

本篇文章给大家带来了关于数据表的相关知识,其中主要给大家分享一种自平衡解决数据倾斜的分表方法,感兴趣的朋友下面一起来看一下吧,希望对大家有帮助。
这篇主要描述了B端令牌系统应用数据分表解决业务数据量增大,且存在的数据倾斜问题,主要面向的场景是一对多数据倾斜问题
先简述一下B令牌的业务背景,B令牌系统是用于营销场景中,将许多用户绑定在一个令牌上,再将令牌绑定在促销上,从而实现差异和精准营销,一般情况下一个令牌的生命周期等同于这个促销。
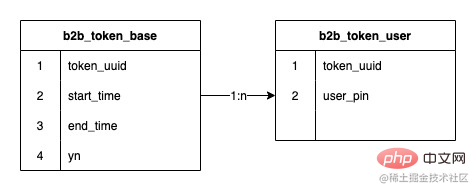
令牌和令牌用户关系是一个一对多的关系,早期的令牌系统使用jed分库,2个分片,中间进行了一次扩容达到了8个分片,存储的数据行数达到了1.2亿
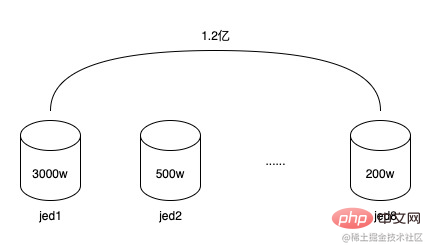
1.2亿数据,分布在8个分库中,每个分库平均1500万,但由于分库字段使用的是令牌ID(token_uuid),有得令牌用户少,只有几千到一万,有的令牌用户多,有100万到150万,令牌总数量并不多,只有2万左右,所以导致数据存在倾斜,有的分库有3000多万数据,有的分库可能只有几百万,这已经开始导致数据库读写性能下降。而又因为令牌用户关系表数据结构很简单,虽然数据行数很多,但占用的空间却不大。8个分库总占用量还不足20G。同时令牌的生命周期基本和促销相同,一个令牌服务于一个或几个促销后,就会慢慢过期被弃之不用,后续会继续创建新的令牌。所以这些过期令牌是可以进行归档的。
同时由于B端业务的发展,业务诉求也更多,和业务沟通中了解到,未来会上线自动选人系统,由系统自动创建令牌,并选择适合促销的人群,未来每个月数据增量在3000万左右,如果运行一年就会增加3.6亿,届时单表数据量平均会达到6000万,当前的设计架构已经完全不能满足业务需求。
同时目前也存在根据令牌ID分页查询令牌下用户的功能,但仅限于给管理端运营使用,使用也不频繁。
面对日益下降的数据库读写性能,以及业务增长的需求,当下面临以下几个问题:
如何解决单表数据行数过多的问题
当前分库方案存在比较严重的数据倾斜
如果应对未来数据的增长
一般情况应对第一个问题,通常都是分库分表,而当下我们已经是8个分库,而且8个分库才占用了不足20G空间,单库资源浪费严重,所以完全不会考虑继续增加分库的方式,所以分表才是解决办法。
数据分表通常有两种方式:垂直分表和水平分表。
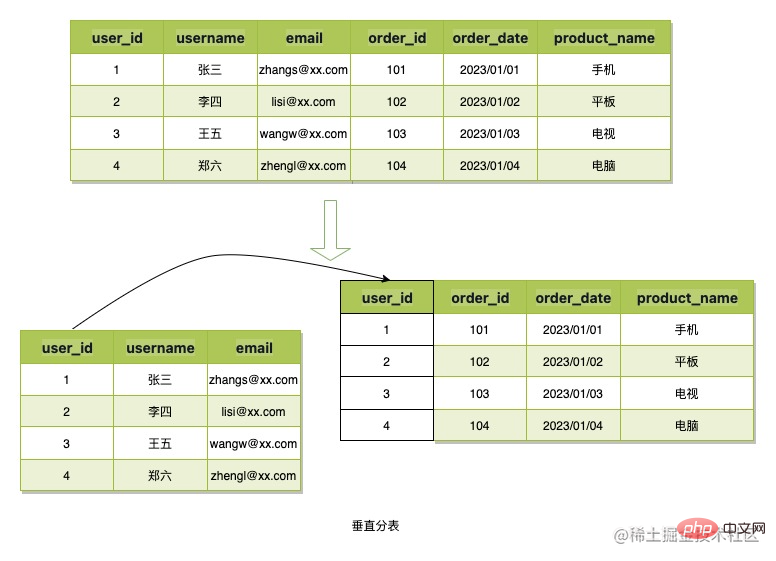
垂直分表指的是将数据的列进行拆分,然后应用主键或其他业务字段进行关联,从而降低单表数据占用空间,或减少冗余存储,B令牌的场景数据结构简单,数据占用空间小,所以不会使用该分表方式。
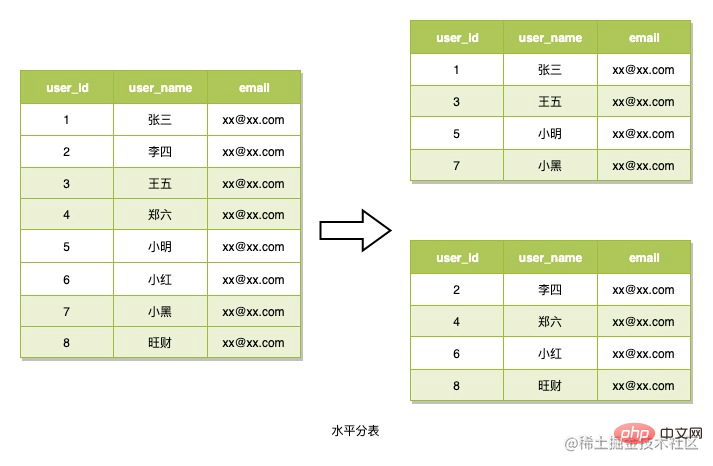
水平分表指的是将数据的行以一种路由算法拆分到多张表中,读取时候也基于这种路由算法来读取数据,这种分表策略一般用来应对数据结构不复杂,但数据行特别多的场景。这也是我们即将使用的方式。使用这种方式需要考虑的就是如何设计路由算法,这里也是使用这种方式来分表。
数据分表路由算法的使用在业内也有多种,一种是利用一致性hash,选择合适的分表字段,对字段值hash后值是固定的,使用该值通过取模或者按位运算的方式得到一个固定的序号,从而确定数据存储在哪张表中。
比较常见的应用如分库大多就是使用一致性hash的方式,通过即时计算分库字段的值判断数据属于哪个分库从而决定将数据存入哪个分库或者从哪个分库读取数据。而如果查询时没有指定分库字段则需要同时向所有分库发出查询请求,最后在汇总结果。
另外像java代码的HashMap数据结构其实也是一种一致性hash算法的分表策略,通过对key进行hash后决定将数据存入数组的哪个序号,HashMap里面用的不是取模的方式获取序号,而是使用按位运算的方式,使用这种方式也决定了HashMap的扩容都是按照2的x次方的大小进行扩容,以后有机会可以介绍这个原理。
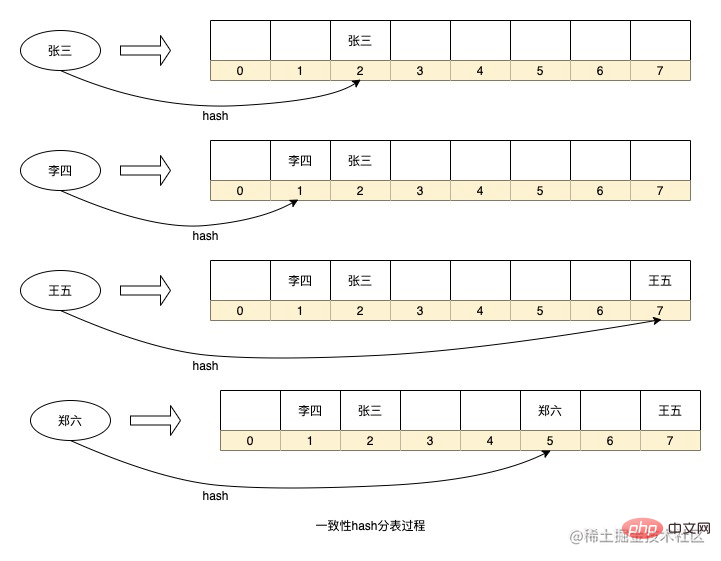
上面就是HashMap中的一个简化的数据Hash存储过程,当然我省略了一些细节,比如HashMap中每一个节点都是一个链表(冲突过多还会变成红黑树)。应用在我们的场景中就可以将每个序号当成是一张数据表即可。
以上这种路由算法的优点的路由策略简单,实时计算也不用增加额外存储空间,但也存在一个问题就是如果要扩容则需要将历史数据重新hash一遍进行迁移,比如数据库分库如果增加分库则需要将所有数据重新计算分库,HashMap扩容也会执行rehash重新计算key在数组的序号。如果数据量太大,这种计算过程耗时将会很长。同时,如果数据表太少,或者选择分片的字段离散程度低都会导致数据倾斜。
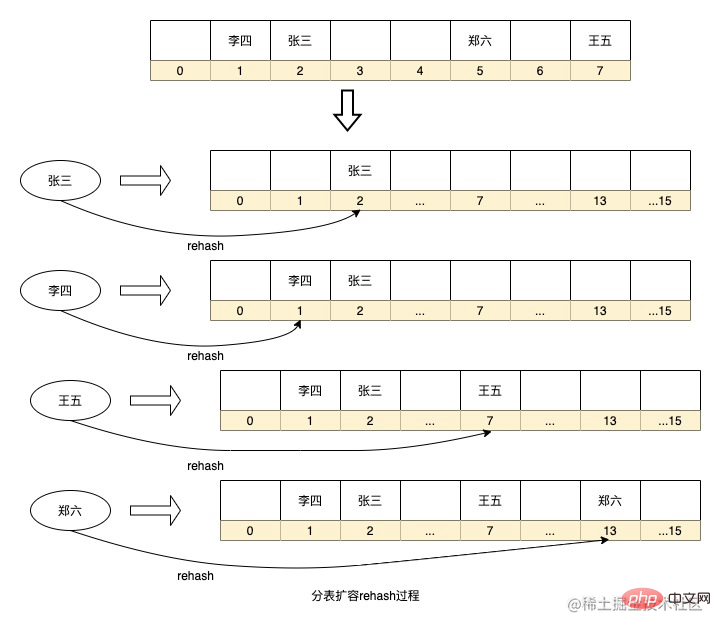
还有一种分表算法优化了这种rehash过程,这便是一致性hash环,这种方式是在实体节点之间抽象出很多虚拟节点,然后再利用一致性hash算法将数据打在这些虚拟节点上,而每个实体节点其实是负责的该实体节点逆时针方向上和另一个实体节点相邻的虚拟节点的数据。这种方式的好处是假如需要扩容增加节点,增加的节点放在环上任意位置,也只会影响到该节点顺时针方向上相邻节点的数据,只需要将该节点中的部分数据迁移到这个新节点上即可,大大降低rehash的过程。同时由于虚拟节点多,也可以增加让数据更均匀的分布在这个环上,只要将实体节点放置在合适的位置,就能最大程度保证的解决数据倾斜问题。
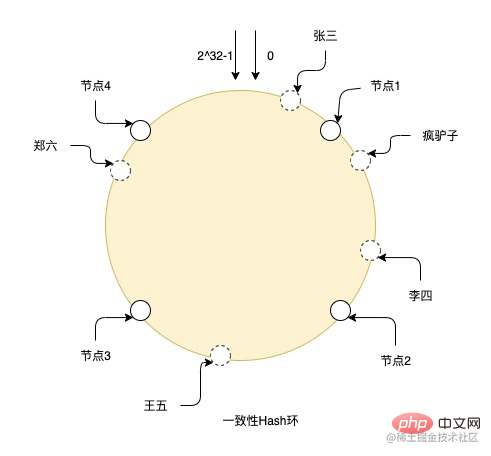
比如图上就是一个一致性Hash环的hash过程,在整个环上有从0到2^32-1个节点,其中实线的就是真实节点,其他都是虚拟节点,张三通过hash后落到环上的虚拟节点,然后从虚拟节点的位置顺时针寻找真实节点,最终数据就存储在真实节点上,所以疯驴子和李四就存储在节点2上,王五在节点3上,郑六在节点4上。
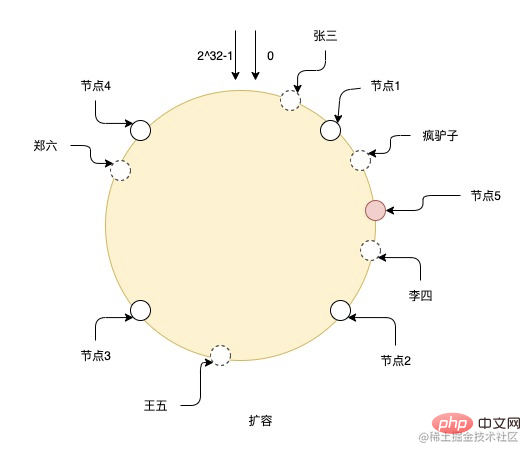
扩容了一个节点5号后,则需要将节点1和节点5之间的数据迁移到节点5上,其他节点数据则不用变更。但如图上看到的,只加这一个节点,也容易导致每个节点负责的数据不均匀,比如节点2和节点5,相比于其他节点负责的数据就少了很多,所以扩容时最好是成倍扩容,这样数据可以继续保持均匀。
再回到B令牌的业务场景上来,需要能达成以下诉求
首先必须使用水平分表来解决单表数据量过大的问题
需要能支持根据令牌分页查询用户
由于当前业务数据增量在3000万,但不排除未来业务继续增长的可能,分表数量需要能支持未来扩展
数据行数过高,未来在扩展时必须保证无需数据迁移或者数据迁移成本低
需要解决数据倾斜问题,确保不因为单表数据量过大而导致整体性能降低
基于以上诉求,首先看问题b,如果要支持根据令牌分页查询用户,就需要保证令牌下的所有用户都在同一张表上,才能简单的支持分页查询,否则用一些汇总归并算法则复杂程度过高了,而且表太多也会降低查询性能。虽然也可以通过将数据异构es提供查询功能,但仅仅是为了少量管理端的查询诉求再进行数据异构,成本有些高收益并不明显,也有些浪费资源。所以分表字段就只能确定使用令牌ID。
而上面也提到令牌ID数量并不多,而且令牌下的用户也从1万到100万不等,单纯使用一致性hash的方式用令牌ID作为分表策略则会导致数据倾斜严重,而且未来扩容时数据迁移成本也很高。
但使用一致性hash环又会导致未来在扩容时最好是按2的倍数扩容,不然就会存在有的节点负责的虚拟节点多,有的节点负责虚拟节点少,导致数据不均匀。然而在和数据库同事进行沟通,一个数据库下的数据表数量不宜太多,否则会对数据库带来较大压力,而一致性hash环这种方式可能扩两三次容就会导致分表数达到一个很高的数值。
基于以上问题,在确定使用令牌id作为分表的前提下,就需要着重思考如何支持动态扩容和解决数据倾斜的问题。
分表的字段已经确定使用令牌ID,而前面也提到我们的数据结构是令牌和用户是一对多的关系数据,那么在创建令牌时hash出的分表序号存储下来,后续基于存储的分表序号进行路由,就可以保证未来扩容时也不会影响存量数据的路由,无需进行数据迁移。
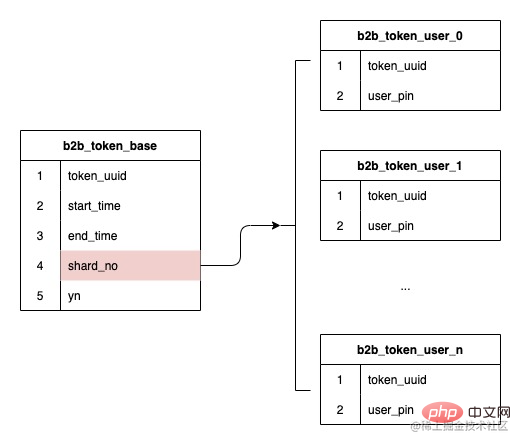
由于选用了令牌ID作为分表字段,而各令牌数据量大小不一,数据倾斜就会是一个大问题。所以这里就想办法引入了一个分表水位的概念。

在用户请求保存或删除关系用户数的时候,基于分表序号对当前分表数量进行一个增减的计数,当某个分表中的数据量处于高水位时,就将该分表从分表算法中剔除,从而让该分表不会继续产生新的数据。
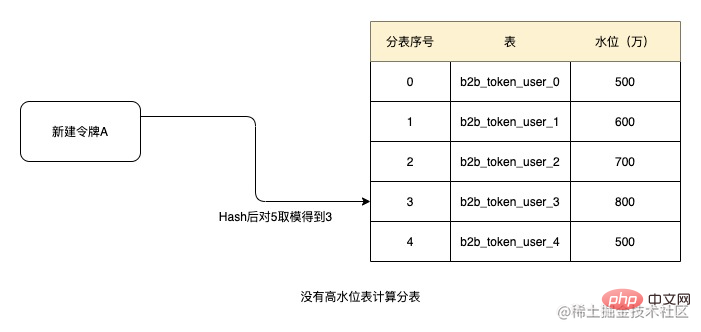
比如当设置阈值1000万为高水位,由于以上5张表都没有达到高水位,则创建令牌时根据令牌ID进行Hash后取模得到3,按顺序获取表,则当前令牌的分表号为b2b_token_user_3。后续关系数据都从该表中获取。
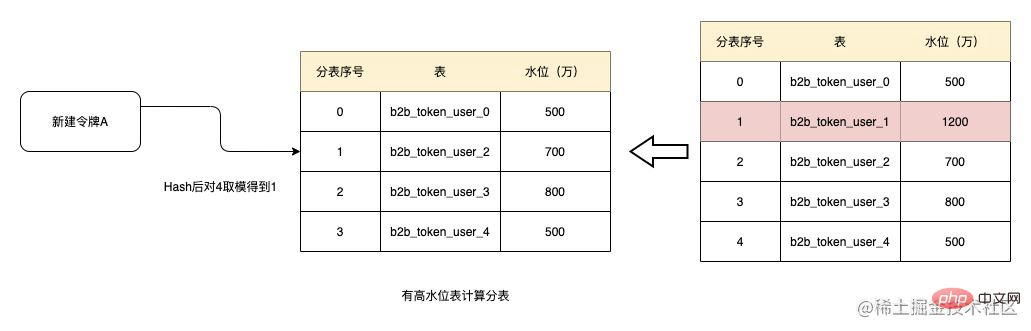
运行一段时间后,表b2b_token_user_1数据量已经增长到了1200万,超过了1000万的水位,这时候在创建令牌则将该表移除,在此进行Hash后取模得到1,则当前分到的表就是b2b_token_user_2。而如果b2b_token_user_1的水位如果一直不能降下来,则该表后续都不会再参与分表,表中的数据量也不会再增加。
当然有一种可能就是所有表都进入了高水位,为了兜底,这时水位功能就失效,所有表都加入到分表中来。
如果表中的数据量只会不断增加,而不会减少的话,那么早晚所有的表都会达到高水位,这就不能达到动态的效果。上面背景中有提到,令牌创建后是为某一批促销服务,促销终止后,令牌也会失去作用,同时令牌上也有有效期,超过有效期的令牌也会失去作用。所以定期对数据进行归档就可以让那些处于高水位的表把水位慢慢降下来,重新加入到分表中。
而且当前令牌已经存在了一张b2b_token_user的表,里面的数据已经有1.2亿,可以将该表作为图上的0号表,这样在第一次上线时只要将历史令牌都的分表序号都记为0即可,存量数据就不需要再进行迁移,而该表数据量水位高,也不会参与分表。再搭配定期的数据归档,该表的水位也会慢慢将下来。
虽然可以通过定期进行数据归档,可以让表的水位降下来,但随着业务发展,可能会存在大多数表都进入了高水位,并且都是有效数据的情况。这时候系统就会像HashMap判断容量达到75%就自动扩容一样,我们不能够自动创建表,但当75%的表都进入高水位可以告警出来,开发人员监听到告警人工介入,观察是需要调高水位,还是进行表的扩容。
• 水位阈值和扩容监控
目前水位的阈值还是依靠人工手动设置,应该设置多大还是比较感性的,只能设置一个,在告警以后适当调整。不过其实可以在系统中自动监控接口读写性能的波动,发现大多数表达到高水位时,接口读写性能都没有明显变化,可以系统自动调高阈值,从而形成智能阈值。
而接口性能读写出现明显变化时发现大多数表都达到了阈值,则可以告警提示应当考虑扩容。
解决问题从来没有银弹,我们需要利用手里的技术手段和工具,进行组合、适配,使之适合我们当下的业务和场景,没有好或不好,只有适不适合。
以上是知识拓展:一种自平衡解决数据倾斜的分表方法的详细内容。更多信息请关注PHP中文网其他相关文章!
























