

其實正則化的本質很簡單,就是對某一問題加以先驗的限製或約束以達到某種特定目的的一種手段或操作。在演算法中使用正規化的目的是防止模型出現過擬合。一提到正規化,很多同學可能馬上會想到常用的L1範數和L2範數,在總結之前,我們先看下LP範數是什麼?
範數簡單可以理解為用來表徵向量空間中的距離,而距離的定義很抽象,只要滿足非負、自反、三角不等式就可以稱之為距離。
LP範數不是一個範數,而是一組範數,其定義如下:

p的範圍是[1,∞)。 p在(0,1)範圍內定義的並不是範數,因為違反了三角不等式。
根據pp的變化,範數也有不同的變化,借用一個經典的有關P範數的變化圖如下:

那問題來了,L0範數是啥玩意? L0範數表示向量中非零元素的個數,用公式表示如下:


 L2範數有很多名稱,有人把它的回歸叫做「嶺回歸」(Ridge Regression),也有人叫它「權值衰減」(Weight Decay)。以L2範數作為正則項可以得到稠密解,即每個特徵對應的參數ww都很小,接近於0但是不為0;此外,L2範數作為正則化項,可以防止模型為了迎合訓練集而過於複雜造成過擬合的情況,進而提高模型的泛化能力。
L2範數有很多名稱,有人把它的回歸叫做「嶺回歸」(Ridge Regression),也有人叫它「權值衰減」(Weight Decay)。以L2範數作為正則項可以得到稠密解,即每個特徵對應的參數ww都很小,接近於0但是不為0;此外,L2範數作為正則化項,可以防止模型為了迎合訓練集而過於複雜造成過擬合的情況,進而提高模型的泛化能力。
L1範數和L2範數的區別

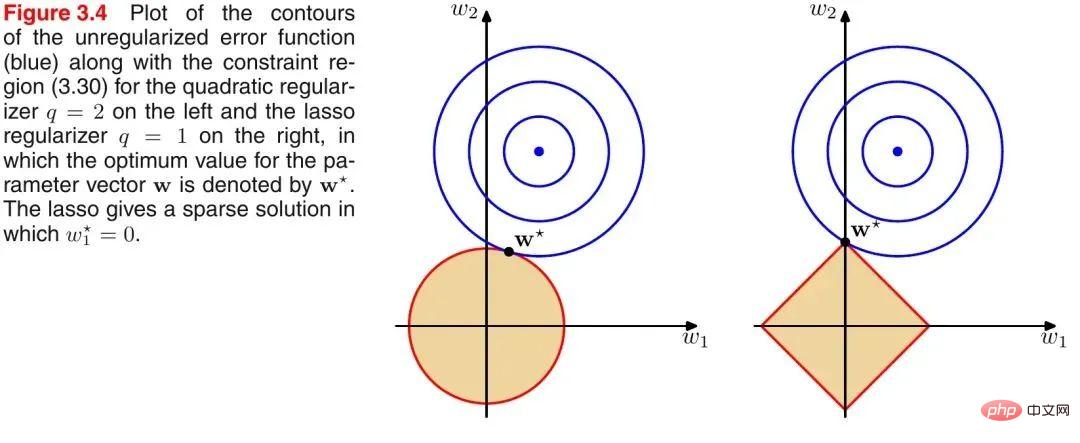 如上圖所示,藍色的圓圈表示問題可能的解範圍,橘色的表示正規項可能的解範圍。而整個目標函數(原問題 正規項)有解當且僅當兩個解範圍相切。從上圖可以很容易地看出,由於L2範數解範圍是圓,所以相切的點有很大可能不在座標軸上,而由於L1範數是菱形(頂點是凸出來的),其相切的點更可能在座標軸上,而座標軸上的點有一個特點,其只有一個座標分量不為零,其他座標分量為零,即是稀疏的。所以有以下結論,L1範數可以導致稀疏解,L2範數導致稠密解。
如上圖所示,藍色的圓圈表示問題可能的解範圍,橘色的表示正規項可能的解範圍。而整個目標函數(原問題 正規項)有解當且僅當兩個解範圍相切。從上圖可以很容易地看出,由於L2範數解範圍是圓,所以相切的點有很大可能不在座標軸上,而由於L1範數是菱形(頂點是凸出來的),其相切的點更可能在座標軸上,而座標軸上的點有一個特點,其只有一個座標分量不為零,其他座標分量為零,即是稀疏的。所以有以下結論,L1範數可以導致稀疏解,L2範數導致稠密解。
從貝葉斯先驗的角度看,當訓練一個模型時,僅依靠當前的訓練資料集是不夠的,為了實現更好的泛化能力,往往需要加入先驗項,而加入正規項相當於加入了一種先驗。
如下圖所示:

Dropout是深度學習中常採用的正規化方法。它的做法可以簡單的理解為在DNNs訓練的過程中以機率pp丟棄部分神經元,即使得被丟棄的神經元輸出為0。 Dropout可以實例化的表示為下圖:

我們可以從兩個面向直觀地理解Dropout的正規化效果:
批次規範化(Batch Normalization)嚴格意義上來說屬於歸一化手段,主要用於加速網路的收斂,但也具有一定程度的正則化效果。
這裡借鏡下魏秀參博士的知乎回答中對covariate shift的解釋。
註:以下內容引自魏秀參博士的知乎回答大家都知道在統計機器學習中的一個經典假設是「來源空間(source domain)和目標空間(target domain)的資料分佈(distribution)是一致的」。如果不一致,那麼就出現了新的機器學習問題,如transfer learning/domain adaptation等。而covariate shift就是分佈不一致假設之下的一個分支問題,它是指源空間和目標空間的條件機率是一致的,但是其邊緣機率不同。大家細想便會發現,的確,對於神經網路的各層輸出,由於它們經過了層內操作作用,其分佈顯然與各層對應的輸入訊號分佈不同,而且差異會隨著網路深度增大而增大,可是它們所能「指示」的樣本標記(label)仍然是不變的,這便符合了covariate shift的定義。
BN的基本思想其實相當直觀,因為神經網路在做非線性變換前的激活輸入值(X=WU B,U是輸入)隨著網路深度加深,其分佈逐漸發生偏移或者變動(即上述的covariate shift)。之所以訓練收斂慢,一般是整體分佈逐漸往非線性函數的值區間的上下限兩端靠近(對於Sigmoid函數來說,意味著激活輸入值X=WU B是大的負值或正值) ,所以這導致後向傳播時低層神經網路的梯度消失,這是訓練深層神經網路收斂越來越慢的本質原因。而BN就是透過一定的規範化手段,把每層神經網路任意神經元這個輸入值的分佈強行拉回到均值為0方差為1的標準正態分佈,避免因為激活函數導致的梯度彌散問題。所以與其說BN的作用是緩解covariate shift,倒不如說BN可緩解梯度彌散問題。
正則化我們以及提到過了,這裡簡單提一下歸一化和標準化。歸一化(Normalization):歸一化的目標是找到某種映射關係,將原始資料映射到[a,b]區間。一般a,b會取[−1,1],[0,1]這些組合。一般有兩種應用場景:
常用min-max normalization:

#標準化(Standardization):以大數定理將資料轉換為標準常態分佈,標準化公式為:

我們可以這樣簡單地解釋:歸一化的縮放是「拍扁」統一到區間(僅由極值決定),而標準化的縮放是更「彈性」和「動態」的,和整體樣本的分佈有很大的關係。值得注意:


以上是機器學習必備:如何防止過擬合?的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































