

python视频教程栏目带大家认识 Python 内置函数。

在Python猫的上一篇文章中,我们对比了两种创建列表的方法,即字面量用法 [] 与内置类型用法 list(),进而分析出它们在运行速度上的差异。
在分析为什么 list() 会更慢的时候,文中说到它需要经过名称查找与函数调用两个步骤,那么,这就引出了一个新的问题:list() 不是内置类型么,为什么它不能直接就调用创建列表的逻辑呢?也就是说,为什么解释器必须经过名称查找,才能“认识”到该做什么呢?
其实原因很简单:内置函数/内置类型的名称并不是关键字,它们只是解释器内置的一种便捷功能,方便开发者开箱即用而已。
PS:内置函数 built-in function 和内置类型 built-in type 很相似,但 list() 实际是一种内置类型而不是内置函数。我曾对这两种易混淆的概念做过辨析,请查看这篇文章。为了方便理解与表述,以下统称为内置函数。
内置函数的名称并不属于关键字,它们是可以被重新赋值的。
比如下面这个例子:
# 正常调用内置函数list(range(3)) # 结果:[0, 1, 2]# 定义任意函数,然后赋值给 listdef test(n):
print("Hello World!")
list = test
list(range(3)) # 结果:Hello World!复制代码
在这个例子中,我们将自定义的 test 赋值给了 list,程序并没有报错。这个例子甚至还可以改成直接定义新的同名函数,即"def list(): …"。
这说明了 list 并不是 Python 限定的关键字/保留字。
查看官方文档,可以发现 Python 3.9 有 35 个关键字,明细如下:

如果我们将上例的 test 赋值给任意一个关键字,例如"pass=test",就会报错:SyntaxError: invalid syntax。
由此,我们可以从这个角度看出内置函数并不是万能的:它们的名称并不像关键字那般稳固不变,虽然它们处在系统内置作用域里,但是却可以被用户局部作用域的对象所轻松拦截掉!
因为解释器查找名称的顺序是“局部作用域->全局作用域->内置作用域”,因此内置函数其实是处在最低优先级。
对于新手来说,这有一定的可能会发生意想不到的情况(内置函数有 69 个,要全记住是有难度的)。
那么,为什么 Python 不把所有内置函数的名称都设为不可复写的关键字呢?
一方面原因是它想控制关键字的数量,另一方面可能是想留给用户更多的自由。内置函数只是解释器的推荐实现而已,开发者可以根据需要,实现出与内置函数同名的函数。
不过,这样的场景极少,而且开发者一般会定义成不同名的函数,以 Python 标准库为例,ast模块有 literal_eval() 函数(对标 eval() 内置函数)、pprint 模块有 pprint() 函数(对标 print() 内置函数)、以及itertools模块有 zip_longest() 函数(对标 zip() 内置函数)……
由于内置函数的名称并非保留的关键字,以及它处于名称查找的末位顺序,所以内置函数有可能不是最快的。
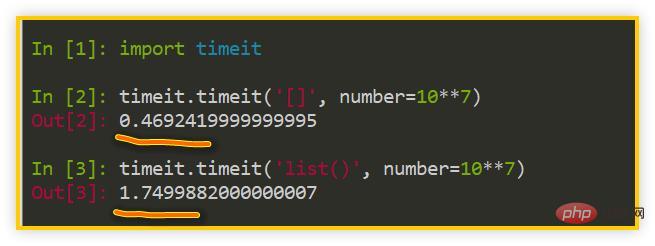
上篇文章展示了 [] 比 list() 快 2~3 倍的事实,其实这还可以推广到 str()、tuple()、set()、dict() 等等内置类型中,都是字面量用法稍稍快于内置类型用法。
对于这些内置类型,当我们调用 xxx() 时,可以简单理解成正在做类的实例化。在面向对象语言中,类先实例化再使用,这是再正常不过的。
但是,这样的做法有时也显得繁琐。为了方便使用,Python 给一些常用的内置类型提供了字面量表示法,也就是""、[]、()、{} 等等,表示字符串、列表、元组和字典等数据类型。

文档出处:docs.python.org/3/reference…
一般而言,所有编程语言都必须有一些字面量表示,但基本都局限在数字类型、字符串、布尔类型以及 null 之类的基础类型。
Python 中还增加了几种数据结构类型的字面量,所以是更为方便的,同时这也解释了为什么内置函数可能不是最快的。
一般而言,同样的完备功能,内置函数总是比我们自定义的函数要快,因为解释器可以做一些底层的优化,例如 len() 内置函数肯定比用户定义的 x.len() 函数快。
有些人据此形成了“内置函数总是更快”的认识误区。
解释器内置函数相对于用户定义函数,前者接近于走后门;而字面量表示法相对于内置函数,前者是在走更快的后门。
也就是说,在有字面量表示法的情况下,某些内置函数/内置类型并不是最快的!
诚然,Python 本身并不是万能的,那它的任何语法构成部分(内置函数/类型),就更不是万能的了。但是,一般我们会认为内置函数/类型总归是“高人一等”的,是受到诸多特殊优待的,显得像是“万能的”。
本文从“list() 竟然会败给 []”破题,从两个角度揭示了内置函数其实存在着某种不足:内置函数的名称并不是关键字,而内置作用域位于名称查找的最低优先级,因此在调用时,某些内置函数/类型的执行速度就明显慢于它们对应的字面量表示法。
本文对上一个“Python为什么”话题做了延展讨论,一方面充实了前面的内容,另一方面,也有助于大家理解 Python 的几个基础概念及其实现。
如果你喜欢本文,请点赞支持下吧!另外,我还写了 20 篇类似的话题,请关注Python猫查看,并在 Github 上给我一颗小星星吧~~
相关免费学习推荐:python视频教程
以上是了解为什么说 Python 内置函数并不是万能的?的详细内容。更多信息请关注PHP中文网其他相关文章!























