

今年的就業形式簡直一片黑暗,本著明年會比今年還差的“僥倖心理”,我還是毫不猶豫地選擇裸辭了,歷經一個半月的努力,收到了還算不錯的offer,薪資和平台都有比較大的提升,但還是和自己的心理預期有著很大的差距。所以得出最大的結論就是:不要裸辭!不要裸辭!不要裸辭!因為面試期間帶給人的壓力,和現實與理想的落差對心理的摧殘是不可估量的,在這樣一個環境苟著是不錯的選擇。
相關推薦:2023年大前端面試題總結(收藏)
接下來總結一般情況下前端面試中會經歷的以下四個階段和三個決定因素:
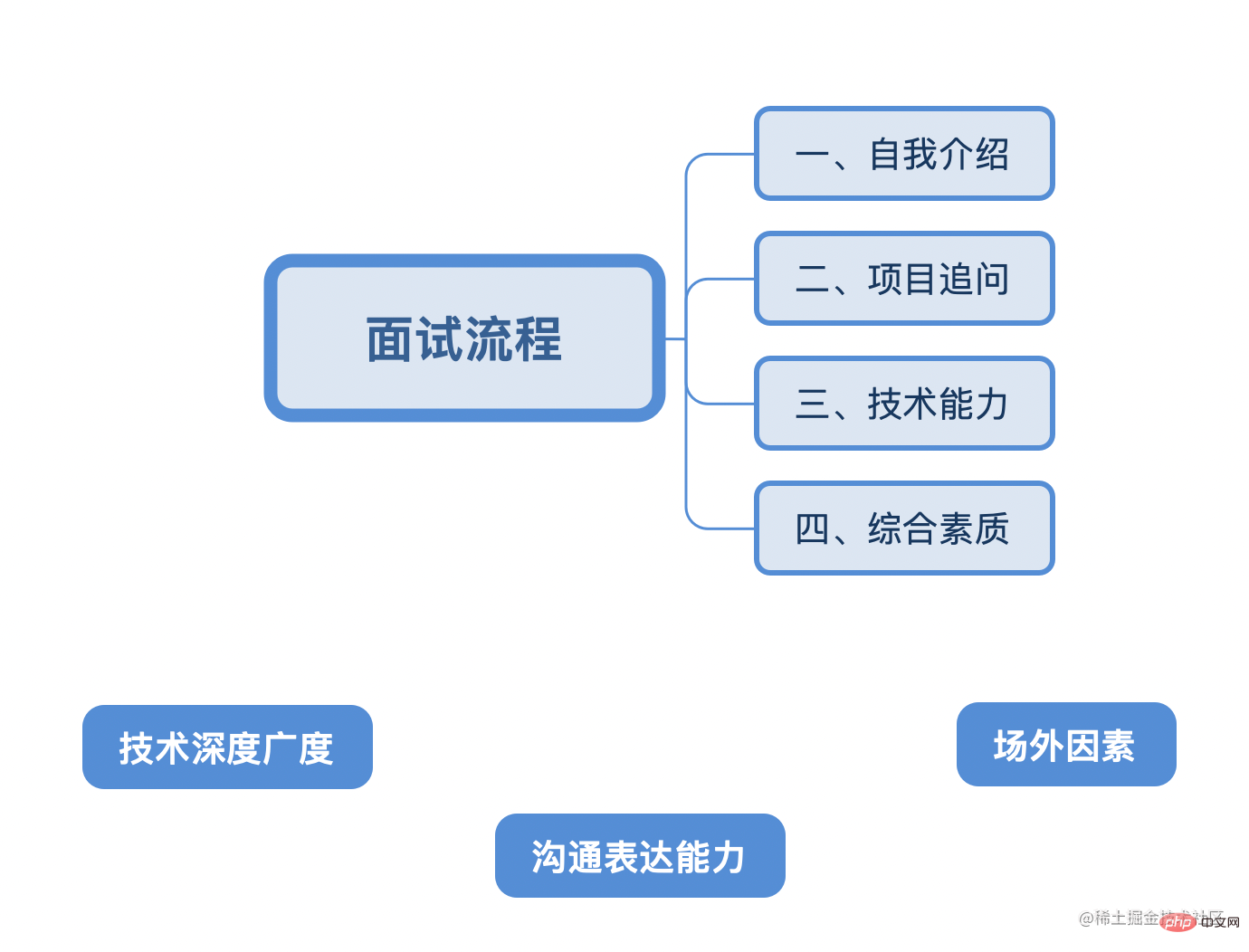 作為前端人員,技術的深度廣度是排在第一位的,三年是一個分割線,一定要在這個時候找準自己的定位和方向。
作為前端人員,技術的深度廣度是排在第一位的,三年是一個分割線,一定要在這個時候找準自己的定位和方向。
其次良好的溝通表達能力、穿著和表現等場外因素能提高面試官對你的認可度。
有的人技術很牛逼,但是面試時讓面試官覺得不爽,覺得你盛氣逼人/形象邋遢/自以為是/表述不清,就直接不要你,那是最得不償失的。
以下是我整個面試準備以及被問到過的問題的一個凝練,因為在面試過程中,和麵試官的交流很大程度並不是簡單的背書,最好是要將知識通過自己的總結和凝練表達出來,再根據面試官的提問臨場發揮將之補足完善。 【推薦學習:web前端、程式設計教學】
面試官讓你自我介紹,而且不限定自我介紹的範圍,肯定是面試官想從你的自我介紹中了解到你,所以介紹一定要保證簡短和流暢,面對不同的面試官,自我介紹的內容可以是完全一樣的,所以事先準備好說辭很重要,一定要注意:不要磕磕巴巴,要自信! 流暢的表達和溝通能力,同樣是面試官會對候選人考核點之一。我也曾當過面試官,自信大方的候選人,往往更容易受到青睞。
1、個人介紹(基本情況),主要的履歷都有了,這方面一定要短
2、個人擅長什麼,包括技術上的和非技術上的。技術上可以了解你的轉場,非技術可以了解你這個人
3、做過的項目,撿最核心的項目說,不要把所有項目像背書一樣介紹
4、自己的一些想法、興趣或觀點,甚至包括自己的職涯規劃。這要是給面試官一個感覺:熱衷於"折騰"或"思考"
示例:
面試官您好,我叫xxx,xx年畢業於xx大學,自畢業以來一直從事前端開發的相關工作。
我擅長的技術堆疊是vue 全家桶,對vue2 和vue3 在使用上和原始碼都有一定程度的鑽研;打包工具對webpack 和vite 都比較熟悉;有從零到一主導中大型專案落地的經驗與能力。
在上家公司主要是xx產品線負責人的角色,主要職責是。 。 。 。 。 。
除了開發相關工作,還有一定的技術管理經驗:例如擔任需求評審、UI/UE交互評審評委,負責開發排期、成員協作、對成員代碼進行review、組織例會等等
平常會在自己建立的部落格上記錄一些學習文章或學習筆記,也會寫一些原創的技術文章發表到掘金上,獲得過xx獎。
總的來說自我介紹盡量控制在3 - 5分鐘之間,簡潔扼要為第一要義,其次是突出自己的能力和長處。
對於普通的技術面試官來說,自我介紹只是習慣性的面試前的開場白,一般簡歷上列舉的基本信息已經滿足他們對你的基本了解了。但對於主管級的面試官或Hr,會看重你的個性、行為習慣、抗壓能力等等綜合能力。所以要讓自己在面試過程盡可能表現的正面,愛好廣泛、喜歡持續學習,喜歡團隊合作,可以無條件加班等等。當然也不是說讓你去欺騙,只是在現在這種環境中,這些「側面能力」也是能在某種程度上提升自己競爭力的法寶。
在目前這個行情,當你收到面試通知時,有很大機率是因為你的專案經驗和招募的職位比較符合。 所以在專案的準備上要額外上心,例如:
對專案中使用到的技術的深挖
對專案整體設計思路的把控
#對專案運作流程的管理
團隊協作的能力。
專案的最佳化點有哪些
這些因人而異就不做贅述了,根據自己的情況好好挖掘即可。
先說個人,當你通過了技術面試,到了主管和hr這一步,不管你目前的技術多牛逼,他們會額外檢視你個人的潛力、學習能力、性格與團隊的磨合等軟實力,這裡列出一些很容易被問到的:
直接從個人發展入手錶現出自己的上進心:
一直想去更大的平台,不僅有更好的技術氛圍,而且學到的東西也更多
1、善於規劃和總結,我會對自己經手的項目進行一個全面的分析,一個是業務拆解,對個各模組的業務透過腦圖進行拆解;另一個就是對程式碼模組的拆解,依功能去區分各個程式碼模組。再去進行開發。我覺得這是很多只會進行盲目業務開發的前端做不到的
2、喜歡專研技術,平常對vue 的源碼一直在學習,也有輸出自己的技術文章,像之前寫過一篇逐行精讀teleport 的源碼,花了大約有三十個小時才寫出來的,對每一行源碼的功能和作用進行了解讀(但是為啥閱讀和點贊這麼低) 。
性子比較沉,更偏內向一點,所以我也會試著讓自己變得外向一點。
一個是要開各種評審會,身為前端代表需要我去準備各種資料和發言。
所以在團隊內做比較多的技術分享,每週主持例會,也讓我敢於表達和探討。
套件依賴管理工具pnpm(不會重複安裝依賴,非扁平的node_modules結構,符號連結方式加入依賴套件)
打包工具vite (極速的開發環境)
flutter (Google推出並開源的行動應用程式(App)開發框架,主打跨平台、高保真、高效能)
rust(聽說是js未來的基座)
turbopack,webpack的繼任者,說是比vite快10倍,webpack快700倍,然後尤雨溪親自驗證其實並沒有比vite 快10倍
#webcomponents
落實開發規範,我在公司內部 wiki 上有發過,從命名、最佳實務到各種工具庫的使用。新人進來前期我會優先跟進他們的程式碼品質
1、團隊分工:每個人單獨負責一個產品的開發,然後公共模組一般我會指定某幾個人開發
2、程式碼品質保證:每週會review他們的程式碼,也會整理交叉review 程式碼,將修改結果輸出文章放到wiki中
3、組織例會:每週組織例會同步各自進度和風險,根據各自的進度調配工作任務
4、技術分享:也會組織不定時的技術分享。一開始就是單純的我做分享,像是微前端的體系,ice stark 的源碼
#5、公共需求池:例如webpack5/vite的升級;vue2.7的升級引入setup語法糖;pnpm的使用;拓樸圖效能優化
6、優化專案:在第一版產品出來之後,我還發起過效能最佳化專案,首屏載入效能,打包體積優化;讓每個人去負責對應的最佳化項目
我覺得加班一般會有兩種情況:
一是專案進度比較緊,那當然以專案進度為先,畢竟大家都靠這個吃飯
二是自身能力問題,對業務不熟啊或引入一個全新的技術棧,那麼我覺得不僅要加班跟上,還要去利用空閒時間抓緊學習,彌補自己的不足
我平常喜歡閱讀,就是在微信閱讀裡讀一些心理學、時間管理、還有一些演講技巧之類的書
#然後是寫文章,因為我發現單純的記筆記很容易就忘了,因為只是記載別人的內容,而寫自己的原創文章,在這個過程中能將知識非常高的比例轉換成自身的東西,所以除了自個發掘金的文章,我也常常會對專案的產出有文章輸出到wiki 上
其他嗜好就是和朋友約著打籃球、唱歌
#技術面試一定要注意:簡明扼要,詳略得當,不懂的就說不懂。因為在面試過程中是一個和麵試官面對面交流的過程,沒有面試官會喜歡一個絮絮叨叨半天說不到重點候選人,同時在說話過程中,聽者會被動的忽略自己不感興趣的部分,所以要著重突出某個技術的核心特點,並圍繞著核心適當展開。
大廠基本上都會透過演算法題來篩選候選人,演算法沒有捷徑,只能一步一步地刷題再刷題,這方面薄弱的要提前規劃進行個學習了。
技術面過程主要會對前端領域相關的技術進行提問,一般面試官會基於你的建立,而更多的是,面試官基於他之前準備好的面試題,或者所在專案組比較熟悉的技術點來提問,因為都是未知數,所以各方面都還是要求比較足的。
如果想進入一個中大型且發展前景不錯的公司,並不是照著別人的面經背一背就能糊弄過去的,這裡作出的總結雖然每一條都很簡短,但都是我對每一個知識點進行全面學習後才提煉出來的部分核心知識點,所以不懼怕面試官的「發散一下思維」。
面試過程一般會涉及以下八大知識類型的考量:
JS/CSS/TypeScript/框架(Vue、React)/瀏覽器與網路/效能最佳化/前端工程化/架構/其他
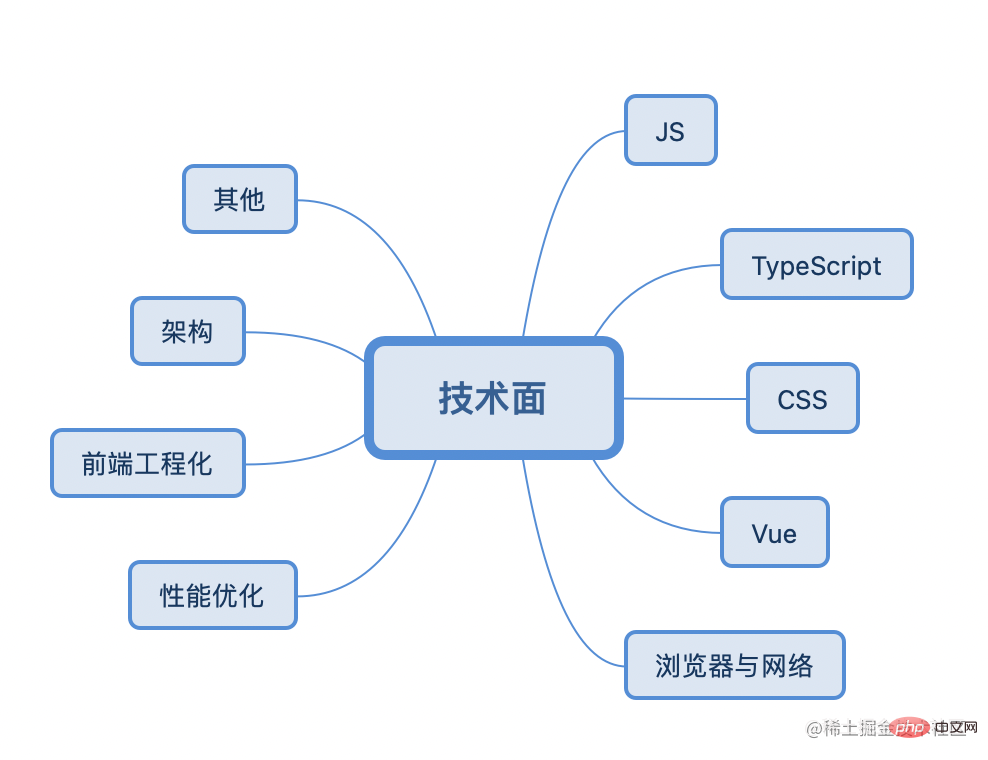
所以面試前的技術準備絕不是一蹴而就,還需要平時的積累,例如可以利用每天十到二十分鐘對其中一個小知識點進行全面的學習,長此以往,無論是幾年的面試,都足夠侃侃而談。
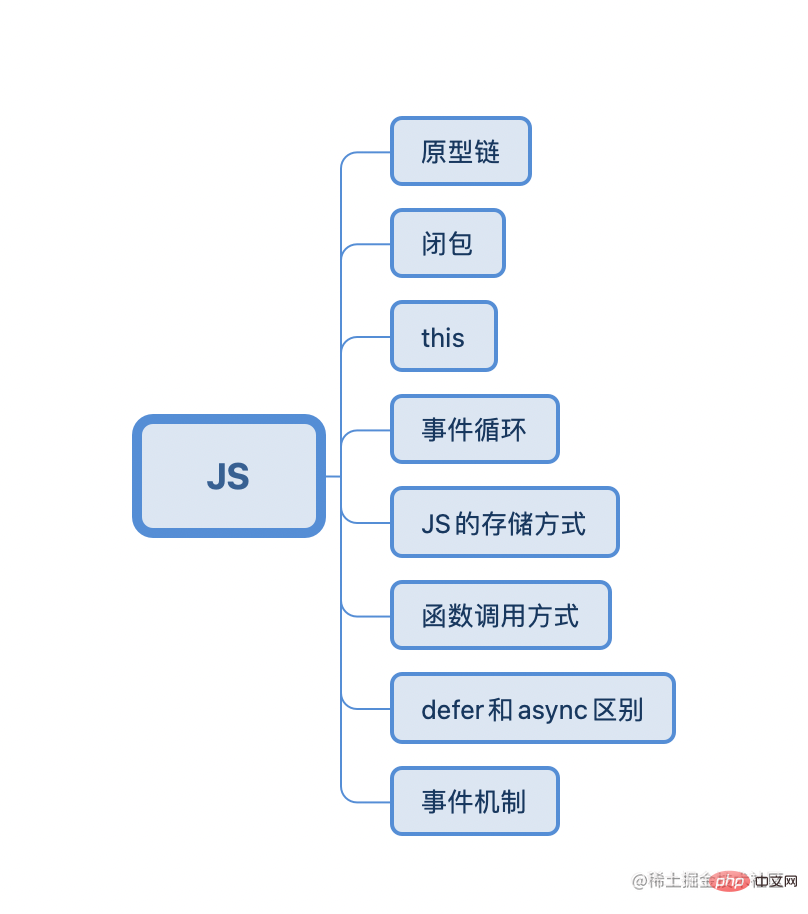
JS的學習梭哈紅包書和冴羽老師的深入JS系列部落格就基本ok了
#常見的JS面試題通常會有這些
原型的本質就是一個物件。
當我們在建立一個建構函式之後,這個函式會預設帶一個prototype屬性,而這個屬性的值就指向這個函式的原型物件。
這個原型物件是用來為透過該建構函式所建立的實例物件提供共用屬性,也就是用來實作基於原型的繼承和屬性的共用
所以我們透過建構子所建立的實例物件都會從這個函數的原型物件上繼承上面具有的屬性
當讀取實例的屬性時,如果找不到,就會尋找與物件關聯的原型中的屬性,如果還查不到,就去找原型的原型,一直找到最頂層為止(最頂層就是Object.prototype的原型,值為null)。
所以透過原型一層層相互關聯的鏈狀結構就稱為原型鏈。
定義:閉包是指引用了其他函數作用域中變數的函數,通常是在巢狀函數中實現的。
從技術角度上所有 js 函數都是閉包。
從實踐角度來看,滿足以下兩個條件的函數算閉包
#即使創建它的上下文被銷毀了,它依然存在。 (例如從父函數中返回)
在程式碼中引用了自由變數(在函數中使用的既不是函數參數也不是函數局部變數的變數稱作自由變數)
使用場景:
#建立私有變數
vue 中的data,需要是一個閉包,保證每個data中資料唯一,避免多次引用該組件造成的data共享
延長變數的生命週期
一般函數的詞法環境在函數返回後就被銷毀,但是閉包會保存對創建時所在詞法環境的引用,即便創建時所在的執行上下文被銷毀,但創建時所在詞法環境依然存在,以達到延長變量的生命週期的目的
應用程式
在絕大多數情況下,函數的呼叫方式決定了this 的值(運行時綁定)
1、全域的this非嚴格模式指向window對象,嚴格模式指向undefined
2、對象的屬性方法中的this 指向對象本身
#3、apply、call、bind可以變更this 指向為第一個傳參
4、箭頭函數中的this指向它的父級作用域,它本身不存在this
js 程式碼執行過程中,會建立對應的執行上下文並壓入執行上下文堆疊中。
如果遇到非同步任務就會將任務掛起,交給其他執行緒去處理非同步任務,當非同步任務處理完後,會將回呼結果加入事件佇列中。
當執行堆疊中所有任務執行完畢後,就是主執行緒處於閒置狀態時,才會從事件佇列中取出排在首位的事件回呼結果,並將這個回呼加入執行棧中然後執行其中的程式碼,如此反复,這個過程就被稱為事件循環。
事件佇列分為了宏任務佇列和微任務佇列,在目前執行端為空時,主執行緒回先查看微任務佇列是否有事件存在,存在則依序執行微任務佇列中的事件回調,直到微任務佇列為空;不存在再去巨集任務佇列中處理。
常見的巨集任務有setTimeout()、setInterval()、setImmediate()、I/O 、使用者互動操作,UI渲染
常見的微任務有promise.then()、promise.catch()、new MutationObserver、process.nextTick()
宏任務和微任務的本質差異
1、普通function直接使用()呼叫並傳參,如:function test(x, y) { return x y},test(3, 4)
2、作為物件的一個屬性方法調用,如:const obj = { test: function (val) { return val } }, obj.test(2)
3、使用call或apply調用,更改函數this 指向,也就是更改函數的執行上下文
4、new可以間接調用建構函數生成物件實例
一般情況下,執行到script 標籤時會進行下載執行兩個步驟操作,這兩個步驟會阻塞HTML 的解析;
async 和defer 能將script的下載階段變成非同步執行(和html解析同步進行);
async下載完成後會立即執行js,此時會阻塞HTML解析;
defer會等全部HTML解析完成且在DOMContentLoaded 事件前執行。
DOM 事件流三階段:
## 擷取階段:事件最開始由不太具體的節點最早接受事件, 而最具體的節點(觸發節點)最後接受事件。為了讓事件到達最終目標之前攔截事件。
例如點選一個div,則click 事件會以這種順序觸發: document => =>
=> ; ,即由document 捕獲後沿著DOM 樹依次向下傳播,並在各節點上觸發捕獲事件,直到到達實際目標元素。 目標階段
當事件到達目標節點的,事件就進入了目標階段。事件在目標節點上被觸發(執行事件對應的函數),然後會逆向回流,直到傳播至最外層的文檔節點。
冒泡階段
事件在目標元素上觸發後,會繼續隨著DOM 樹一層層往上冒泡,直到到達最外層的根節點。擴充一
e.target 和e.currentTarget 差別? 指向觸發事件監聽的物件。
指向新增監聽事件的物件。
<ul>
<li><span>hello 1</span></li>
</ul>
let ul = document.querySelectorAll('ul')[0]
let aLi = document.querySelectorAll('li')
ul.addEventListener('click',function(e){
let oLi1 = e.target
let oLi2 = e.currentTarget
console.log(oLi1) // 被点击的li
console.log(oLi2) // ul
console.og(oLi1===oLi2) // false
})e.currenttarget和e.target是不相等的,但是在事件的目標階段,e.currenttarget和e.target是相等的
#e.target可以用來實作事件委託,原理是透過事件冒泡(或事件擷取)為父元素新增事件監聽,e.target指向引發觸發事件的元素
擴展二
addEventListener 參數語法:addEventListener(type, listener); addEventListener(type, listener, options || useCapture);
,當它的abort()方法被呼叫時,監聽器會被移除筆主是主要從事Vue相關開發的,也做過react 相關的項目,當然react 也只是能做項目的水平,所以在履歷表中屬於一筆帶過的那種,框架貴不在多而在精,對Vue源碼系列的學習讓我對Vue還是十分自信的。學習過程也是如此,如果你能夠對一門框架達到精通原理的掌握程度,學習其他框架不過只是花時間的事情。
#1、資料可變性
setState或onchange來實現視圖更新2、寫法
主要使用diff佇列保存需要更新哪些DOM,得到patch樹,再統一操作批次更新DOM。 ,需要使用shouldComponentUpdate()來手動優化react的渲染。 擴充:了解 react hooks嗎
元件類別的寫法很重,層級一多很難維護。 函數元件是純函數,不能包含狀態,也不支援生命週期方法,因此無法取代類別。React Hooks 的設計目的,就是加強版函數元件,完全不使用"類別",就能寫出一個全功能的元件
React Hooks 的意思是,元件盡量寫成純函數,如果需要外部功能和副作用,就用鉤子把外部程式碼"鉤子"進來。
##/
root
attrs / listenerseventBus / vuex / pinia / localStorage / sessionStorage / Cookie / windowprovide / inject
想详细了解这个知识点的可以去看看我之前写的文章:v-for 到底为啥要加上 key?
vue2使用的是Object.defineProperty去监听对象属性值的变化,但是它不能监听对象属性的新增和删除,所以需要使用$set、$delete这种语法糖去实现,这其实是一种设计上的不足。
所以 vue3 采用了proxy去实现响应式监听对象属性的增删查改。
其实从api的原生性能上proxy是比Object.defineProperty要差的。
而 vue 做的响应式性能优化主要是在将嵌套层级比较深的对象变成响应式的这一过程。
vue2的做法是在组件初始化的时候就递归执行Object.defineProperty把子对象变成响应式的;
而vue3是在访问到子对象属性的时候,才会去将它转换为响应式。这种延时定义子对象响应式会对性能有一定的提升
前提:当同类型的 vnode 的子节点都是一组节点(数组类型)的时候,
步骤:会走核心 diff 流程
Vue3是快速选择算法
Vue2是双端比较算法
在新旧字节点的头尾节点,也就是四个节点之间进行对比,找到可复用的节点,不断向中间靠拢的过程
diff目的:diff 算法的目的就是为了尽可能地复用节点,减少 DOM 频繁创建和删除带来的性能开销
基于 MVVM 模型,viewModel(业务逻辑层)提供了数据变化后更新视图和视图变化后更新数据这样一个功能,就是传统意义上的双向绑定。
Vue2.x 实现双向绑定核心是通过三个模块:Observer监听器、Watcher订阅者和Compile编译器。
首先监听器会监听所有的响应式对象属性,编译器会将模板进行编译,找到里面动态绑定的响应式数据并初始化视图;watchr 会去收集这些依赖;当响应式数据发生变更时Observer就会通知 Watcher;watcher接收到监听器的信号就会执行更新函数去更新视图;
vue3的变更是数据劫持部分使用了porxy 替代 Object.defineProperty,收集的依赖使用组件的副作用渲染函数替代watcher
vue2 v-model 原理剖析
V-model 是用来监听用户事件然后更新数据的语法糖。
其本质还是单向数据流,内部是通过绑定元素的 value 值向下传递数据,然后通过绑定 input 事件,向上接收并处理更新数据。
单向数据流:父组件传递给子组件的值子组件不能修改,只能通过emit事件让父组件自个改。
// 比如 <input v-model="sth" /> // 等价于 <input :value="sth" @input="sth = $event.target.value" />
给组件添加 v-model 属性时,默认会把value 作为组件的属性,把 input作为给组件绑定事件时的事件名:
// 父组件
<my-button v-model="number"></my-button>
// 子组件
<script>
export default {
props: {
value: Number, // 属性名必须是 value
},
methods: {
add() {
this.$emit('input', this.value + 1) // 事件名必须是 input
},
}
}
</script>如果想给绑定的 value 属性和 input 事件换个名称呢?可以这样:
在 Vue 2.2 及以上版本,你可以在定义组件时通过 model 选项的方式来定制 prop/event:
<script>
export default {
model: {
prop: 'num', // 自定义属性名
event: 'addNum' // 自定义事件名
}
}vue3 v-model 原理
实现和 vue2 基本一致
<Son v-model="modalValue"/>
等同于
<Son v-model="modalValue"/>
自定义 model 参数
<Son v-model:visible="visible"/>
setup(props, ctx){
ctx.emit("update:visible", false)
}不管vue2 还是 vue3,响应式的核心就是观察者模式 + 劫持数据的变化,在访问的时候做依赖收集和在修改数据的时候执行收集的依赖并更新数据。具体点就是:
vue2 的话采用的是 Object.definePorperty劫持对象的 get 和 set 方法,每个组件实例都会在渲染时初始化一个 watcher 实例,它会将组件渲染过程中所接触的响应式变量记为依赖,并且保存了组件的更新方法 update。当依赖的 setter 触发时,会通知 watcher 触发组件的 update 方法,从而更新视图。
Vue3 使用的是 ES6 的 proxy,proxy 不仅能够追踪属性的获取和修改,还可以追踪对象的增删,这在 vue2中需要 delete 才能实现。然后就是收集的依赖是用组件的副作用渲染函数替代 watcher 实例。
性能方面,从原生 api 角度,proxy 这个方法的性能是不如 Object.property,但是 vue3 强就强在一个是上面提到的可以追踪对象的增删,第二个是对嵌套对象的处理上是访问到具体属性才会把那个对象属性给转换成响应式,而 vue2 是在初始化的时候就递归调用将整个对象和他的属性都变成响应式,这部分就差了。
扩展一
vue2 通过数组下标更改数组视图为什么不会更新?
尤大:性能不好
注意:vue3 是没问题的
why 性能不好?
我们看一下响应式处理:
export class Observer {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
// 这里对数组进行单独处理
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)
} else {
// 对对象遍历所有键值
this.walk(value)
}
}
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i])
}
}
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}对于对象是通过Object.keys()遍历全部的键值,对数组只是observe监听已有的元素,所以通过下标更改不会触发响应式更新。
理由是数组的键相较对象多很多,当数组数据大的时候性能会很拉胯。所以不开放
Computed 的大体实现和普通的响应式数据是一致的,不过加了延时计算和缓存的功能:
在访问computed对象的时候,会触发 getter ,初始化的时候将 computed 属性创建的 watcher (vue3是副作用渲染函数)添加到与之相关的响应式数据的依赖收集器中(dep),然后根据里面一个叫 dirty 的属性判断是否要收集依赖,不需要的话直接返回上一次的计算结果,需要的话就执行更新重新渲染视图。
watchEffect?
watchEffect会自动收集回调函数中响应式变量的依赖。并在首次自动执行
推荐在大部分时候用 watch 显式的指定依赖以避免不必要的重复触发,也避免在后续代码修改或重构时不小心引入新的依赖。watchEffect 适用于一些逻辑相对简单,依赖源和逻辑强相关的场景(或者懒惰的场景 )
vue有个机制,更新 DOM 是异步执行的,当数据变化会产生一个异步更行队列,要等异步队列结束后才会统一进行更新视图,所以改了数据之后立即去拿 dom 还没有更新就会拿不到最新数据。所以提供了一个 nextTick 函数,它的回调函数会在DOM 更新后立即执行。
nextTick 本质上是个异步任务,由于事件循环机制,异步任务的回调总是在同步任务执行完成后才得到执行。所以源码实现就是根据环境创建异步函数比如 Promise.then(浏览器不支持promise就会用MutationObserver,浏览器不支持MutationObserver就会用setTimeout),然后调用异步函数执行回调队列。
所以项目中不使用$nextTick的话也可以直接使用Promise.then或者SetTimeout实现相同的效果
1、全局错误处理:Vue.config.errorHandler
Vue.config.errorHandler = function(err, vm, info) {};
如果在组件渲染时出现运行错误,错误将会被传递至全局Vue.config.errorHandler 配置函数 (如果已设置)。
比如前端监控领域的 sentry,就是利用这个钩子函数进行的 vue 相关异常捕捉处理
2、全局警告处理:Vue.config.warnHandler
Vue.config.warnHandler = function(msg, vm, trace) {};注意:仅在开发环境生效
像在模板中引用一个没有定义的变量,它就会有warning
3、单个vue 实例错误处理:renderError
const app = new Vue({
el: "#app",
renderError(h, err) {
return h("pre", { style: { color: "red" } }, err.stack);
}
});和组件相关,只适用于开发环境,这个用处不是很大,不如直接看控制台
4、子孙组件错误处理:errorCaptured
Vue.component("cat", {
template: `<div><slot></slot></div>`,
props: { name: { type: string } },
errorCaptured(err, vm, info) {
console.log(`cat EC: ${err.toString()}\ninfo: ${info}`);
return false;
}
});注:只能在组件内部使用,用于捕获子孙组件的错误,一般可以用于组件开发过程中的错误处理
5、终极错误捕捉:window.onerror
window.onerror = function(message, source, line, column, error) {};它是一个全局的异常处理函数,可以抓取所有的 JavaScript 异常
Vuex 利用 vue 的mixin 机制,在beforeCreate 钩子前混入了 vuexinit 方法,这个方法实现了将 store 注入 vue 实例当中,并注册了 store 的引用属性 store.xxx`去引入vuex中定义的内容。
然后 state 是利用 vue 的 data,通过new Vue({data: {$$state: state}} 将 state 转换成响应式对象,然后使用 computed 函数实时计算 getter
概念
可以通过全局方法Vue.use()注册插件,并能阻止多次注册相同插件,它需要在new Vue之前使用。
该方法第一个参数必须是Object或Function类型的参数。如果是Object那么该Object需要定义一个install方法;如果是Function那么这个函数就被当做install方法。
Vue.use()执行就是执行install方法,其他传参会作为install方法的参数执行。
所以**Vue.use()本质就是执行需要注入插件的install方法**。
源码实现
export function initUse (Vue: GlobalAPI) {
Vue.use = function (plugin: Function | Object) {
const installedPlugins = (this._installedPlugins || (this._installedPlugins = []))
// 避免重复注册
if (installedPlugins.indexOf(plugin) > -1) {
return this
}
// 获取传入的第一个参数
const args = toArray(arguments, 1)
args.unshift(this)
if (typeof plugin.install === 'function') {
// 如果传入对象中的install属性是个函数则直接执行
plugin.install.apply(plugin, args)
} else if (typeof plugin === 'function') {
// 如果传入的是函数,则直接(作为install方法)执行
plugin.apply(null, args)
}
// 将已经注册的插件推入全局installedPlugins中
installedPlugins.push(plugin)
return this
}
}使用方式
installedPlugins import Vue from 'vue' import Element from 'element-ui' Vue.use(Element)
要暴露一个install方法,第一个参数是Vue构造器,第二个参数是一个可选的配置项对象
Myplugin.install = function(Vue, options = {}) {
// 1、添加全局方法或属性
Vue.myGlobalMethod = function() {}
// 2、添加全局服务
Vue.directive('my-directive', {
bind(el, binding, vnode, pldVnode) {}
})
// 3、注入组件选项
Vue.mixin({
created: function() {}
})
// 4、添加实例方法
Vue.prototype.$myMethod = function(methodOptions) {}
}Css直接面试问答的题目相对来说比较少,更多的是需要你能够当场手敲代码实现功能,一般来说备一些常见的布局,熟练掌握flex基本就没有什么问题了。
Block Formatting context,块级格式上下文
BFC 是一个独立的渲染区域,相当于一个容器,在这个容器中的样式布局不会受到外界的影响。
比如浮动元素、绝对定位、overflow 除 visble 以外的值、display 为 inline/tabel-cells/flex 都能构建 BFC。
常常用于解决
处于同一个 BFC 的元素外边距会产生重叠(此时需要将它们放在不同 BFC 中);
清除浮动(float),使用 BFC 包裹浮动的元素即可
阻止元素被浮动元素覆盖,应用于两列式布局,左边宽度固定,右边内容自适应宽度(左边float,右边 overflow)
伪类
伪类即:当元素处于特定状态时才会运用的特殊类
开头为冒号的选择器,用于选择处于特定状态的元素。比如:first-child选择第一个子元素;:hover悬浮在元素上会显示;:focus用键盘选定元素时激活;:link + :visted点击过的链接的样式;:not用于匹配不符合参数选择器的元素;:fist-child匹配元素的第一个子元素;:disabled 匹配禁用的表单元素
伪元素
伪元素用于创建一些不在文档树中的元素,并为其添加样式。比如说,我们可以通过::before 来在一个元素前增加一些文本,并为这些文本添加样式。虽然用户可以看到这些文本,但是这些文本实际上不在文档树中。示例:
::before 在被选元素前插入内容。需要使用 content 属性来指定要插入的内容。被插入的内容实际上不在文档树中
h1:before {
content: "Hello ";
}::first-line 匹配元素中第一行的文本
href是Hypertext Reference的简写,表示超文本引用,指向网络资源所在位置。href 用于在当前文档和引用资源之间确立联系
src是source的简写,目的是要把文件下载到html页面中去。src 用于替换当前内容
浏览器解析方式
当浏览器遇到href会并行下载资源并且不会停止对当前文档的处理。(同时也是为什么建议使用 link 方式加载 CSS,而不是使用 @import 方式)
当浏览器解析到src ,会暂停其他资源的下载和处理,直到将该资源加载或执行完毕。(这也是script标签为什么放在底部而不是头部的原因)
flex
<div class="wrapper flex-center">
<p>horizontal and vertical</p>
</div>
.wrapper {
width: 900px;
height: 300px;
border: 1px solid #ccc;
}
.flex-center { // 注意是父元素
display: flex;
justify-content: center; // 主轴(竖线)上的对齐方式
align-items: center; // 交叉轴(横轴)上的对齐方式
}flex + margin
<div class="wrapper">
<p>horizontal and vertical</p>
</div>
.wrapper {
width: 900px;
height: 300px;
border: 1px solid #ccc;
display: flex;
}
.wrapper > p {
margin: auto;
}Transform + absolute
<div class="wrapper">
<img src="test.png" alt="三年面試經驗分享:前端面試的四個階段和三個決定因素" >
</div>
.wrapper {
width: 300px;
height: 300px;
border: 1px solid #ccc;
position: relative;
}
.wrapper > img {
position: absolute;
left: 50%;
top: 50%;
tansform: translate(-50%, -50%)
}注:使用该方法只适用于行内元素(a、img、label、br、select等)(宽度随元素的内容变化而变化),用于块级元素(独占一行)会有问题,left/top 的50%是基于图片最左侧的边来移动的,tanslate会将多移动的图片自身的半个长宽移动回去,就实现了水平垂直居中的效果
display: table-cell
<div class="wrapper">
<p>absghjdgalsjdbhaksldjba</p>
</div>
.wrapper {
width: 900px;
height: 300px;
border: 1px solid #ccc;
display: table-cell;
vertical-align: middle;
text-align: center;
}浏览器和网络是八股中最典型的案例了,无论你是几年经验,只要是前端,总会有问到你的浏览器和网络协议。
最好的学习文章是李兵老师的《浏览器工作原理与实践》
这里分了同源页面和不同源页面的通信。
不同源页面可以通过 iframe 作为一个桥梁,因为 iframe 可以指定 origin 来忽略同源限制,所以可以在每个页面都嵌入同一个 iframe 然后监听 iframe 中传递的 message 就可以了。
同源页面的通信大致分为了三类:广播模式、共享存储模式和口口相传模式
第一种广播模式,就是可以通过 BroadCast Channel、Service Worker 或者 localStorage 作为广播,然后去监听广播事件中消息的变化,达到页面通信的效果。
第二种是共享存储模式,我们可以通过Shared Worker 或者 IndexedDB,创建全局共享的数据存储。然后再通过轮询去定时获取这些被存储的数据是否有变更,达到一个的通信效果。像常见cookie 也可以作为实现共享存储达到页面通信的一种方式
最后一种是口口相传模式,这个主要是在使用 window.open 的时候,会返回被打开页面的 window 的引用,而在被打开的页面可以通过 window.opener 获取打开它的页面的 window 点引用,这样,多个页面之间的 window 是能够相互获取到的,传递消息的话通过 postMessage 去传递再做一个事件监听就可以了
在浏览器第一次发起请求服务的过程中,会根据响应报文中的缓存标识决定是否缓存结果,是否将缓存标识和请求结果存入到浏览器缓存中。
HTTP 缓存分为强制缓存和协商缓存两类。
强制缓存就是请求的时候浏览器向缓存查找这次请求的结果,这里分了三种情况,没查找到直接发起请求(和第一次请求一致);查找到了并且缓存结果还没有失效就直接使用缓存结果;查找到但是缓存结果失效了就会使用协商缓存。
强制缓存有 Expires 和 Cache-control 两个缓存标识,Expires 是http/1.0 的字段,是用来指定过期的具体的一个时间(如 Fri, 02 Sep 2022 08:03:35 GMT),当服务器时间和浏览器时间不一致的话,就会出现问题。所以在 http1.1 添加了 cache-control 这个字段,它的值规定了缓存的范围(public/private/no-cache/no-store),也可以规定缓存在xxx时间内失效(max-age=xxx)是个相对值,就能避免了 expires带来的问题。
協商快取就是強制快取的快取結果失效了,瀏覽器攜帶快取標識向伺服器發起請求,有伺服器透過快取識別決定是否使用快取的過程。
控制協商快取的欄位有 last-modified / if-modified-since 和 Etag / if-none-match,後者優先權較高。
大致流程就是透過請求封包傳遞last-modified 或Etag 的值給伺服器與伺服器中對應值作對比,若與回應封包中的if-modified-since 或if-none-match 結果一致,則協商快取有效,使用快取結果,返回304;否則失效,重新請求結果,返回200
connection: keep-alive就可以一直保持連線。
頁面渲染過程(重點記憶)
最後是渲染進程對文件進行頁面解析和子資源加載,渲染進程會將HTML 轉換成DOM 樹結構,將css 轉換成styleSeets ( CSSOM)。然後複製 DOM 樹過濾掉不顯示的元素創建基本的渲染樹,接著計算每個 DOM 節點的樣式和計算每個節點的位置佈局資訊建構成佈局樹。 具有層疊上下文或需要要裁剪的地方會獨立創建圖層,這就是分層,最終會形成一個分層樹,渲染進程會給每個圖層生成繪製列表並提交給合成線程,合成線程將圖層分成圖塊(避免一次繪製圖層所有內容,可以根據圖塊優先需渲染視口部分),並在光柵化線程池中將圖塊轉換成點陣圖。 轉換完畢後合成線程發送繪製圖塊命令 DrawQuard 給瀏覽器進程,瀏覽器根據 DrawQuard 訊息產生頁面,並顯示到瀏覽器上。速記:
瀏覽器的渲染程序將html 解析成dom樹,將css 解析成cssom 樹,然後會先複製一份DOM 樹過濾掉不顯示的元素(如display: none),再和cssom 結合進行計算每個dom 節點的佈局資訊建構成一個佈局樹。 佈局樹產生完畢就會根據圖層的層疊上下文或裁切部分進行分層,形成一個分層樹。 渲染進程再將每個圖層產生繪製列表並提交給合成線程,合成線程為了避免一次性渲染,就是分塊渲染,會將圖層分成圖塊,並透過光柵化線程池將圖塊轉換成點陣圖。 轉換完畢後,合成執行緒將繪製圖塊的指令傳送給瀏覽器進行顯示UDP 是使用者封包協定(User Dataprogram Protocol),IP 透過IP 位址資訊把封包傳送給指定電腦之後,UDP 可以透過連接埠號碼把封包分發給正確的程式。 UDP 可以校驗資料是否正確,但沒有重發的機制,只會丟棄錯誤的資料包,同時 UDP 在發送之後無法確認是否到達目的地。 UDP 無法保證資料的可靠性,但傳輸的速度非常快,通常運用於線上影片、互動遊戲這些較不嚴格保證資料完整性的領域。
TCP 是為了解決UDP 的資料容易遺失,無法正確組裝資料包二引入的傳輸控制協定(Transmission Control Protocol),是一種面向連接的,可靠的,基於位元組流的傳輸層通訊協定。 TCP 在處理封包遺失的情況,提供了重傳機制;並且 TCP 引入了封包排序機制,可以將亂序的封包組合成完整的檔案。
TCP 頭除了包含目標連接埠和本機連接埠號碼外,還提供了用於排序的序號,以便接收端透過序號來重排資料包。
一個 TCP 連線的生命週期會經歷連結階段,資料傳輸和斷開連線階段三個階段。
連接階段
用來建立客戶端和伺服器之間的鏈接,透過三次握手用來確認客戶端、服務端相互之間的資料包收發能力。
1、客戶端先發送SYN 封包用來確認服務端能夠發數據,並進入SYN_SENT 狀態等待服務端確認
2、服務端收到SYN 封包,會向客戶端發送一個ACK 確認封包,同時服務端也會向客戶端發送SYN 封包用來確認客戶端是否能夠發送數據,此時服務端進入SYN_RCVD 狀態
3、客戶端接收到ACK SYN 的封包,就會傳送封包至服務端並進入ESTABLISHED 狀態(建立連線);服務端接收到用戶端傳送的ACK 封包也會進入ESTABLISHED 狀態,完成三次握手
傳輸資料階段
該階段,接收端需要對每個包進行確認操作;
所以當發送端發送了一個資料包之後,在規定時間內沒有接收到接收端回饋的確認訊息,就會判斷為包遺失,從而觸發重發機制;
一個大檔案在傳輸過程中會分成很多個小資料包,封包到達接收端後會根據TCP 頭中的序號為其排序,保證資料的完整。
斷開連線階段
透過四次揮手,來確保雙方的建立的連線能夠斷開
1、客戶端向伺服器發起FIN 包,並進入FIN_WAIT_1 狀態
2、服務端收到FIN 包,發出確認包ACK,並帶上自己的序號,服務端進入CLOSE_WAIT 狀態。這時候客戶端已經沒有資料要發給服務端了,但是服務端如果有資料要發給客戶端,客戶端還是需要接收。用戶端收到ACK 後進入FIN_WAIT_2 狀態
3、服務端資料傳送完畢後,向客戶端發送FIN 包,此時伺服器進入LAST_ACK 狀態
4、客戶端收到FIN包發出確認包ACK ,此時客戶端進入TIME_WAIT 狀態,等待2 MSL 後進入CLOSED 狀態;服務端接收到客戶端的ACK 後就進入CLOSED 狀態了。
對於四次揮手,因為TCP 是全雙工通信,在主動關閉方發送FIN 包後,接收端可能還要發送數據,不能立即關閉伺服器端到客戶端的數據通道,所以也就無法將伺服器端的FIN 套件與對客戶端的ACK 套件合併發送,只能先確認ACK,然後伺服器待無需發送資料時再發送FIN 包,所以四次揮手時必須是四次資料包的互動
Content-length 是 http 訊息長度,用十進位數字表示的位元組的數目。
如果content-length > 實際長度,服務端/客戶端讀取到訊息隊尾時會繼續等待下一個字節,會出現無回應逾時的情況
如果content -length < 實際長度,首次要求的訊息會被截取,然後會導致後續的資料解析混亂。
當不確定content-length的值應該使用Transfer-Encoding: chunked,能夠將需要傳回的資料分成多個資料區塊,直到傳回長度為0 的終止區塊
什麼是跨域?
協議網域連接埠號碼皆相同時則為同域,任一個不同則為跨域
解決方案
##1、傳統的jsonp:利用

























