学习数据生成过程的模型,它可以学习输入数据的概率分布,并生成新的数据样本。
更具体地说生成模型首先从训练数据中估计类别的条件密度P(x|y = k)和先验类别概率P(y = k)。他们试图了解每个分类的数据是如何生成的。
然后利用贝叶斯定理估计后验类概率:
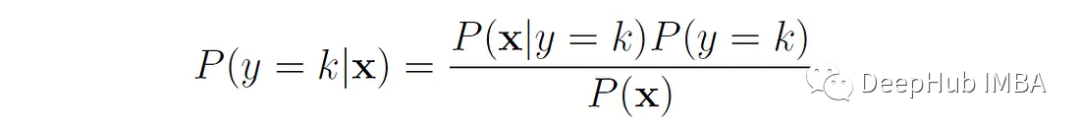
贝叶斯规则的分母可以用分子中出现的变量来表示:
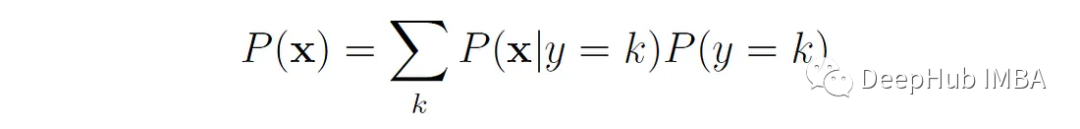
生成式模型也可以先学习输入和标签P(x, y)的联合分布,然后将其归一化以得到后验概率P(y = k|x)。一旦我们有了后验概率,我们就可以用它们将一个新的样本x分配给其中一个类(通常是后验概率最高的类)。
例如,考虑一个图像分类任务中,我们需要区分图像狗(y = 1)和猫(y = 0)。生成模型首先会建立一个狗 P(x|y = 1) 的模型,以及猫 P(x|y = 0) 的模型。然后在对新图像进行分类时,它会将其与两个模型进行匹配,以查看新图像看起来更像狗还是更像猫。
为生成模型允许我们从学习的输入分布P(x|y)中生成新的样本。所以我们将其称之为生成式模型。最简单的例子是,对于上面的模型我们可以通过从P(x|y = 1)中采样来生成新的狗的图像。
一般的生成模型包括
深度生成模型(DGMs)结合了生成模型和深度神经网络:
生成式模型和辨别式模型的主要区别在于它们学习的目标不同。生成式模型学习输入数据的分布,可以生成新的数据样本。辨别式模型学习输入数据和输出标签之间的关系,可以预测新的标签。
生成式模型:
生成模型给了我们更多的信息,因为它们同时学习输入分布和类概率。可以从学习的输入分布中生成新的样本。并且可以处理缺失的数据,因为它们可以在不使用缺失值的情况下估计输入分布。但是大多数判别模型要求所有的特征都存在。
训练复杂度高,因为生成式模型要建立输入数据和输出数据之间的联合分布,需要大量的计算和存储资源。对数据分布的假设比较强,因为生成式模型要建立输入数据和输出数据之间的联合分布,需要对数据的分布进行假设和建模,因此对于复杂的数据分布,生成式模型在小规模的计算资源上并不适用。
生成模型可以处理多模态数据,因为生成式模型可以建立输入数据和输出数据之间的多元联合分布,从而能够处理多模态数据。
辨别式模型:
如果不对数据做一些假设,生成式模型学习输入分布P(x|y)在计算上是困难的,例如,如果x由m个二进制特征组成,为了对P(x|y)建模,我们需要从每个类的数据中估计2个ᵐ参数(这些参数表示m个特征的2个ᵐ组合中的每一个的条件概率)。而Naïve Bayes等模型对特征进行条件独立性假设,以减少需要学习的参数数量,因此训练复杂度低。但是这样的假设通常会导致生成模型比判别模型表现得更差。
对于复杂的数据分布和高维数据具有很好的表现,因为辨别式模型可以灵活地对输入数据和输出数据之间的映射关系进行建模。
辨别式模型对噪声数据和缺失数据敏感,因为模型只考虑输入数据和输出数据之间的映射关系,不利用输入数据中的信息填补缺失值和去除噪声。
生成式模型和辨别式模型都是机器学习中重要的模型类型,它们各自具有优点和适用场景。在实际应用中,需要根据具体任务的需求选择合适的模型,并结合混合模型和其他技术手段来提高模型的性能和效果。
以上是生成式模型与辨别式模型的详细内容。更多信息请关注PHP中文网其他相关文章!





















