

这项开创性的调查是2024年2月发布的“大语言模型的数据集:全面调查”,揭示了大型语言模型(LLM)开发的400多个精心分类数据集的宝库。该资源由杨刘,若恩曹,春朱刘,凯恩和莉安文·金编辑,是研究人员和开发人员的金矿。这不仅仅是静态收藏;它定期更新,以确保其持续的相关性。
该论文提供了LLM数据集的全面概述,对于理解这些强大模型的基础至关重要。数据集分为七个关键维度:预训练的语料库,指令微调数据集,偏好数据集,评估数据集,传统的NLP数据集,多模式大语言模型(MLLMS)数据集和检索增强生成(RAG)数据集。纯粹的规模令人印象深刻,单独培训的数据超过774.5 TB,其他类别的7亿个实例,涵盖了32个域和8种语言。

关键数据集类别和示例:
该调查详细介绍了各种数据集类型,包括:
培训前语料库:初始LLM培训的大量文本收集。示例包括Madlad-400(2.8T代币),FineWeb(15TB代币)和BookCorpusopen(17,868本书)。这些进一步分解为一般语料库(网页,书籍,语言文本)和特定于领域的语料库(金融,医学,数学)。
指令微调数据集:成对的说明和改进模型行为的相应答案。示例包括Databricks-Dolly-15K和羊Alpaca_data。这些也分为一般和域特异性(医学,代码)数据集。
偏好数据集:用于通过比较多个响应来评估和改善模型输出。示例包括chatbot_arena_conversations和HH-RLHF。
评估数据集:专门设计用于在各种任务上基准LLM性能。例子包括山帕卡瓦尔和Bayling-80。
传统的NLP数据集:用于Pre-LLM NLP任务的数据集。示例包括Boolq,Cosmosqa和PubMedQA。
多模式大型语言模型(MLLMS)数据集:结合文本和其他模式(图像,视频)的数据集。示例包括莫斯卡和MMRS-1M。
检索增强生成(RAG)数据集:具有外部数据检索功能增强LLM的数据集。例如Crud-rag和Wikival。

资料来源:大型语言模型的数据集:一项全面调查
调查的架构如下所示:
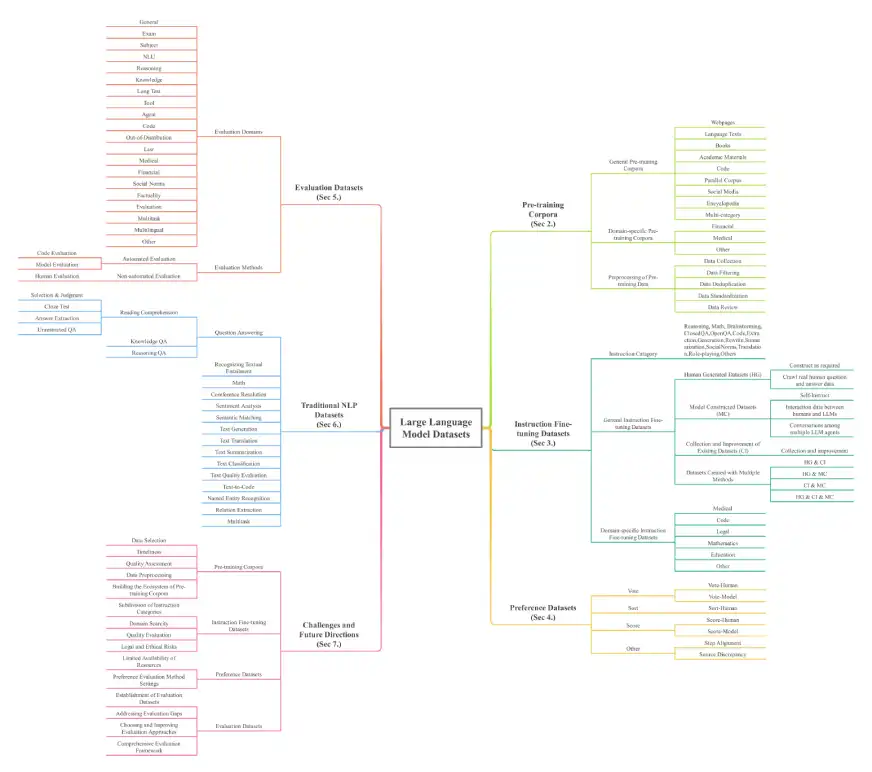
结论和进一步的探索:
这项调查是LLM领域的研究人员和开发人员的重要资源。提供的存储库(Awesome-llms-datasets)提供了一个完整的路线图,用于访问和利用这些宝贵的数据集。详细的分类和全面的统计数据使其成为任何使用或研究LLM的人的重要工具。本文还解决了关键挑战,并提出了未来的研究方向。
以上是400个大型语言模型数据集的指南的详细内容。更多信息请关注PHP中文网其他相关文章!






















