

由於從事IT這個行業,我們需要每天應對故障和問題,因此我們可以稱之為消防員,處處奔波解決問題。不過,這次的故障範圍有點大,宿主機都打不開了。
好在監控系統留下了一些證據。
證據發現,機器的CPU、記憶體、檔案句柄,隨著業務的成長,持續的上升...上升....,直到監控也無法將資訊收集上來。
要命的是,這些宿主機上,部署了非常多的Java進程。沒別的原因,就是為了節省成本,混部了應用。當宿主機表現出整體性的異常時,就難以找到罪魁禍首。
由於遙控器登入已失效,急躁的維運人員只能選擇重新啟動機器,並在重新啟動後開始重新啟動應用程式。經過漫長的等待,所有進程都恢復正常運行,但是僅僅過了短暫的時間,宿主機就突然宕機了。
業務一直處於死翹翹的狀態,真是讓人惱火啊。也讓人心急。嘗試過幾次之後,維運崩潰了,啟動了緊急預案:回滾!
最近的上線記錄有點多,而且有開發人員私自上線部署的行為,維運蒙圈了:回滾哪些呢?還好有人腦瓜一亮,想起了還有find這個命令,那就找到最近更新的所有jar包,都給它來次回滾吧。
find /apps/deploy -mtime +3 | grep jar$
如果你不知道find這個指令,那可還真的是一場災難。還好有人知道。
把十來個jar包回滾,還好沒有碰到資料庫的schema變更,系統終於正常運作了。
沒別的辦法,查日誌,進行程式碼審查。
為了確保程式碼的質量,程式碼審查的範圍應該限定在最近1週或2週內的程式碼改動,因為有些功能程式碼需要一定時間的沉澱,才能在線上獨放異彩。
看著滿屏的提交記錄“OK”,技術經理的臉都綠了。
「xjjdog說過,《80%的程式設計師,不會寫commit紀錄》,我看你們是100%都不會寫」。
大家都靜悄悄的,忍著痛翻查歷史變更。經過大家不懈的努力,終於在屎山之間,找到了一些問題代碼。一個CxO親自創建的群,大家紛紛將可能出現問題的程式碼丟進去。
"系統服務中斷了接近一個小時,影響非常惡劣",CxO說,「務必把問題徹底解決掉,這個問題投資人非常關注」!
okokok,有了釘釘的助力,大家的手勢都變得整齊劃一。
程式碼有點多,大家對問題程式碼討論了老久。這句話的重寫如下: 我們檢查了一些使用並行流和嵌套在lambda表達式中的複雜程式碼,並在其中特別關注了線程池的使用。
最後大家決定還是對執行緒池的程式碼再過一遍。其中有一段是這麼寫的。
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200, 60000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(10), handler);
還別說,參數有模有樣的,甚至考慮到了拒絕策略。
Java的執行緒池,使得程式設計變的非常簡單。如果不逐一介紹,這些參數就無法被審查,如上圖所示。
corePoolSize:核心執行緒數,核心執行緒建立後會一直存活
maxPoolSize:最大執行緒數
#keepAliveTime:執行緒空閒時間
workQueue:阻塞佇列
threadFactory:執行緒建立工廠
#handler:拒絕策略
下面來介紹它們的關係。
如果執行緒數少於核心執行緒數時,有新任務到來,系統會建立一個新執行緒來處理該任務。如果目前執行緒數量超過核心執行緒數量,且阻塞佇列未滿,任務將被放入阻塞佇列中。當執行緒數大於核心執行緒數,而且阻塞佇列滿了的時候,將會建立新的執行緒進行服務,直到執行緒數到達maximumPoolSize的大小。此時,如果還有新的任務,將會觸發拒絕策略。
再說一下拒絕策略。 JDK內建了4種策略,其中預設的是AbortPolicy,即直接拋出異常。下面介紹其他幾種。
DiscardPolicy 比abort更加激進,直接丟掉任務,連異常訊息都沒有
任務處理是由呼叫執行緒執行的,這是CallerRunsPolicy 的實作方式。當一個Web應用的執行緒池資源被佔滿後,新增的任務會被指派到Tomcat執行緒中執行。在某些情況下,這種方法可以減輕一些任務的執行壓力,但在更多情況下,它會直接阻塞主執行緒的執行
DiscardOldestPolicy 丟棄佇列最前面的任務,然後重新嘗試執行任務
這段執行緒池程式碼是新加入的,參數設定也比較合理,沒有太大的問題。使用DiscardOldestPolicy拒絕策略是唯一可能的風險。當任務非常多的時候,這個拒絕策略會造成任務排隊,請求超時。
當然不能放過這種風險,說實話也是到現在為之能夠找到的最可能的風險代碼了。
"把DiscardOldestPolicy 改成預設的AbortPolicy吧,重新打包上線一下試試「。技術大牛在群組裡說。
結果,服務灰度上線之後,宿主機不多時,就死掉了。是它的原因沒跑了,但是why?
線程池的大小 ,最小100,最大200,說什麼也不過分。阻塞隊列的容量只有10,說什麼也不會造成問題。你要說是這個線程池造成的原因,打死我都不信。
但是業務部門回饋,這段程式碼加上就死,不加就沒事。技術大牛抓耳撓腮百思不得其姐。
到最後,終於有人忍不住了,下載下業務的程式碼打算調試一下。
當他打開Idea的時候,瞬間懵逼了,又瞬間領悟了。他終於明白這段程式碼為什麼會產生問題了。
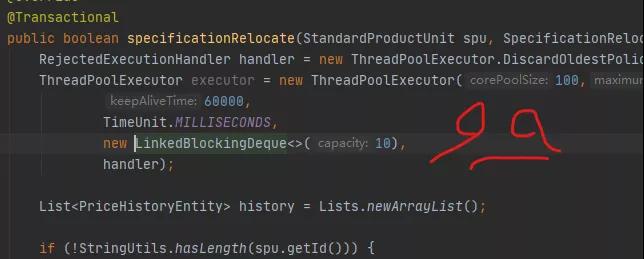
執行緒池,竟然是在方法裡創建的!
#當每一個請求到來的時候,它都會建立一個執行緒池,直到系統再也無法分配資源為止。
可真是霸道啊。
所有人都在關注線程池的參數是怎麼設定的,但從來沒有人懷疑這段程式碼的位置。
以上是伺服器故障實例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















