


GPT-4 的識圖能力什麼時候能上線呢?這個問題目前依然沒有答案。
但研究社群等不及了,紛紛自己上手 DIY,其中最熱門的是名為 MiniGPT-4 的計畫。 MiniGPT-4 展示了許多類似於 GPT-4 的能力,例如產生詳細的圖像描述並從手寫草稿創建網站。此外,作者還觀察到 MiniGPT-4 的其他新興能力,包括根據給定的圖像創作故事和詩歌,提供解決圖像中顯示的問題的解決方案,根據食品照片教導使用者如何烹飪等。該專案上線 3 天就拿到了近一萬的 Star 量。

今天要介紹的計畫-LLaVA(Large Language and Vision Assistant)與之類似,是個由威斯康辛大學麥迪遜分校、微軟研究院和哥倫比亞大學研究者共同發表的多模態大模型。

#該模型顯示出了一些接近多模態GPT-4 的圖文理解能力:相對於GPT-4 獲得了85.1% 的相對得分。當在科學問答(Science QA)上進行微調時,LLaVA 和 GPT-4 的協同作用實現了 92.53% 準確率的新 SoTA。

以下是機器之心的試用結果(更多結果請見文末):

人類透過視覺和語言等多種管道與世界交互,因為不同的管道在代表和傳達某些概念時都有各自獨特的優勢,多通道的方式有利於更好地理解世界。人工智慧的核心願望之一是發展一個通用的助手,能夠有效地遵循多模態指令,例如視覺或語言的指令,滿足人類的意圖,在真實環境中完成各種任務。
為此,社群興起了開發基於語言增強的視覺模型的風潮。這類模型在開放世界視覺理解方面具有強大的能力,如分類、偵測、分割和圖文,以及視覺生成和視覺編輯能力。每個任務都由一個大型視覺模型獨立解決,在模型設計中隱含地考慮了任務的需求。此外,語言僅用於描述圖像內容。雖然這使得語言在將視覺訊號映射到語言語義(人類溝通的常見管道)方面發揮了重要作用,但它導致模型通常具有固定的介面,在互動性和對使用者指令的適應性上存在限制。
另一方面,大型語言模型(LLM)已經表明,語言可以發揮更廣泛的作用:作為通用智慧助理的通用互動介面。在通用介面中,各種任務指令可以用語言明確表示,並引導端對端訓練的神經網路助理切換模式來完成任務。例如,ChatGPT 和 GPT-4 最近的成功證明了 LLM 在遵循人類指令完成任務方面的能量,並掀起了開發開源 LLM 的熱潮。其中,LLaMA 是一種與 GPT-3 效能相近的開源 LLM。 Alpaca、Vicuna、GPT-4-LLM 利用各種機器產生的高品質指令追蹤樣本來提高 LLM 的對齊能力,與專有 LLM 相比,展現了令人印象深刻的性能。但遺憾的是,這些模型的輸入僅為文字。
在本文中,研究者提出了視覺 instruction-tuning 方法,首次嘗試將 instruction-tuning 擴展到多模態空間,為建構通用視覺助理鋪平了道路。
具體來說,本文做出了以下貢獻:
本文的主要目標是有效利用預先訓練的 LLM 和視覺模型的功能。網路架構如圖 1 所示。本文選擇 LLaMA 模型作為 LLM fφ(・),因為它的有效性已經在幾個開源的純語言 instruction-tuning 工作中得到了證明。

對於輸入影像X_v,本文使用預先訓練的CLIP 視覺編碼器ViT-L/14 進行處理,得到視覺特徵Z_v=g ( X_v)。實驗中使用的是最後一個 Transformer 層之前和之後的網格特徵。本文使用一個簡單的線性圖層來將影像特徵連接到單字嵌入空間。具體而言,應用可訓練投影矩陣W 將Z_v 轉換為語言嵌入標記H_q,H_q 具有與語言模型中的單字嵌入空間相同的維度:
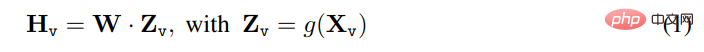
之後,得到一系列視覺標記H_v。這種簡單投影方案具有輕量、成本低等特點,能夠快速迭代以資料為中心的實驗。也可以考慮連接影像和語言特徵的更複雜(但昂貴)的方案,例如Flamingo 中的門控交叉注意力機制和BLIP-2 中的Q-former,或提供物件層級特徵的其他視覺編碼器,如SAM。
多模態聊天機器人
#研究者開發了一個聊天機器人範例產品,以展示LLaVA 的影像理解和對話能力。為了進一步研究 LLaVA 如何處理視覺輸入,展現其處理指令的能力,研究者首先使用 GPT-4 原始論文中的範例,如表 4 和表 5 所示。使用的 prompt 需要貼合影像內容。為了進行比較,本文引用了其論文中多模態模型 GPT-4 的 prompt 和結果。


令人驚訝的是,儘管LLaVA 是用一個小的多模態指令資料集(約80K 的不重複影像)訓練的,但它在上述這兩個範例上展示了與多模態模型GPT-4 非常相似的推理結果。請注意,這兩張圖像都不在 LLaVA 的資料集範圍內,LLaVA 能夠理解場景並按照問題說明進行回答。相較之下,BLIP-2 和 OpenFlamingo 專注於描述影像,而不是按照使用者指示以適當的方式回答。更多示例如圖 3、圖 4 和圖 5 所示。



#量化評估結果如表 3。

ScienceQA
#ScienceQA 包含21k 個多模態多選問題,涉及3 個主題、26 個主題、127 個類別和379 種技能,具有豐富的領域多樣性。基準資料集分為訓練、驗證和測試部分,分別有 12726、4241 和 4241 個樣本。本文比較了兩種具代表性的方法,包括GPT-3.5 模型(text-davinci-002)和沒有思考鏈(CoT)版本的GPT-3.5 模型,LLaMA-Adapter,以及多模態思考鏈(MM- CoT)[57],這是該資料集上目前的SoTA 方法,結果如表6 所示。

在論文給出的視覺化使用頁面上,機器之心也嘗試輸入了一些圖片和指令。首先是問答裡常見的數人任務。測試表明,數人的時候較小的目標會被忽略,重疊的人也有識別誤差,性別也有識別誤差。


接著,我們嘗試了一些生成任務,例如為圖片起名字,或根據圖片講一個故事。模型輸出的結果還是偏向圖片內容理解,生成方面的能力仍有待加強。


在這張照片中,即便人體有重疊也依然能準確地辨識出人數。從圖片描述和理解能力的角度來看,本文的工作還是有亮點,存在著二創的空間。
以上是熔岩羊駝LLaVA來了:像GPT-4一樣可以看圖聊天,無需邀請碼,在線可玩的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















