

arXiv论文“ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning“,22年7月,作者来自上海交大、上海AI实验室、加州圣地亚哥分校和京东公司的北京研究院。

提出一种时空特征学习方案,可以同时为感知、预测和规划任务提供一组更具代表性的特征,称为ST-P3。具体而言,提出一种以自车为中心对齐(egocentric-aligned)的累积技术,在感知BEV转换之前保留3-D空间中的几何信息;作者设计一种双路(dual pathway )模型,将过去的运动变化考虑在内,用于未来的预测;引入一个基于时域的细化单元,补偿为规划的基于视觉元素识别。源代码、模型和协议详细信息开源https://github.com/OpenPerceptionX/ST-P3.
开创性的LSS方法从多视图摄像机中提取透视特征,通过深度估计将其提升到3D,并融合到BEV空间。两个视图之间的特征转换,其潜深度预测至关重要。
将二维平面信息提升到三维需要附加维度,即适合三维几何自主驾驶任务的深度。为了进一步改进特征表示,自然要将时域信息合并到框架中,因为大多数场景的任务是视频源。
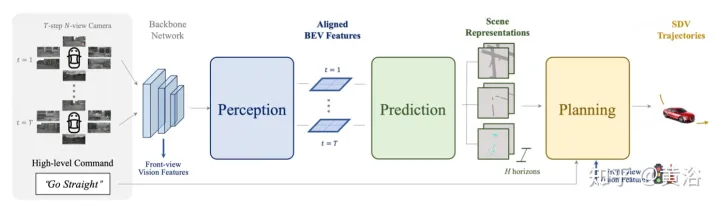
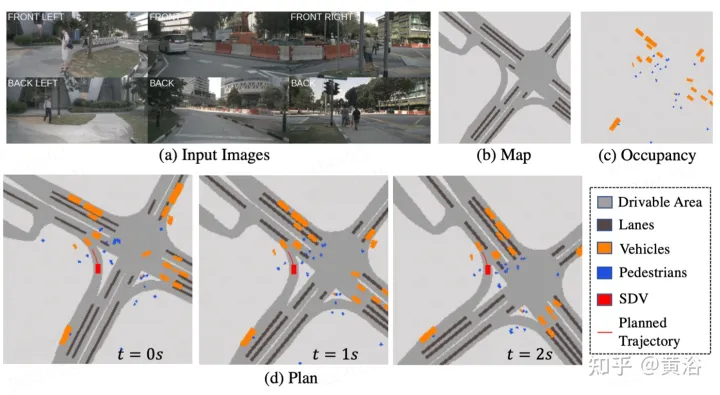
如图描述ST- P3总体框架:具体来说,给定一组周围的摄像机视频,将其输入主干生成初步的前视图特征。执行辅助深度估计将2D特征转换到3D空间。以自车为中心对齐累积方案,首先将过去的特征对齐到当前视图坐标系。然后在三维空间中聚合当前和过去的特征,在转换到BEV表示之前保留几何信息。除了常用的预测时域模型外,通过构建第二条路径来解释过去的运动变化,性能得到进一步提升。这种双路径建模确保了更强的特征表示,推断未来的语义结果。为了实现轨迹规划的最终目标,整合网络早期的特征先验知识。设计了一个细化模块,在不存在高清地图的情况下,借助高级命令生成最终轨迹。
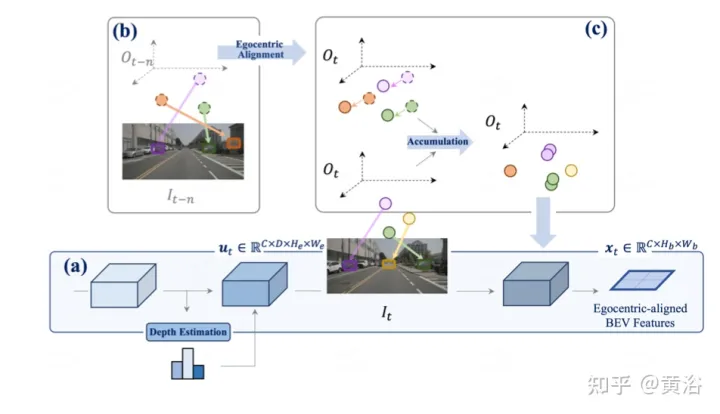
如图是感知的以自我为中心对齐累计方法。(a) 利用深度估计将当前时间戳处的特征提升到3D,并在对齐后合并到BEV特征;(b-c)将先前帧的3D特征与当前帧视图对齐,并与所有过去和当前状态融合,从而增强特征表示。
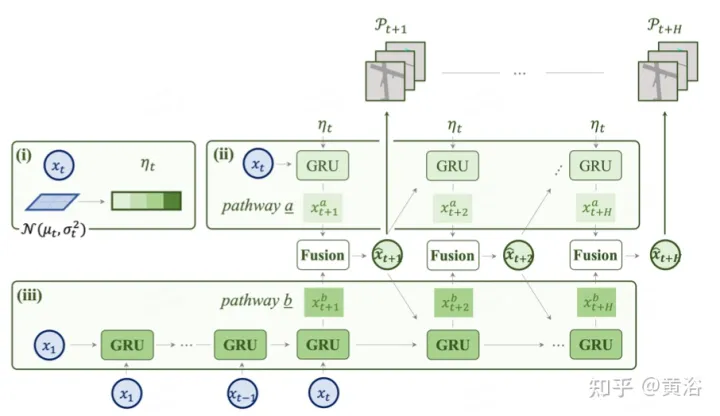
如图是用于预测的双路模型:(i) 潜码是来自特征图的分布;(ii iii)路a结合了不确定性分布,指示未来的多模态,而路b从过去的变化中学习,有助于路a的信息进行补偿。
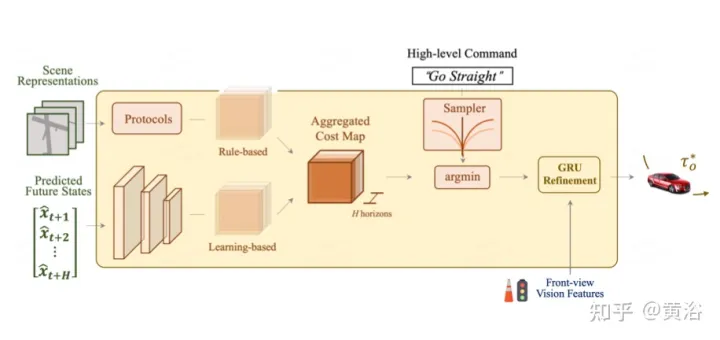
作为最终目标,需要规划一条安全舒适的轨迹,到达目标点。这个运动规划器对一组不同的轨迹进行采样,并选择一个最小化学习成本函数的轨迹。然而,通过一个时域模型来整合目标(target)点和交通灯的信息,加上额外的优化步骤。
如图是为规划的先验知识集成和细化:总体成本图包括两个子成本。使用前视特征进一步重新定义最小成本轨迹,从摄像机输入中聚合基于视觉的信息。
惩罚具有较大横向加速度、急动或曲率的轨迹。希望这条轨迹能够有效地到达目的地,因此向前推进的轨迹将奖励。然而,上述成本项不包含通常由路线地图提供的目标(target)信息。采用高级命令,包括前进、左转和右转,并且只根据相应的命令评估轨迹。
此外,交通信号灯对SDV至关重要,通过GRU网络优化轨迹。用编码器模块的前摄像头特征初始化隐藏状态,并用成本项的每个采样点作为输入。
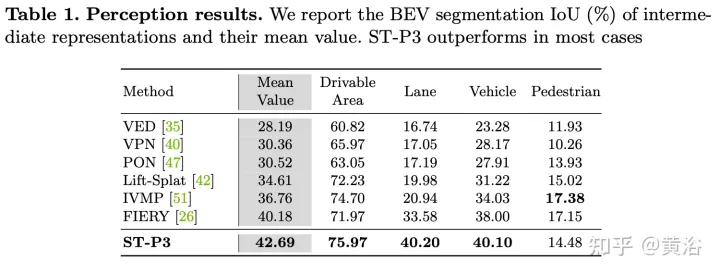
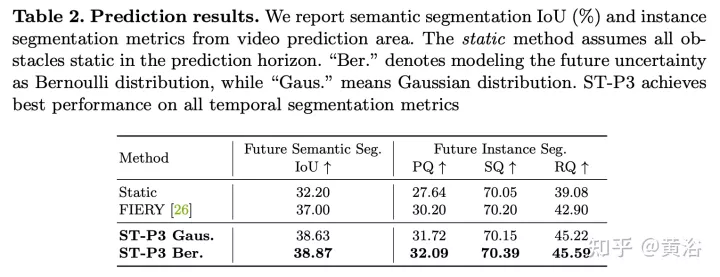
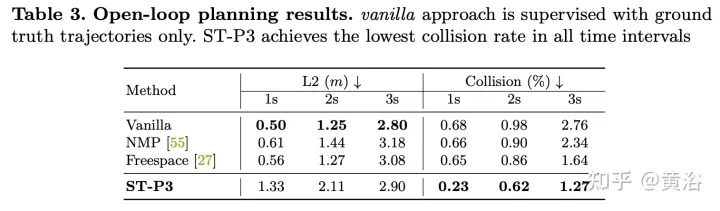
实验结果如下:
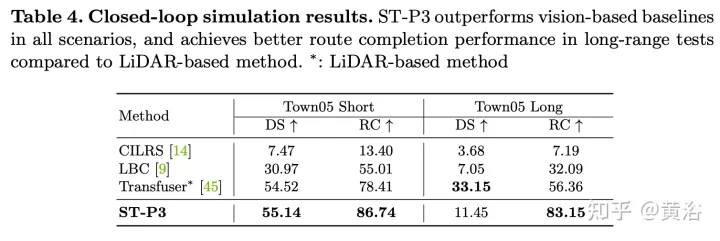
以上是ST-P3:端到端时空特征学习的自动驾驶视觉方法的详细内容。更多信息请关注PHP中文网其他相关文章!





















